Apache Pig 简明教程
Apache Pig - Installation
本章说明了如何下载、安装和在您的系统中设置 Apache Pig 。
This chapter explains the how to download, install, and set up Apache Pig in your system.
Prerequisites
在使用 Apache Pig 之前,您必须在自己的系统上安装 Hadoop 和 Java 至关重要。因此,在安装 Apache Pig 之前,请按照以下链接中给出的步骤安装 Hadoop 和 Java −
It is essential that you have Hadoop and Java installed on your system before you go for Apache Pig. Therefore, prior to installing Apache Pig, install Hadoop and Java by following the steps given in the following link −
Download Apache Pig
首先,从以下网站下载 Apache Pig 的最新版本 − https://pig.apache.org/
First of all, download the latest version of Apache Pig from the following website − https://pig.apache.org/
Step 1
打开 Apache Pig 网站的主页。在 News, 部分中,单击链接 release page ,如下面的快照所示。
Open the homepage of Apache Pig website. Under the section News, click on the link release page as shown in the following snapshot.
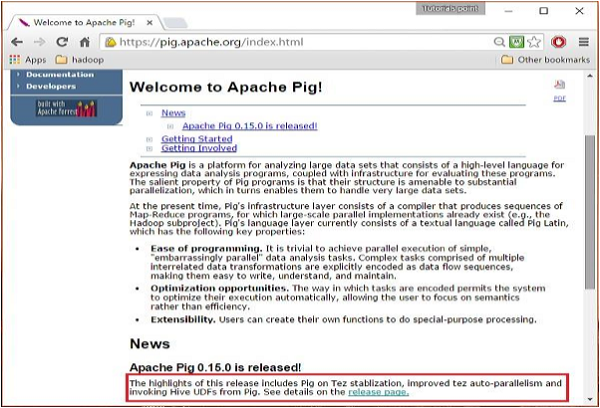
Step 2
单击指定的链接后,您将被重定向到 Apache Pig Releases 页面。在此页面上,在 Download 部分下,您将有两个链接,即 Pig 0.8 and later 和 Pig 0.7 and before 。单击链接 Pig 0.8 and later ,然后您将被重定向到具有镜像集的页面。
On clicking the specified link, you will be redirected to the Apache Pig Releases page. On this page, under the Download section, you will have two links, namely, Pig 0.8 and later and Pig 0.7 and before. Click on the link Pig 0.8 and later, then you will be redirected to the page having a set of mirrors.
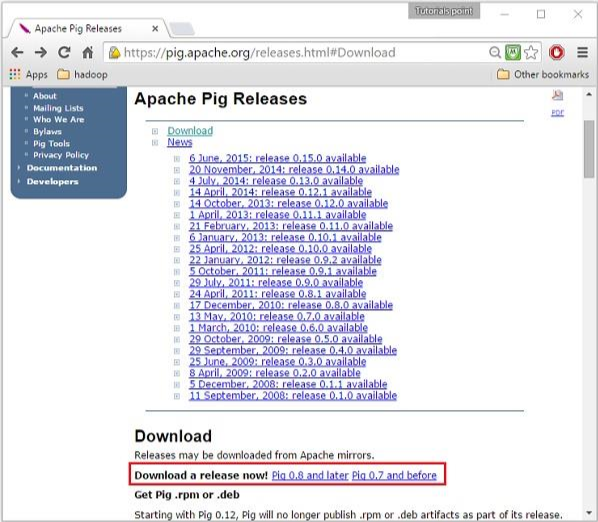

Step 4
这些镜像会将您带到 Pig Releases 页面。此页面包含各种版本的 Apache Pig。单击它们中的最新版本。
These mirrors will take you to the Pig Releases page. This page contains various versions of Apache Pig. Click the latest version among them.
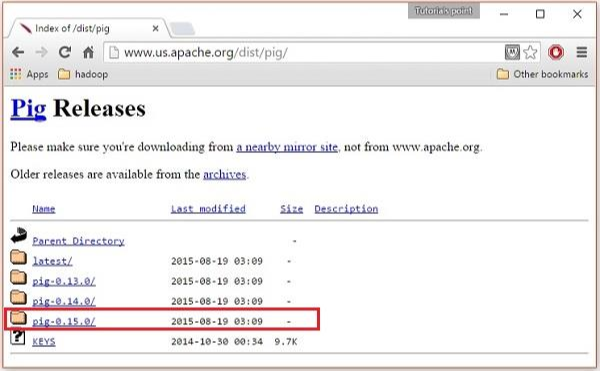
Step 5
在这些文件夹中,您将在各种发行版中拥有 Apache Pig 的源文件和二进制文件。下载 Apache Pig 0.15、 pig0.15.0-src.tar.gz 和 pig-0.15.0.tar.gz. 的源文件和二进制文件的 tar 文件
Within these folders, you will have the source and binary files of Apache Pig in various distributions. Download the tar files of the source and binary files of Apache Pig 0.15, pig0.15.0-src.tar.gz and pig-0.15.0.tar.gz.

Install Apache Pig
下载 Apache Pig 软件后,请按照以下给定的步骤在 Linux 环境中安装它。
After downloading the Apache Pig software, install it in your Linux environment by following the steps given below.
Step 1
在安装 Hadoop, Java, 和其他软件的安装目录所在的同一目录中创建一个名为 Pig 的目录。(在我们的教程中,我们在名为 Hadoop 的用户中创建了 Pig 目录)。
Create a directory with the name Pig in the same directory where the installation directories of Hadoop, Java, and other software were installed. (In our tutorial, we have created the Pig directory in the user named Hadoop).
$ mkdir PigConfigure Apache Pig
安装 Apache Pig 后,我们必须配置它。要配置,我们需要编辑两个文件 − bashrc and pig.properties 。
After installing Apache Pig, we have to configure it. To configure, we need to edit two files − bashrc and pig.properties.
.bashrc file
在 .bashrc 文件中,设置以下变量 −
In the .bashrc file, set the following variables −
-
PIG_HOME folder to the Apache Pig’s installation folder,
-
PATH environment variable to the bin folder, and
-
PIG_CLASSPATH environment variable to the etc (configuration) folder of your Hadoop installations (the directory that contains the core-site.xml, hdfs-site.xml and mapred-site.xml files).
export PIG_HOME = /home/Hadoop/Pig
export PATH = $PATH:/home/Hadoop/pig/bin
export PIG_CLASSPATH = $HADOOP_HOME/confpig.properties file
在 Pig 的 conf 文件夹中,有一个名为 pig.properties 的文件。在 pig.properties 文件中,您可以按照下面给出的方式,设置各种参数。
In the conf folder of Pig, we have a file named pig.properties. In the pig.properties file, you can set various parameters as given below.
pig -h properties支持以下属性 −
The following properties are supported −
Logging: verbose = true|false; default is false. This property is the same as -v
switch brief=true|false; default is false. This property is the same
as -b switch debug=OFF|ERROR|WARN|INFO|DEBUG; default is INFO.
This property is the same as -d switch aggregate.warning = true|false; default is true.
If true, prints count of warnings of each type rather than logging each warning.
Performance tuning: pig.cachedbag.memusage=<mem fraction>; default is 0.2 (20% of all memory).
Note that this memory is shared across all large bags used by the application.
pig.skewedjoin.reduce.memusagea=<mem fraction>; default is 0.3 (30% of all memory).
Specifies the fraction of heap available for the reducer to perform the join.
pig.exec.nocombiner = true|false; default is false.
Only disable combiner as a temporary workaround for problems.
opt.multiquery = true|false; multiquery is on by default.
Only disable multiquery as a temporary workaround for problems.
opt.fetch=true|false; fetch is on by default.
Scripts containing Filter, Foreach, Limit, Stream, and Union can be dumped without MR jobs.
pig.tmpfilecompression = true|false; compression is off by default.
Determines whether output of intermediate jobs is compressed.
pig.tmpfilecompression.codec = lzo|gzip; default is gzip.
Used in conjunction with pig.tmpfilecompression. Defines compression type.
pig.noSplitCombination = true|false. Split combination is on by default.
Determines if multiple small files are combined into a single map.
pig.exec.mapPartAgg = true|false. Default is false.
Determines if partial aggregation is done within map phase, before records are sent to combiner.
pig.exec.mapPartAgg.minReduction=<min aggregation factor>. Default is 10.
If the in-map partial aggregation does not reduce the output num records by this factor, it gets disabled.
Miscellaneous: exectype = mapreduce|tez|local; default is mapreduce. This property is the same as -x switch
pig.additional.jars.uris=<comma seperated list of jars>. Used in place of register command.
udf.import.list=<comma seperated list of imports>. Used to avoid package names in UDF.
stop.on.failure = true|false; default is false. Set to true to terminate on the first error.
pig.datetime.default.tz=<UTC time offset>. e.g. +08:00. Default is the default timezone of the host.
Determines the timezone used to handle datetime datatype and UDFs.
Additionally, any Hadoop property can be specified.Verifying the Installation
通过输入版本命令,来验证 Apache Pig 的安装。如果安装成功,那么您将获得 Apache Pig 的版本,如下所示。
Verify the installation of Apache Pig by typing the version command. If the installation is successful, you will get the version of Apache Pig as shown below.
$ pig –version
Apache Pig version 0.15.0 (r1682971)
compiled Jun 01 2015, 11:44:35