Hibernate ORM 中文操作指南
1. Introduction
Hibernate 通常被描述为一个库,它可以轻松地将 Java 类映射到关系数据库表。但这并不能说明关系数据本身所扮演的核心角色。因此,更准确的描述可能是:
Hibernate is usually described as a library that makes it easy to map Java classes to relational database tables. But this formulation does no justice to the central role played by the relational data itself. So a better description might be:
这里,重点是关系数据以及类型安全的重要性。object/relational mapping(ORM)的目标是消除脆弱且不类型安全的代码,并从长远来看,使大型程序更容易维护。
Here the relational data is the focus, along with the importance of typesafety. The goal of object/relational mapping (ORM) is to eliminate fragile and untypesafe code, and make large programs easier to maintain in the long run.
ORM 通过解除开发人员编写单调、重复且脆弱的代码以将对象图扁平化至数据库表并将对象图从平面 SQL 查询结果集重建出来的需要,从而消除了持久化的痛苦。更好的是,ORM 使得在已编写基本持久化逻辑后,在今后调整性能更加容易。
ORM takes the pain out of persistence by relieving the developer of the need to hand-write tedious, repetitive, and fragile code for flattening graphs of objects to database tables and rebuilding graphs of objects from flat SQL query result sets. Even better, ORM makes it much easier to tune performance later, after the basic persistence logic has already been written.
|
一个常年的问题是:我应该使用 ORM 还是纯 SQL?答案通常是:use both。JPA 和 Hibernate 被设计为可以处理 in conjunction with 手写 SQL。您会看到,大多数具有复杂数据访问逻辑的程序都会受益于使用 ORM,至少 @{10}。但是,如果 Hibernate 使事情变得更加困难,对于某些特别棘手的数据访问逻辑,唯一明智的做法就是使用更适合该问题的解决方案!仅仅因为您正在使用 Hibernate 进行持久化并不意味着您必须将其用于 @{11}。 |
|
A perennial question is: should I use ORM, or plain SQL? The answer is usually: use both. JPA and Hibernate were designed to work in conjunction with handwritten SQL. You see, most programs with nontrivial data access logic will benefit from the use of ORM at least somewhere. But if Hibernate is making things more difficult, for some particularly tricky piece of data access logic, the only sensible thing to do is to use something better suited to the problem! Just because you’re using Hibernate for persistence doesn’t mean you have to use it for everything. |
开发人员经常询问 Hibernate 与 JPA 之间的关系,因此让我们简要回顾一下历史。
Developers often ask about the relationship between Hibernate and JPA, so let’s take a short detour into some history.
1.1. Hibernate and JPA
Hibernate 是 Java 持久性 API(现在是 Jakarta)Persistence API(或 JPA)背后的灵感,并且包含了该规范的最新版本的完整实现。
Hibernate was the inspiration behind the Java (now Jakarta) Persistence API, or JPA, and includes a complete implementation of the latest revision of this specification.
我们可以从三个基本要素的角度来考虑 Hibernate 的 API:
We can think of the API of Hibernate in terms of three basic elements:
-
an implementation of the JPA-defined APIs, most importantly, of the interfaces EntityManagerFactory and EntityManager, and of the JPA-defined O/R mapping annotations,
-
a native API exposing the full set of available functionality, centered around the interfaces SessionFactory, which extends EntityManagerFactory, and Session, which extends EntityManager, and
-
a set of mapping annotations which augment the O/R mapping annotations defined by JPA, and which may be used with the JPA-defined interfaces, or with the native API.
Hibernate 还为扩展或集成 Hibernate 的框架和库提供了一系列 SPI,但我们这里对这些东西都不感兴趣。
Hibernate also offers a range of SPIs for frameworks and libraries which extend or integrate with Hibernate, but we’re not interested in any of that stuff here.
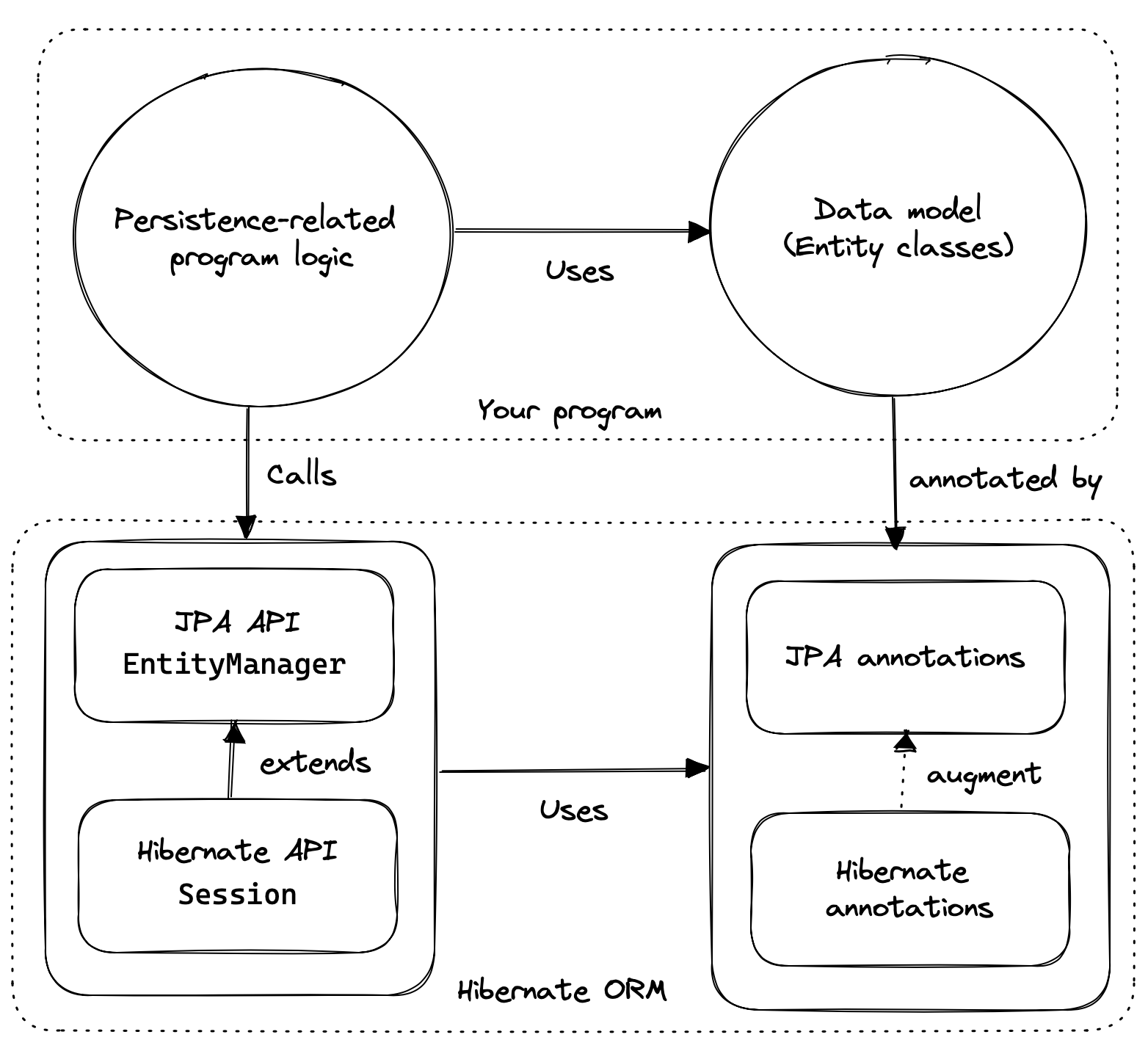
作为应用程序开发人员,您必须决定:
As an application developer, you must decide whether to:
-
write your program in terms of Session and SessionFactory, or
-
maximize portability to other implementations of JPA by, wherever reasonable, writing code in terms of EntityManager and EntityManagerFactory, falling back to the native APIs only where necessary.
无论您采用哪种路径,大多数情况下都将使用 JPA 定义的映射注解,而对于更高级的映射问题则使用 Hibernate 定义的注解。
Whichever path you take, you will use the JPA-defined mapping annotations most of the time, and the Hibernate-defined annotations for more advanced mapping problems.
|
您可能会想,使用 only JPA 定义的 API 来开发应用程序是否可行,事实上从理论上是可行的。JPA 非常出色,它确实抓住了对象/关系映射问题的基本原理。但是,如果没有本机 API 和扩展映射注释,您将错过 Hibernate 的很多强大功能。 |
|
You might wonder if it’s possible to develop an application using only JPA-defined APIs, and, indeed, that’s possible in principle. JPA is a great baseline that really nails the basics of the object/relational mapping problem. But without the native APIs, and extended mapping annotations, you miss out on much of the power of Hibernate. |
由于 Hibernate 早于 JPA 存在,并且由于 JPA 是基于 Hibernate 建模的,因此我们在标准 API 和原生 API 之间的命名中不幸遇到了一些竞争和重复。例如:
Since Hibernate existed before JPA, and since JPA was modelled on Hibernate, we unfortunately have some competition and duplication in naming between the standard and native APIs. For example:
表 1. 具有相似命名方式的竞争 API 示例
Table 1. Examples of competing APIs with similar naming
Hibernate |
JPA |
org.hibernate.annotations.CascadeType |
javax.persistence.CascadeType |
org.hibernate.FlushMode |
javax.persistence.FlushModeType |
org.hibernate.annotations.FetchMode |
javax.persistence.FetchType |
org.hibernate.query.Query |
javax.persistence.Query |
org.hibernate.Cache |
javax.persistence.Cache |
@org.hibernate.annotations.NamedQuery |
@javax.persistence.NamedQuery |
@org.hibernate.annotations.Cache |
@javax.persistence.Cacheable |
通常,与 JPA 相比,原生的 Hibernate API 提供了一点额外的功能,因此这并不完全是 flaw。但这需要注意。
Typically, the Hibernate-native APIs offer something a little extra that’s missing in JPA, so this isn’t exactly a flaw. But it’s something to watch out for.
1.2. Writing Java code with Hibernate
如果您完全不了解 Hibernate 和 JPA,您可能已经在思考与持久性相关的代码如何构建。
If you’re completely new to Hibernate and JPA, you might already be wondering how the persistence-related code is structured.
嗯,通常情况下,我们的与持久性相关的代码有以下两个层:
Well, typically, our persistence-related code comes in two layers:
-
a representation of our data model in Java, which takes the form of a set of annotated entity classes, and
-
a larger number of functions which interact with Hibernate’s APIs to perform the persistence operations associated with your various transactions.
第一部分,即数据或“域”模型,通常更容易编写,但是出色地、干净利落地完成这项工作会极大地影响您在第二部分的成功。
The first part, the data or "domain" model, is usually easier to write, but doing a great and very clean job of it will strongly affect your success in the second part.
大多数人都将域模型实现为我们过去称之为“普通旧 Java 对象”的一组,即作为简单的 Java 类,没有对技术基础设施或应用程序逻辑的直接依赖,并且不处理请求处理、事务管理、通信或与数据库的交互。
Most people implement the domain model as a set of what we used to call "Plain Old Java Objects", that is, as simple Java classes with no direct dependencies on technical infrastructure, nor on application logic which deals with request processing, transaction management, communications, or interaction with the database.
|
花时间研究此代码,并尝试生成一个与关系数据模型尽可能接近、合理化的 Java 模型。避免使用稀奇或高级的映射功能(如果真的不需要的话)。当有丝毫疑问时,使用 @ManyToOne 优先于 @OneToMany(mappedBy=…) 映射外键关系,以获得更复杂的关联映射。 |
|
Take your time with this code, and try to produce a Java model that’s as close as reasonable to the relational data model. Avoid using exotic or advanced mapping features when they’re not really needed. When in the slightest doubt, map a foreign key relationship using @ManyToOne with @OneToMany(mappedBy=…) in preference to more complicated association mappings. |
代码的第二部分更难正确编写。此代码必须:
The second part of the code is much trickier to get right. This code must:
-
manage transactions and sessions,
-
interact with the database via the Hibernate session,
-
fetch and prepare data needed by the UI, and
-
handle failures.
最好在某种框架代码中处理事务和会话管理,以及某些故障类型的恢复。
|
Responsibility for transaction and session management, and for recovery from certain kinds of failure, is best handled in some sort of framework code. |
我们正在 come back soon 一个关于此持久性逻辑应该如何组织、以及如何适应系统其余部分的棘手问题。
We’re going to come back soon to the thorny question of how this persistence logic should be organized, and how it should fit into the rest of the system.
1.3. Hello, Hibernate
在我们深入探讨这些问题之前,我们将快速提供一个基本的示例程序,如果您尚未将 Hibernate 集成到您的项目中,这将帮助您快速入门。
Before we get deeper into the weeds, we’ll quickly present a basic example program that will help you get started if you don’t already have Hibernate integrated into your project.
我们从一个简单的 gradle 构建文件开始:
We begin with a simple gradle build file:
plugins {
id 'java'
}
group = 'org.example'
version = '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
// the GOAT ORM
implementation 'org.hibernate.orm:hibernate-core:7.0.0.Beta1'
// Hibernate Validator
implementation 'org.hibernate.validator:hibernate-validator:8.0.0.Final'
implementation 'org.glassfish:jakarta.el:4.0.2'
// Agroal connection pool
implementation 'org.hibernate.orm:hibernate-agroal:7.0.0.Beta1'
implementation 'io.agroal:agroal-pool:2.1'
// logging via Log4j
implementation 'org.apache.logging.log4j:log4j-core:2.20.0'
// JPA Metamodel Generator
annotationProcessor 'org.hibernate.orm:hibernate-processor:7.0.0.Beta1'
// Compile-time checking for HQL
//implementation 'org.hibernate:query-validator:2.0-SNAPSHOT'
//annotationProcessor 'org.hibernate:query-validator:2.0-SNAPSHOT'
// H2 database
runtimeOnly 'com.h2database:h2:2.1.214'
}其中,只有第一个依赖项对运行 Hibernate 是绝对 required。
Only the first of these dependencies is absolutely required to run Hibernate.
接下来,我们将为 log4j 添加一个日志记录配置文件:
Next, we’ll add a logging configuration file for log4j:
rootLogger.level = info
rootLogger.appenderRefs = console
rootLogger.appenderRef.console.ref = console
logger.hibernate.name = org.hibernate.SQL
logger.hibernate.level = info
appender.console.name = console
appender.console.type = Console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %highlight{[%p]} %m%n现在我们需要一些 Java 代码。我们从 entity class 开始:
Now we need some Java code. We begin with our entity class:
package org.hibernate.example;
import jakarta.persistence.Entity;
import jakarta.persistence.Id;
import jakarta.validation.constraints.NotNull;
@Entity
class Book {
@Id
String isbn;
@NotNull
String title;
Book() {}
Book(String isbn, String title) {
this.isbn = isbn;
this.title = title;
}
}最后,让我们看看用于配置和实例化 Hibernate 并要求它持久化和查询实体的代码。如果现在您一头雾水,请不用担心。本书的目的是让所有这些内容一目了然。
Finally, let’s see code which configures and instantiates Hibernate and asks it to persist and query the entity. Don’t worry if this makes no sense at all right now. It’s the job of this Introduction to make all this crystal clear.
package org.hibernate.example;
import org.hibernate.cfg.Configuration;
import static java.lang.Boolean.TRUE;
import static java.lang.System.out;
import static org.hibernate.cfg.AvailableSettings.*;
public class Main {
public static void main(String[] args) {
var sessionFactory = new Configuration()
.addAnnotatedClass(Book.class)
// use H2 in-memory database
.setProperty(URL, "jdbc:h2:mem:db1")
.setProperty(USER, "sa")
.setProperty(PASS, "")
// use Agroal connection pool
.setProperty("hibernate.agroal.maxSize", 20)
// display SQL in console
.setProperty(SHOW_SQL, true)
.setProperty(FORMAT_SQL, true)
.setProperty(HIGHLIGHT_SQL, true)
.buildSessionFactory();
// export the inferred database schema
sessionFactory.getSchemaManager().exportMappedObjects(true);
// persist an entity
sessionFactory.inTransaction(session -> {
session.persist(new Book("9781932394153", "Hibernate in Action"));
});
// query data using HQL
sessionFactory.inSession(session -> {
out.println(session.createSelectionQuery("select isbn||': '||title from Book").getSingleResult());
});
// query data using criteria API
sessionFactory.inSession(session -> {
var builder = sessionFactory.getCriteriaBuilder();
var query = builder.createQuery(String.class);
var book = query.from(Book.class);
query.select(builder.concat(builder.concat(book.get(Book_.isbn), builder.literal(": ")),
book.get(Book_.title)));
out.println(session.createSelectionQuery(query).getSingleResult());
});
}
}在此处,我们使用了 Hibernate 的原生 API。我们可以使用 JPA 标准 API 实现相同的功能。
Here we’ve used Hibernate’s native APIs. We could have used JPA-standard APIs to achieve the same thing.
1.4. Hello, JPA
如果我们将自己局限于使用 JPA 标准 API,我们则需要使用 XML 来配置 Hibernate。
If we limit ourselves to the use of JPA-standard APIs, we need to use XML to configure Hibernate.
<persistence xmlns="https://jakarta.ee/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence https://jakarta.ee/xml/ns/persistence/persistence_3_0.xsd"
version="3.0">
<persistence-unit name="example">
<class>org.hibernate.example.Book</class>
<properties>
<!-- H2 in-memory database -->
<property name="jakarta.persistence.jdbc.url"
value="jdbc:h2:mem:db1"/>
<!-- Credentials -->
<property name="jakarta.persistence.jdbc.user"
value="sa"/>
<property name="jakarta.persistence.jdbc.password"
value=""/>
<!-- Agroal connection pool -->
<property name="hibernate.agroal.maxSize"
value="20"/>
<!-- display SQL in console -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.highlight_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>请注意,我们的 build.gradle 和 log4j2.properties 文件没有更改。
Note that our build.gradle and log4j2.properties files are unchanged.
我们的实体类也没有任何改动。
Our entity class is also unchanged from what we had before.
遗憾的是,JPA 并未提供 inSession() 方法,所以我们必须自己实现会话和事务管理。我们可以将该逻辑放在我们自己的 inSession() 函数中,以避免为每个事务重复该逻辑。同理,您也不需要立刻理解这段代码。
Unfortunately, JPA doesn’t offer an inSession() method, so we’ll have to implement session and transaction management ourselves. We can put that logic in our own inSession() function, so that we don’t have to repeat it for every transaction. Again, you don’t need to understand any of this code right now.
package org.hibernate.example;
import jakarta.persistence.EntityManager;
import jakarta.persistence.EntityManagerFactory;
import java.util.Map;
import java.util.function.Consumer;
import static jakarta.persistence.Persistence.createEntityManagerFactory;
import static java.lang.System.out;
import static org.hibernate.cfg.AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION;
import static org.hibernate.tool.schema.Action.CREATE;
public class Main {
public static void main(String[] args) {
var factory = createEntityManagerFactory("example",
// export the inferred database schema
Map.of(JAKARTA_HBM2DDL_DATABASE_ACTION, CREATE));
// persist an entity
inSession(factory, entityManager -> {
entityManager.persist(new Book("9781932394153", "Hibernate in Action"));
});
// query data using HQL
inSession(factory, entityManager -> {
out.println(entityManager.createQuery("select isbn||': '||title from Book").getSingleResult());
});
// query data using criteria API
inSession(factory, entityManager -> {
var builder = factory.getCriteriaBuilder();
var query = builder.createQuery(String.class);
var book = query.from(Book.class);
query.select(builder.concat(builder.concat(book.get(Book_.isbn), builder.literal(": ")),
book.get(Book_.title)));
out.println(entityManager.createQuery(query).getSingleResult());
});
}
// do some work in a session, performing correct transaction management
static void inSession(EntityManagerFactory factory, Consumer<EntityManager> work) {
var entityManager = factory.createEntityManager();
var transaction = entityManager.getTransaction();
try {
transaction.begin();
work.accept(entityManager);
transaction.commit();
}
catch (Exception e) {
if (transaction.isActive()) transaction.rollback();
throw e;
}
finally {
entityManager.close();
}
}
}实际上,我们从未直接从 main() 方法访问数据库。接下来谈谈如何在一个真实系统中组织持久性逻辑。本章节的其余内容不是强制的。如果您渴望了解有关 Hibernate 本身的更多详细信息,非常欢迎您直接跳到 next chapter,稍后再回来。
In practice, we never access the database directly from a main() method. So now let’s talk about how to organize persistence logic in a real system. The rest of this chapter is not compulsory. If you’re itching for more details about Hibernate itself, you’re quite welcome to skip straight to the next chapter, and come back later.
1.5. Organizing persistence logic
在真实的程序中,如上面所示的代码这样的持久化逻辑通常会与其他类型的代码交织在一起,包括逻辑:
In a real program, persistence logic like the code shown above is usually interleaved with other sorts of code, including logic:
-
implementing the rules of the business domain, or
-
for interacting with the user.
因此,许多开发人员很快就会——甚至 too quickly,我们认为——找到方法将持久化逻辑隔离到某种单独的架构层中。我们建议您暂时抑制这种冲动。
Therefore, many developers quickly—even too quickly, in our opinion—reach for ways to isolate the persistence logic into some sort of separate architectural layer. We’re going to ask you to suppress this urge for now.
|
使用 Hibernate 的 easiest 方式是直接调用 Session 或 EntityManager。如果您不熟悉 Hibernate,那么包含 JPA 的框架只会让您的生活变得更困难。 |
|
The easiest way to use Hibernate is to call the Session or EntityManager directly. If you’re new to Hibernate, frameworks which wrap JPA are only going to make your life more difficult. |
我们更喜欢 bottom-up 方法来组织我们的代码。我们喜欢先考虑方法和函数,而不是考虑架构层和容器管理的对象。为了说明我们提倡的代码组织方法,让我们考虑一个使用 HQL 或 SQL 查询数据库的服务。
We prefer a bottom-up approach to organizing our code. We like to start thinking about methods and functions, not about architectural layers and container-managed objects. To illustrate the sort of approach to code organization that we advocate, let’s consider a service which queries the database using HQL or SQL.
我们可能会从类似这样、UI 和持久化逻辑混合的东西开始:
We might start with something like this, a mix of UI and persistence logic:
@Path("/") @Produces("application/json")
public class BookResource {
@GET @Path("book/{isbn}")
public Book getBook(String isbn) {
var book = sessionFactory.fromTransaction(session -> session.find(Book.class, isbn));
return book == null ? Response.status(404).build() : book;
}
}事实上,我们也可能会 finish 类似这样的东西——很难具体找出上面代码的任何问题,并且对于这样简单的案例,通过引入其他对象来让这段代码更复杂似乎真的很困难。
Indeed, we might also finish with something like that—it’s quite hard to identify anything concretely wrong with the code above, and for such a simple case it seems really difficult to justify making this code more complicated by introducing additional objects.
我们希望引起你注意的是,此代码的一个非常好的方面是,会话和事务管理是由通用的“框架”代码处理的,正如我们上面已经建议的那样。在本例中,我们使用 fromTransaction() 方法,它恰好是 Hibernate 中内置的。但是,你可能更喜欢使用其他内容,例如:
One very nice aspect of this code, which we wish to draw your attention to, is that session and transaction management is handled by generic "framework" code, just as we already recommended above. In this case, we’re using the fromTransaction() method, which happens to come built in to Hibernate. But you might prefer to use something else, for example:
-
in a container environment like Jakarta EE or Quarkus, container-managed transactions and container-managed persistence contexts, or
-
something you write yourself.
重要的是,像 createEntityManager() 和 getTransaction().begin() 这样的调用不属于常规程序逻辑,因为正确执行错误处理很棘手且很乏味。
The important thing is that calls like createEntityManager() and getTransaction().begin() don’t belong in regular program logic, because it’s tricky and tedious to get the error handling correct.
现在让我们考虑一个稍微复杂一点的情况。
Let’s now consider a slightly more complicated case.
@Path("/") @Produces("application/json")
public class BookResource {
private static final RESULTS_PER_PAGE = 20;
@GET @Path("books/{titlePattern}/{page:\\d+}")
public List<Book> findBooks(String titlePattern, int page) {
var books = sessionFactory.fromTransaction(session -> {
return session.createSelectionQuery("from Book where title like ?1 order by title", Book.class)
.setParameter(1, titlePattern)
.setPage(Page.page(RESULTS_PER_PAGE, page))
.getResultList();
});
return books.isEmpty() ? Response.status(404).build() : books;
}
}这很好,如果您希望将代码保持原样,我们也不会抱怨。但有一件事我们也许可以改进。我们喜欢具有单一职责的超短方法,并且这里似乎有机会介绍一个这样的方法。让我们使用我们最喜欢的方法,Extract Method 重构,来处理代码。我们得到:
This is fine, and we won’t complain if you prefer to leave the code exactly as it appears above. But there’s one thing we could perhaps improve. We love super-short methods with single responsibilities, and there looks to be an opportunity to introduce one here. Let’s hit the code with our favorite thing, the Extract Method refactoring. We obtain:
static List<Book> findBooksByTitleWithPagination(Session session,
String titlePattern, Page page) {
return session.createSelectionQuery("from Book where title like ?1 order by title", Book.class)
.setParameter(1, titlePattern)
.setPage(page)
.getResultList();
}这是一个 query method 的示例,这是一个接受 HQL 或 SQL 查询参数为参数的函数,并执行查询,将其结果返回给调用方。这就是它的全部功能;它不协调附加的程序逻辑,也不执行事务或会话管理。
This is an example of a query method, a function which accepts arguments to the parameters of a HQL or SQL query, and executes the query, returning its results to the caller. And that’s all it does; it doesn’t orchestrate additional program logic, and it doesn’t perform transaction or session management.
使用 @NamedQuery 注解指定查询字符串会更好,这样 Hibernate 可以在启动时验证此查询,也就是在创建 SessionFactory 时,而不是在初次执行查询时进行验证。事实上,由于我们在 Gradle build 中包括了 Metamodel Generator,因此甚至可以在 compile time 验证查询。
It’s even better to specify the query string using the @NamedQuery annotation, so that Hibernate can validate the query it at startup time, that is, when the SessionFactory is created, instead of when the query is first executed. Indeed, since we included the Metamodel Generator in our Gradle build, the query can even be validated at compile time.
我们需要一个放置注解的地方,所以让我们将查询方法移到一个新类中:
We need a place to put the annotation, so lets move our query method to a new class:
@CheckHQL // validate named queries at compile time
@NamedQuery(name="findBooksByTitle",
query="from Book where title like :title order by title")
class Queries {
static List<Book> findBooksByTitleWithPagination(Session session,
String titlePattern, Page page) {
return session.createNamedQuery("findBooksByTitle", Book.class)
.setParameter("title", titlePattern)
.setPage(page)
.getResultList();
}
}请注意,我们的查询方法不会试图向其客户端隐藏 EntityManager。事实上,客户端代码负责为查询方法提供 EntityManager 或 Session。这是我们整个方法的一个很特别的特征。
Notice that our query method doesn’t attempt to hide the EntityManager from its clients. Indeed, the client code is responsible for providing the EntityManager or Session to the query method. This is a quite distinctive feature of our whole approach.
客户端代码可能:
The client code may:
-
obtain an EntityManager or Session by calling inTransaction() or fromTransaction(), as we saw above, or,
-
in an environment with container-managed transactions, it might obtain it via dependency injection.
无论哪种情况,协调工作单元的代码通常只直接调用 Session 或 EntityManager,必要时将其传递给诸如我们的查询方法之类的帮助程序方法。
Whatever the case, the code which orchestrates a unit of work usually just calls the Session or EntityManager directly, passing it along to helper methods like our query method if necessary.
@GET
@Path("books/{titlePattern}")
public List<Book> findBooks(String titlePattern) {
var books = sessionFactory.fromTransaction(session ->
Queries.findBooksByTitleWithPagination(session, titlePattern,
Page.page(RESULTS_PER_PAGE, page));
return books.isEmpty() ? Response.status(404).build() : books;
}您可能认为我们的查询方法看起来有点像样板。也许是这样,但我们更担心它不是类型安全的。事实上,多年来,缺少对 HQL 查询和将参数绑定到查询参数的代码的编译时检查一直是我们对 Hibernate 不满的主要来源。
You might be thinking that our query method looks a bit boilerplatey. That’s true, perhaps, but we’re much more concerned that it’s not very typesafe. Indeed, for many years, the lack of compile-time checking for HQL queries and code which binds arguments to query parameters was our number one source of discomfort with Hibernate.
幸运的是,现在有两个问题的解决方案:作为 Hibernate 6.3 的一项孵化功能,我们现在提供让元模型生成器为您填充此类查询方法的实现的可能性。此功能是 a whole chapter of this introduction 的主题,所以现在我们只给您一个简单的例子。
Fortunately, there’s now a solution to both problems: as an incubating feature of Hibernate 6.3, we now offer the possibility to have the Metamodel Generator fill in the implementation of such query methods for you. This facility is the topic of a whole chapter of this introduction, so for now we’ll just leave you with one simple example.
假设我们将 Queries 简化为以下内容:
Suppose we simplify Queries to just the following:
interface Queries {
@HQL("where title like :title order by title")
List<Book> findBooksByTitleWithPagination(String title, Page page);
}那么 Metamodel Generator 会自动生成一个名为 Queries_ 的类中 @HQL 注释的方法的实现。我们可以像调用我们手写的版本一样调用它:
Then the Metamodel Generator automatically produces an implementation of the method annotated @HQL in a class named Queries_. We can call it just like we called our handwritten version:
@GET
@Path("books/{titlePattern}")
public List<Book> findBooks(String titlePattern) {
var books = sessionFactory.fromTransaction(session ->
Queries_.findBooksByTitleWithPagination(session, titlePattern,
Page.page(RESULTS_PER_PAGE, page));
return books.isEmpty() ? Response.status(404).build() : books;
}在这种情况下,消除的代码数量十分微不足道。真正有价值的是更高的类型安全性。我们现在在编译时便可找出查询参数赋值中的错误。
In this case, the quantity of code eliminated is pretty trivial. The real value is in improved type safety. We now find out about errors in assignments of arguments to query parameters at compile time.
|
在这一点上,我们确信你对此想法有很多疑问。这是理所当然的。我们很想在此处解答你的疑虑,但这会让我们偏离正轨。因此,我们要求你暂时将这些想法归档。我们保证在我们 properly address this topic later 时会让它讲得通。在那之后,如果你仍然不喜欢这种方法,请理解这是一项完全可选的操作。不会有人来你家强迫你接受。 |
|
At this point, we’re certain you’re full of doubts about this idea. And quite rightly so. We would love to answer your objections right here, but that will take us much too far off track. So we ask you to file away these thoughts for now. We promise to make it make sense when we properly address this topic later. And, after that, if you still don’t like this approach, please understand that it’s completely optional. Nobody’s going to come around to your house to force it down your throat. |
既然我们对持久性逻辑的样子有一个大概的了解,那么自然就会问我们应该如何测试代码。
Now that we have a rough picture of what our persistence logic might look like, it’s natural to ask how we should test our code.
1.6. Testing persistence logic
在为持久性逻辑编写测试时,我们将需要:
When we write tests for our persistence logic, we’re going to need:
-
a database, with
-
an instance of the schema mapped by our persistent entities, and
-
a set of test data, in a well-defined state at the beginning of each test.
显而易见,我们应该针对将在生产中使用的同一数据库系统进行测试,并且实际上我们肯定应该至少对此配置进行 some 测试。但是另一方面,执行 I/O 的测试比不执行 I/O 的测试要慢得多,而且大多数数据库都无法设置成在进程内运行。
It might seem obvious that we should test against the same database system that we’re going to use in production, and, indeed, we should certainly have at least some tests for this configuration. But on the other hand, tests which perform I/O are much slower than tests which don’t, and most databases can’t be set up to run in-process.
因此,由于使用 Hibernate 6 编写的持久化逻辑在数据库之间具有 extremely 可移植性,因此在内存 Java 数据库中进行测试通常是一个好主意。( H2 是我们推荐的。)
So, since most persistence logic written using Hibernate 6 is extremely portable between databases, it often makes good sense to test against an in-memory Java database. (H2 is the one we recommend.)
如果我们的持久性代码使用本机 SQL,或者如果它使用悲观锁之类的并发管理功能,则我们确实需要小心。
We do need to be careful here if our persistence code uses native SQL, or if it uses concurrency-management features like pessimistic locks.
无论我们是针对我们的真实数据库进行测试,还是针对内存中 Java 数据库进行测试,我们都需要在测试套件开始时导出模式。当我们创建 Hibernate SessionFactory 或 JPA EntityManager 时,我们 usually 这样做,所以传统上我们为此使用了 configuration property。
Whether we’re testing against our real database, or against an in-memory Java database, we’ll need to export the schema at the beginning of a test suite. We usually do this when we create the Hibernate SessionFactory or JPA EntityManager, and so traditionally we’ve used a configuration property for this.
JPA 标准属性是 jakarta.persistence.schema-generation.database.action。例如,如果使用 Configuration 来配置 Hibernate,我们可以编写:
The JPA-standard property is jakarta.persistence.schema-generation.database.action. For example, if we’re using Configuration to configure Hibernate, we could write:
configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION,
Action.SPEC_ACTION_DROP_AND_CREATE);或者,在 Hibernate 6 中,我们可以使用新的 SchemaManager API 来导出模式,就像我们执行 above 所做的那样。
Alternatively, in Hibernate 6, we may use the new SchemaManager API to export the schema, just as we did above.
sessionFactory.getSchemaManager().exportMappedObjects(true);由于在许多数据库上执行 DDL 语句非常慢,因此我们不会在每次测试前进行此操作。相反,为了确保每个测试都以明确定义的状态开始测试数据,我们需要在每次测试前做两件事:
Since executing DDL statements is very slow on many databases, we don’t want to do this before every test. Instead, to ensure that each test begins with the test data in a well-defined state, we need to do two things before each test:
-
clean up any mess left behind by the previous test, and then
-
reinitialize the test data.
我们可能会清空所有表,留下一个空的数据库模式,方法采用 SchemaManager。
We may truncate all the tables, leaving an empty database schema, using the SchemaManager.
sessionFactory.getSchemaManager().truncateMappedObjects();在清空表后,我们可能需要初始化测试数据。我们可以例如在 SQL 脚本中指定测试数据:
After truncating tables, we might need to initialize our test data. We may specify test data in a SQL script, for example:
. /import.sql
insert into Books (isbn, title) values ('9781932394153', 'Hibernate in Action')
insert into Books (isbn, title) values ('9781932394887', 'Java Persistence with Hibernate')
insert into Books (isbn, title) values ('9781617290459', 'Java Persistence with Hibernate, Second Edition')如果我们给这个文件命名为 import.sql,并把它放在根类路径中,这就完成了我们要做的。
If we name this file import.sql, and place it in the root classpath, that’s all we need to do.
否则,我们需要在 configuration property jakarta.persistence.sql-load-script-source 中指定文件。如果我们使用 Configuration 来配置 Hibernate,我们可以编写:
Otherwise, we need to specify the file in the configuration property jakarta.persistence.sql-load-script-source. If we’re using Configuration to configure Hibernate, we could write:
configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_LOAD_SCRIPT_SOURCE,
"/org/example/test-data.sql");SQL 脚本将在每次调用 exportMappedObjects() 或 truncateMappedObjects() 时执行。
The SQL script will be executed every time exportMappedObjects() or truncateMappedObjects() is called.
|
测试可能会留下另一种混乱: second-level cache 中的缓存数据。我们建议对大多数类型的测试 disabling Hibernate 的二级缓存。或者,如果二级缓存未禁用,则在每个测试之前我们应该调用: |
|
There’s another sort of mess a test can leave behind: cached data in the second-level cache. We recommend disabling Hibernate’s second-level cache for most sorts of testing. Alternatively, if the second-level cache is not disabled, then before each test we should call: |
sessionFactory.getCache().evictAllRegions(); sessionFactory.getCache().evictAllRegions();
sessionFactory.getCache().evictAllRegions(); sessionFactory.getCache().evictAllRegions();
现在,假设你遵循了我们的建议,编写了实体和查询方法以最大程度地减少对“基础设施”的依赖,即依赖于 JPA 和 Hibernate 之外的库、框架、容器管理对象,甚至依赖于难以从头实例化的你自己的系统部分。这样,测试持久性逻辑就是直接的了!
Now, suppose you’ve followed our advice, and written your entities and query methods to minimize dependencies on "infrastructure", that is, on libraries other than JPA and Hibernate, on frameworks, on container-managed objects, and even on bits of your own system which are hard to instantiate from scratch. Then testing persistence logic is now straightforward!
你需要:
You’ll need to:
-
bootstrap Hibernate and create a SessionFactory or EntityManagerFactory and the beginning of your test suite (we’ve already seen how to do that), and
-
create a new Session or EntityManager inside each @Test method, using inTransaction(), for example.
实际上,某些测试可能需要多个会话。但要小心不要在不同的测试之间泄露会话。
Actually, some tests might require multiple sessions. But be careful not to leak a session between different tests.
|
另外一个我们需要的重要的测试是针对实际数据库模式验证我们的 O/R mapping annotations 。这再次是模式管理工具的任务,要么是: |
|
Another important test we’ll need is one which validates our O/R mapping annotations against the actual database schema. This is again the job of the schema management tooling, either: |
configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION, Action.ACTION_VALIDATE); configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION, Action.ACTION_VALIDATE); 或:
configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION, Action.ACTION_VALIDATE); configuration.setProperty(AvailableSettings.JAKARTA_HBM2DDL_DATABASE_ACTION, Action.ACTION_VALIDATE); Or:
sessionFactory.getSchemaManager().validateMappedObjects(); sessionFactory.getSchemaManager().validateMappedObjects(); 许多人甚至在生产环境中也喜欢在系统启动时运行此“测试”。
sessionFactory.getSchemaManager().validateMappedObjects(); sessionFactory.getSchemaManager().validateMappedObjects(); This "test" is one which many people like to run even in production, when the system starts up.
1.7. Architecture and the persistence layer
现在让我们考虑一种不同的代码组织方法,一种让我们心生怀疑的方法。
Let’s now consider a different approach to code organization, one we treat with suspicion.
在本节中,我们将向你提供我们的 opinion。如果你只对事实感兴趣,或者如果你不想阅读可能破坏你当前观点的信息,请跳至 next chapter。
In this section, we’re going to give you our opinion. If you’re only interested in facts, or if you prefer not to read things that might undermine the opinion you currently hold, please feel free to skip straight to the next chapter.
Hibernate 是一个与架构无关的库,而不是一个框架,因此可以与广泛的 Java 框架和容器集成。与我们在生态系统中的位置一致的是,我们历来避免就架构提出太多建议。这是一个我们现在可能倾向于后悔的做法,因为由此产生的真空已经被提倡架构、设计模式和我们认为会使 Hibernate 的使用变得不太愉快且不必要的额外框架的人们的建议所填补。
Hibernate is an architecture-agnostic library, not a framework, and therefore integrates comfortably with a wide range of Java frameworks and containers. Consistent with our place within the ecosystem, we’ve historically avoided giving out much advice on architecture. This is a practice we’re now perhaps inclined to regret, since the resulting vacuum has come to be filled with advice from people advocating architectures, design patterns, and extra frameworks which we suspect make Hibernate a bit less pleasant to use than it should be.
尤其是,包装 JPA 的框架似乎增加了臃肿,而减弱了 Hibernate 努力提供的对数据访问的细化控制。这些框架不会公开 Hibernate 的完整特性集,因此程序被迫使用不那么强大的抽象。
In particular, frameworks which wrap JPA seem to add bloat while subtracting some of the fine-grained control over data access that Hibernate works so hard to provide. These frameworks don’t expose the full feature set of Hibernate, and so the program is forced to work with a less powerful abstraction.
我们犹豫着质疑这种呆板、教条的 conventional 智慧,只是因为害怕在招惹这种教条的时候刺伤自己不可避免地竖起的逆毛:
The stodgy, dogmatic, conventional wisdom, which we hesitate to challenge for simple fear of pricking ourselves on the erect hackles that inevitably accompany such dogma-baiting is:
我们缺乏勇气,甚至信念,来明确告诉你 not 遵循此建议。但是,我们确实要求你考虑在任何体系架构层中样板的成本,以及这种成本所带来的收益是否真的值得你的系统。
We lack the courage—perhaps even the conviction—to tell you categorically to not follow this recommendation. But we do ask you to consider the cost in boilerplate of any architectural layer, and whether the benefits this cost buys are really worth it in the context of your system.
为了给这次讨论添加一些背景信息,并且冒着我们的简介在如此早期的阶段变成咆哮的风险,我们要请你容忍一下,同时我们更多地谈论一些往事。
To add a little background texture to this discussion, and at the risk of our Introduction degenerating into a rant at such an early stage, we’re going ask you to humor us while talk a little more about ancient history.
最终,我们不确定你是否还需要一个单独的持久性层。至少 consider,从业务逻辑中直接调用 EntityManager 可能是没有问题的。
Ultimately, we’re not sure you need a separate persistence layer at all. At least consider the possibility that it might be OK to call the EntityManager directly from your business logic.
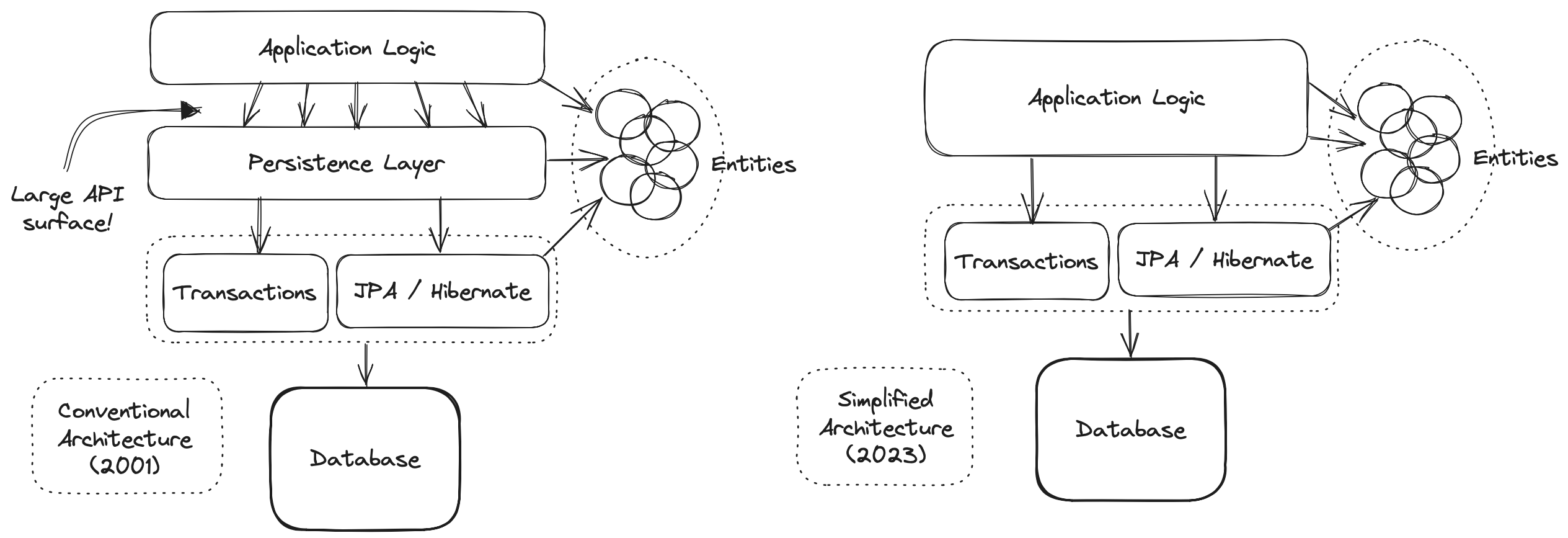
我们已经能听到你对我们的异端发出嘘声。但在摔上你笔记本的盖子并冲出去取大蒜和干草叉之前,花几个小时权衡一下我们的提议。
We can already hear you hissing at our heresy. But before slamming shut the lid of your laptop and heading off to fetch garlic and a pitchfork, take a couple of hours to weigh what we’re proposing.
好吧,所以,看看吧,如果这让你感觉更好,查看 EntityManager 的一种方法是将其视为一个单独的 generic “仓库”,它适用于系统中的每个实体。从这个角度来看,JPA is 你的持久性层。而且几乎没有理由用一个 less 通用、抽象的第二个抽象层将这个抽象包裹起来。
OK, so, look, if it makes you feel better, one way to view EntityManager is to think of it as a single generic "repository" that works for every entity in your system. From this point of view, JPA is your persistence layer. And there’s few good reasons to wrap this abstraction in a second abstraction that’s less generic.
即使在明显适当的持久性层中,DAO 样式的仓库也不是对等式分解最明确最正确的方法:
Even where a distinct persistence layer is appropriate, DAO-style repositories aren’t the unambiguously most-correct way to factorize the equation:
-
most nontrivial queries touch multiple entities, and so it’s often quite ambiguous which repository such a query belongs to,
-
most queries are extremely specific to a particular fragment of program logic, and aren’t reused in different places across the system, and
-
the various operations of a repository rarely interact or share common internal implementation details.
事实上,仓库本质上表现出非常低的 cohesion。如果你有每个仓库的多个实现,一个仓库对象层可能有意义,但在实践中几乎没有人这样做。这是因为它们对它们的客户端也是极其 coupled 的,具有非常大的 API 表面。相反,如果它具有非常 narrow 的 API,一个层才容易替换。
Indeed, repositories, by nature, exhibit very low cohesion. A layer of repository objects might make sense if you have multiple implementations of each repository, but in practice almost nobody ever does. That’s because they’re also extremely highly coupled to their clients, with a very large API surface. And, on the contrary, a layer is only easily replaceable if it has a very narrow API.
|
有些人确实使用模拟存储库进行测试,但我们确实很难从中看出任何价值。如果我们不想针对我们的真实数据库运行测试,通常可以通过针对 H2 之类的内存 Java 数据库运行测试来“模拟”数据库本身。在 Hibernate 6 中,这种做法比在 Hibernate 的较早版本中效果更好,因为 HQL 现在 much 在不同平台间更易于移植。 |
|
Some people do indeed use mock repositories for testing, but we really struggle to see any value in this. If we don’t want to run our tests against our real database, it’s usually very easy to "mock" the database itself by running tests against an in-memory Java database like H2. This works even better in Hibernate 6 than in older versions of Hibernate, since HQL is now much more portable between platforms. |
Phew,让我们继续。
Phew, let’s move on.
1.8. Overview
现在是开始 understanding 我们之前看到的代码的旅程的时候了。
It’s now time to begin our journey toward actually understanding the code we saw earlier.
本引言将指导你完成开发使用 Hibernate 进行持久性的程序所涉及的基本任务:
This introduction will guide you through the basic tasks involved in developing a program that uses Hibernate for persistence:
-
configuring and bootstrapping Hibernate, and obtaining an instance of SessionFactory or EntityManagerFactory,
-
writing a domain model, that is, a set of entity classes which represent the persistent types in your program, and which map to tables of your database,
-
customizing these mappings when the model maps to a pre-existing relational schema,
-
using the Session or EntityManager to perform operations which query the database and return entity instances, or which update the data held in the database,
-
using the Hibernate Metamodel Generator to improve compile-time type-safety,
-
writing complex queries using the Hibernate Query Language (HQL) or native SQL, and, finally
-
tuning performance of the data access logic.
当然,我们要从这个列表的开头、最无趣的主题开始:configuration。
Naturally, we’ll start at the top of this list, with the least-interesting topic: configuration.