Microsoft Cognitive Toolkit 简明教程
CNTK - Classification Model
本章将帮助您了解如何衡量 CNTK 中分类模型的性能。让我们从混淆矩阵开始。
This chapter will help you to understand how to measure performance of classification model in CNTK. Let us begin with confusion matrix.
Confusion matrix
混淆矩阵 - 一个表,预测输出与预期输出相对比,这是衡量分类问题性能最简单的方法,其中输出可以是两种或更多类型的类别。
Confusion matrix - a table with the predicted output versus the expected output is the easiest way to measure the performance of a classification problem, where the output can be of two or more type of classes.
为了了解它的工作原理,我们将创建一个用于二进制分类模型的混淆矩阵,该模型预测信用卡交易是正常的还是欺诈的。它显示如下 −
In order to understand how it works, we are going to create a confusion matrix for a binary classification model that predicts, whether a credit card transaction was normal or a fraud. It is shown as follows −
Actual fraud |
Actual normal |
|
Predicted fraud |
True positive |
False positive |
Predicted normal |
False negative |
True negative |
जैसा कि हम देख सकते हैं, ऊपर दिए गए नमूना भ्रम मैट्रिक्स में 2 कॉलम हैं, एक वर्ग धोखाधड़ी के लिए और दूसरा वर्ग सामान्य के लिए। उसी तरह हमारे पास 2 पंक्तियाँ हैं, एक वर्ग धोखाधड़ी के लिए जोड़ी गई है और दूसरी वर्ग सामान्य के लिए जोड़ी गई है। निम्नलिखित भ्रम मैट्रिक्स से जुड़े शब्दों की व्याख्या है −
As we can see, the above sample confusion matrix contains 2 columns, one for class fraud and other for class normal. In the same way we have 2 rows, one is added for class fraud and other is added for class normal. Following is the explanation of the terms associated with confusion matrix −
-
* True Positives* − When both actual class & predicted class of data point is 1.
-
* True Negatives* − When both actual class & predicted class of data point is 0.
-
* False Positives* − When actual class of data point is 0 & predicted class of data point is 1.
-
* False Negatives* − When actual class of data point is 1 & predicted class of data point is 0.
让我们看看,如何从混淆矩阵中计算出不同事项的数量 −
Let’s see, how we can calculate number of different things from the confusion matrix −
-
Accuracy − It is the number of correct predictions made by our ML classification model. It can be calculated with the help of following formula −
-
Precision −It tells us how many samples were correctly predicted out of all samples we predicted. It can be calculated with the help of following formula −
-
Recall or Sensitivity − Recall are the number of positives returned by our ML classification model. In other words, it tells us how many of the fraud cases in the dataset were actually detected by the model. It can be calculated with the help of following formula −
-
Specificity − Opposite to recall, it gives the number of negatives returned by our ML classification model. It can be calculated with the help of following formula −
F-measure
我们可以将 F 度量作为混淆矩阵的替代方法。这样的主要原因是,我们无法同时使召回率和精确率最大化。这些指标之间存在着非常牢固的关系,这可以通过以下示例了解 −
We can use F-measure as an alternative of Confusion matrix. The main reason behind this, we can’t maximize Recall and Precision at the same time. There is a very strong relationship between these metrics and that can be understood with the help of following example −
假设,我们要使用 DL 模型将细胞样本分类为癌性或正常。这里,为了达到最高的精确率,我们需要将预测数减少到 1。尽管这可以使我们达到约 100% 的精确率,但召回率将变得非常低。
Suppose, we want to use a DL model to classify cell samples as cancerous or normal. Here, to reach maximum precision we need to reduce the number of predictions to 1. Although, this can give us reach around 100 percent precision, but recall will become really low.
另一方面,如果我们想要达到最大的召回率,我们需要进行尽可能多的预测。虽然这可以使我们的召回率达到约 100%,但精确率将变得非常低。
On the other hand, if we would like to reach maximum recall, we need to make as many predictions as possible. Although, this can give us reach around 100 percent recall, but precision will become really low.
在实践中,我们需要找到一种在精确率和召回率之间取得平衡的方法。F 度量指标允许我们这样做,因为它表示精确率和召回率之间的调和平均。
In practice, we need to find a way balancing between precision and recall. The F-measure metric allows us to do so, as it expresses a harmonic average between precision and recall.
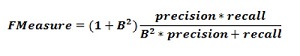
该公式被称为 F1 度量,其中称作 B 的额外项设置为 1,以得到精确率和召回率的相同样比。为了强调召回率,我们可以将因子 B 设置为 2。另一方面,为了强调精确率,我们可以将因子 B 设置为 0.5。
This formula is called the F1-measure, where the extra term called B is set to 1 to get an equal ratio of precision and recall. In order to emphasize recall, we can set the factor B to 2. On the other hand, to emphasize precision, we can set the factor B to 0.5.
Using CNTK to measure classification performance
在上一节中,我们已经使用 Iris 花数据集创建了一个分类模型。在此,我们将使用混淆矩阵和 F 度量指标来衡量其性能。
In previous section we have created a classification model using Iris flower dataset. Here, we will be measuring its performance by using confusion matrix and F-measure metric.
Creating Confusion matrix
我们已经创建了该模型,所以我们可以开始对模型进行验证过程,该过程包括 confusion matrix 。首先,我们将使用 scikit-learn 中的 confusion_matrix 函数创建混淆矩阵。为此,我们需要我们的测试样本的真实标签和相同测试样本的预测标签。
We already created the model, so we can start the validating process, which includes confusion matrix, on the same. First, we are going to create confusion matrix with the help of the confusion_matrix function from scikit-learn. For this, we need the real labels for our test samples and the predicted labels for the same test samples.
让我们使用以下 python 代码来计算混淆矩阵 −
Let’s calculate the confusion matrix by using following python code −
from sklearn.metrics import confusion_matrix
y_true = np.argmax(y_test, axis=1)
y_pred = np.argmax(z(X_test), axis=1)
matrix = confusion_matrix(y_true=y_true, y_pred=y_pred)
print(matrix)Output
[[10 0 0]
[ 0 1 9]
[ 0 0 10]]我们还可以使用热图函数以如下方式将混淆矩阵可视化 −
We can also use heatmap function to visualise a confusion matrix as follows −
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.heatmap(matrix,
annot=True,
xticklabels=label_encoder.classes_.tolist(),
yticklabels=label_encoder.classes_.tolist(),
cmap='Blues')
g.set_yticklabels(g.get_yticklabels(), rotation=0)
plt.show()
我们还应该有一个单一的性能数字,我们可以使用它来比较模型。为此,我们需要使用 CNTK 中指标包中的 classification_error 函数来计算分类错误,就像在创建分类模型时所做的那样。
We should also have a single performance number, that we can use to compare the model. For this, we need to calculate the classification error by using classification_error function, from the metrics package in CNTK as done while creating classification model.
现在,要来计算分类错误,请使用数据集中带有损失函数的测试方法。之后,CNTK 会将我们提供给该函数作为输入的样本作为输入,并根据输入特征 X_*test* 做出预测。
Now to calculate the classification error, execute the test method on the loss function with a dataset. After that, CNTK will take the samples we provided as input for this function and make a prediction based on input features X_*test*.
loss.test([X_test, y_test])Implementing F-Measures
为了实现 F 度量,CNTK 还包括一个名为 fmeasures 的函数。我们在通过训练 NN 时可以将单元格 cntk.metrics.classification_error 替换为对 cntk.losses.fmeasure 的调用,在定义准则工厂函数时使用如下方式 −
For implementing F-Measures, CNTK also includes function called fmeasures. We can use this function, while training the NN by replacing the cell cntk.metrics.classification_error, with a call to cntk.losses.fmeasure when defining the criterion factory function as follows −
import cntk
@cntk.Function
def criterion_factory(output, target):
loss = cntk.losses.cross_entropy_with_softmax(output, target)
metric = cntk.losses.fmeasure(output, target)
return loss, metric在使用 cntk.losses.fmeasure 函数后,我们将获得如下所示的 loss.test 方法调用的不同输出 −
After using cntk.losses.fmeasure function, we will get different output for the loss.test method call given as follows −
loss.test([X_test, y_test])