Hibernate ORM 中文操作指南
7. Tuning and performance
一旦你有一个正在使用 Hibernate 访问数据库的程序,你肯定会发现在某些地方性能令人失望或无法接受。
幸运的是,只要记住一些简单的原则,大多数性能问题都可以通过 Hibernate 为你提供的工具轻松解决。
首先也是最重要的:你使用 Hibernate 的原因是它让事情变得更容易。如果对于某个问题,它让事情 harder,那就停止使用它。改用不同的工具来解决此问题。
第二:在使用 Hibernate 的程序中,有两个主要的潜在性能瓶颈来源:
-
往返数据库的次数过多,且
-
与一级(会话)缓存关联的内存消耗。
因此,性能调优主要涉及减少对数据库的访问次数,和/或控制会话缓存的大小。
但在我们讨论这些更高级的话题之前,我们应该先调整连接池。
7.1. Tuning the connection pool
Hibernate 中内置的连接池适合于测试,但不用于产品环境。相反,Hibernate 支持一系列不同的连接池,包括我们最喜欢的 Agroal。
要选择并配置 Agroal,您需要设置一些额外的配置属性,除了我们已经在 Basic configuration settings 中看到设置。前缀为 hibernate.agroal 的属性被传递到 Agroal:
# configure Agroal connection pool
hibernate.agroal.maxSize 20
hibernate.agroal.minSize 10
hibernate.agroal.acquisitionTimeout PT1s
hibernate.agroal.reapTimeout PT10s只要你至少设置了一个前缀为 hibernate.agroal 的属性,就会自动选择 AgroalConnectionProvider。有很多可供选择:
表格 43. 配置 Agroal 的设置
Configuration property name |
Purpose |
hibernate.agroal.maxSize |
在池中存在的最大连接数 |
hibernate.agroal.minSize |
池中存在的最小连接数 |
hibernate.agroal.initialSize |
启动池时添加到池中的连接数 |
hibernate.agroal.maxLifetime |
连接可以存在的最长时间,之后将其从池中删除 |
hibernate.agroal.acquisitionTimeout |
抛出异常之前,线程可以等待连接的最长时间 |
hibernate.agroal.reapTimeout |
清空闲置连接的时间段 |
hibernate.agroal.leakTimeout |
连接被保持多长时间后会报告泄漏 |
hibernate.agroal.idleValidationTimeout |
当一个连接在池中闲置的时间超过此时间段,会执行前台验证 |
hibernate.agroal.validationTimeout |
后台验证检查之间的间隔 |
hibernate.agroal.initialSql |
创建连接时要执行的 SQL 命令 |
以下设置对 Hibernate 支持的所有连接池通用:
表格 44. 连接池的通用设置
hibernate.connection.autocommit |
The default autocommit mode |
hibernate.connection.isolation |
默认事务隔离级别 |
7.2. Enabling statement batching
一种轻易提高某些事务性能的方法,几乎不需要任何工作,就是启用自动 DML 语句批处理。批处理仅有助于程序在单个事务中对同一张表执行多次插入、更新或删除的情况。
我们只需要设置一个属性:
表 45. 启用 JDBC 批量处理
Configuration property name |
Purpose |
Alternative |
hibernate.jdbc.batch_size |
SQL 语句批处理的最大批处理大小 |
setJdbcBatchSize() |
|
比 DML 语句批处理更好的方法是使用 HQL update 或 delete 查询,甚至是调用存储过程的原生 SQL! |
7.3. Association fetching
在 ORM 中实现高性能意味着尽量减少与数据库的往返次数。无论在何时使用 Hibernate 编写数据访问代码时,这个目标都应该放在首位。ORM 中最基本的经验法则就是:
-
在一个会话/事务的开始就明确指定需要的所有数据,并立即在一次或两次查询中获取,
-
然后才开始在持久实体之间导航关联。
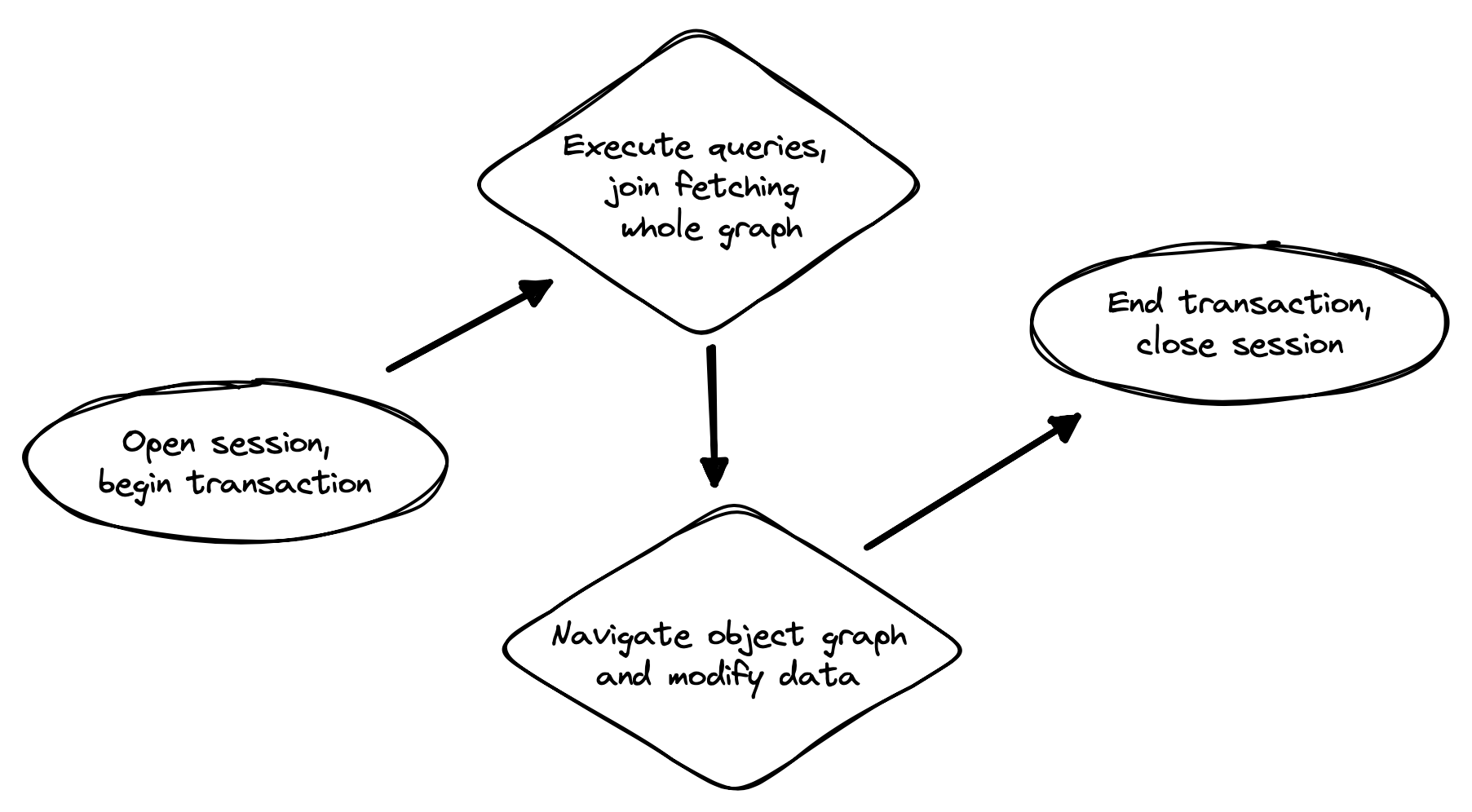
毫无疑问,Java 程序中数据访问代码性能低下的最常见原因就是 N+1 selects 问题。此处,将在初始查询中从数据库中检索 N 行列表,然后使用 N 后续查询获取相关实体的关联实例。
这不是 Hibernate 的缺陷或限制;这个问题甚至影响了在 DAO 背后的典型的手写 JDBC 代码。只有你能作为开发者解决这个问题,因为只有你知道在给定的工作单元中你事先需要什么数据。但这没关系。Hibernate 会为你提供你需要的所有工具。
在这一部分中,我们将讨论避免与数据库进行此类“多嘴”交互的不同方式。
Hibernate 提供了多种策略,用于高效获取关联并避免 N+1 选择:
-
outer join fetching—使用 _left outer join_获取关联,
-
batch fetching—使用后续带有主键批处理的 _select_获取关联,且
-
subselect fetching—使用后续带有在子选择中重新查询的键的 _select_获取关联。
在这些策略中,你几乎始终应该使用外连接获取。但我们先来考虑一下其他方法。
7.4. Batch fetching and subselect fetching
考虑以下代码:
List<Book> books =
session.createSelectionQuery("from Book order by isbn", Book.class)
.getResultList();
books.forEach(book -> book.getAuthors().forEach(author -> out.println(book.title + " by " + author.name)));这段代码 very 效率低下,默认情况下会导致执行 N+1 select 条语句,其中 N 是 Book 的数量。
让我们看看如何改进。
SQL for batch fetching
启用批量提取后,Hibernate 可能会在 PostgreSQL 上执行以下 SQL:
/* initial query for Books */
select b1_0.isbn,b1_0.price,b1_0.published,b1_0.publisher_id,b1_0.title
from Book b1_0
order by b1_0.isbn
/* first batch of associated Authors */
select a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name
from Book_Author a1_0
join Author a1_1 on a1_1.id=a1_0.authors_id
where a1_0.books_isbn = any (?)
/* second batch of associated Authors */
select a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name
from Book_Author a1_0
join Author a1_1 on a1_1.id=a1_0.authors_id
where a1_0.books_isbn = any (?)第一个 select 语句查询并检索 Book_s. The second and third queries fetch the associated _Author_s in batches. The number of batches required depends on the configured _batch size。此处,需要两个批次,因此执行了两个 SQL 语句。
|
用于批处理提取的 SQL 根据数据库略有不同。这里在 PostgreSQL 中,Hibernate 将主密钥值批次作为 SQL ARRAY 传递。 |
SQL for subselect fetching
另一方面,使用子查询抓取,Hibernate 将执行以下 SQL:
/* initial query for Books */
select b1_0.isbn,b1_0.price,b1_0.published,b1_0.publisher_id,b1_0.title
from Book b1_0
order by b1_0.isbn
/* fetch all associated Authors */
select a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name
from Book_Author a1_0
join Author a1_1 on a1_1.id=a1_0.authors_id
where a1_0.books_isbn in (select b1_0.isbn from Book b1_0)请注意,第一个查询在第二个查询的子查询中被重新执行。执行子查询可能会相对便宜,因为数据可能已由数据库缓存。很巧妙,对吧?
Enabling the use of batch or subselect fetching
批次获取和子查询获取在默认情况下都已禁用,但我们可以使用属性在全局启用一个或另一个。
表 46. 启用批次和子查询获取的配置设置
Configuration property name |
Property value |
Alternatives |
hibernate.default_batch_fetch_size |
合理的 >1 批处理大小,启用批处理获取 |
@BatchSize(), setFetchBatchSize() |
hibernate.use_subselect_fetch |
true 启用子选择获取 |
@Fetch(SUBSELECT), setSubselectFetchingEnabled() |
或者,我们可以在给定的会话中启用一个或另一个:
session.setFetchBatchSize(5);
session.setSubselectFetchingEnabled(true);|
我们可以通过使用 @Fetch 注释对集合或多值关联进行注释来请求更具选择性的子查询获取。 |
@ManyToMany @Fetch(SUBSELECT) Set<Author> authors; @ManyToMany @Fetch(SUBSELECT) Set<Author> authors; 请注意, @Fetch(SUBSELECT) 的效果与 @Fetch(SELECT) 相同,除了在执行 HQL 或条件查询之后。但在查询执行后, @Fetch(SUBSELECT) 能够更有效地获取关联。
稍后,我们将了解如何使用 fetch profiles 更加有选择性地执行此操作。
仅此而已。太简单了,对吧?
遗憾的是,这并非故事的结局。虽然批次获取可能会 mitigate 涉及 N+1 选择的问题,但它不会解决问题。真正正确的解决方案是使用联接获取关联。在罕见情况下,外部联接获取会导致笛卡尔积和庞大的结果集时,批次获取(或子查询获取)才能成为 best 解决方案。
但批次获取和子查询获取有一个共同的重要特性:它们可以 lazily 执行。原则上,这非常方便。当我们查询数据并随后浏览对象图时,延迟获取可为我们省去提前规划的麻烦。事实证明,这是一个我们需要放弃的便利。
7.5. Join fetching
外部联接获取通常是获取关联的最佳方法,也是我们大多数时间使用的方法。遗憾的是,联接获取从其本质来说根本无法延迟。因此,为了利用联接获取,我们必须提前规划。我们的普遍建议是:
|
现在,我们并不是说应该默认映射关联以便快速提取!这将是一个可怕的想法,会导致提取整个数据库几乎所有数据的简单会话操作。因此: |
|
听起来这个提示与前面的提示相矛盾,但事实并非如此。它表示你必须明确指定关联的快速提取,仅在需要的时候和需要的地方提取。 |
如果我们需要在某些特定事务中执行急切联接获取,我们有四种不同的方式指定。
Passing a JPA EntityGraph |
我们在 Entity graphs and eager fetching已看过这个 |
指定一个具名 fetch profile |
稍后我们将在 Named fetch profiles中讨论这种方法 |
在 HQL/JPQL 中使用 left join fetch |
有关详情,请参阅 A Guide to Hibernate Query Language |
在 criteria 查询中使用 From.fetch() |
与 join fetch 在 HQL 中相同的含义 |
通常情况下,查询是最方便的选项。下面是如何在 HQL 中请求联接获取:
List<Book> booksWithJoinFetchedAuthors =
session.createSelectionQuery("from Book join fetch authors order by isbn")
.getResultList();这是同一查询,使用条件 API 编写:
var builder = sessionFactory.getCriteriaBuilder();
var query = builder.createQuery(Book.class);
var book = query.from(Book.class);
book.fetch(Book_.authors);
query.select(book);
query.orderBy(builder.asc(book.get(Book_.isbn)));
List<Book> booksWithJoinFetchedAuthors =
session.createSelectionQuery(query).getResultList();不管哪种方式,都会执行一条 SQL select 语句:
select b1_0.isbn,a1_0.books_isbn,a1_1.id,a1_1.bio,a1_1.name,b1_0.price,b1_0.published,b1_0.publisher_id,b1_0.title
from Book b1_0
join (Book_Author a1_0 join Author a1_1 on a1_1.id=a1_0.authors_id)
on b1_0.isbn=a1_0.books_isbn
order by b1_0.isbn好多了!
联接获取尽管无法延迟,但显然比批次或子查询获取效率更高,而我们建议避免使用延迟获取的依据正在于此。
|
联接提取变得低效有一个有趣的情况:当我们提取两个多值关联 in parallel 时。想象一下,我们想要在某些工作单元中提取 Author.books 和 Author.royaltyStatements。在一个查询中联接这两个集合将导致表的笛卡尔积以及一个较大的 SQL 结果集。子选择提取在此处派上了用场,它允许我们使用联接提取 books,并使用单一的后续 select 提取 royaltyStatements。 |
当然,避免多次往返数据库的另一种方法是在 Java 客户端中缓存我们所需的数据。如果我们期望在本地缓存中找到关联数据,那么我们很有可能根本不需要联接抓取。
|
但是,如果我们不能 certain 确保所有关联的数据都处于缓存中,该如何办?在这种情况下,我们也许能够通过启用批处理提取来减少高速缓存未命中成本。 |
7.6. The second-level cache
减少对数据库访问次数的经典方法是使用二级缓存,允许以会话为单位共享内存中缓存的数据。
根据特性,二级缓存往往会破坏关系数据库中事务处理的 ACID 特性。我们 don’t 使用分布式事务和两阶段提交,以确保对缓存和数据库的更改以原子方式进行。因此,二级缓存通常是改善系统性能最简单的途径,但代价是让有关并发性的推理变得更加困难。因此,缓存是难以隔离和重现的错误的潜在来源。
因此,默认情况下,实体没有资格存储在二级缓存中。我们必须使用 org.hibernate.annotations 中的 @Cache 注释显式地标记将在二级缓存中存储的每个实体。
但仍不够。Hibernate 本身不包含二级缓存的实现,因此,有必要配置外部 cache provider。
默认情况下已禁用高速缓存。为了最大限度降低数据丢失的风险,我们强制你暂停并思考,然后再将任何实体放入高速缓存。
Hibernate 将二级缓存分割成命名 regions,每个 regions 分别用于:
-
mapped entity hierarchy or
-
collection role.
例如,可能存在 @{1}、@{2}、@{3}、@{4} 的独立缓存区。
每个区域都被允许使用它自己的过期、持久化和复制策略。这些策略必须在外部配置为 Hibernate。
适当的策略取决于实体所表示的数据类型。例如,程序可能对“参考”数据、交易数据和用于分析的数据使用不同的缓存策略。通常,这些策略的实现是基础缓存实现的责任。
7.7. Specifying which data is cached
默认情况下,没有任何数据符合存储在二级缓存中的条件。
可以使用 @{5} 注解为实体层级或集合角色分配一个区域。如果不明确指定区域名称,则区域名称仅仅是实体类或集合角色的名称。
@Entity
@Cache(usage=NONSTRICT_READ_WRITE, region="Publishers")
class Publisher {
...
@Cache(usage=READ_WRITE, region="PublishedBooks")
@OneToMany(mappedBy=Book_.PUBLISHER)
Set<Book> books;
...
}由 @{6} 注解定义的缓存会被 Hibernate 自动利用来:
-
当调用 _find()_时按 ID 检索实体,或
-
按 ID 解析关联。====== @Cache 注释必须指定在实体继承级别的 root class 中。将注释放置在子类实体中是错误的。
@Cache 注释总是指定一个 CacheConcurrencyStrategy ,即管理并发事务对二级缓存访问的策略。
表格 47。缓存并发
Concurrency policy |
Interpretation |
Explanation |
READ_ONLY |
Immutable dataRead-only access |
表示缓存的对象不可更改,永远不会更新。如果具有这种缓存并发的实体已更新,则会引发异常。这是最简单,最安全,性能最好的缓存并发策略。它特别适用于所谓的“引用”数据。 |
NONSTRICT_READ_WRITE |
并发更新极不可能读/写访问无锁定 |
表示缓存的对象有时会更新,但两个事务同时尝试更新同一数据项的可能性极低。此策略不使用锁。当某个项更新时,更新事务完成之前和完成之后都将缓存置为无效。但是,如果不加锁,就无法完全排除在第一个事务完成过程中,第二个事务在缓存中存储或检索过期数据的可能性。 |
READ_WRITE |
并发更新有可能但不常见读取/写入访问使用软锁定 |
表示两个并发事务同时尝试更新同一数据项的可能性不小。此策略使用“软”锁来防止并发事务在事务完成过程中从缓存中检索或存储过期项。软锁只是在更新事务完成时放置在缓存中的一个标记条目。当存在软锁时,第二个事务可能无法从缓存中读取该项,而只能直接从数据库中读取该项,就像发生了常规缓存未命中一样。同样,当第二个事务从其返回到数据库时,软锁也防止该事务将过时项存储到缓存中,而返回的内容可能不是最新版本。 |
TRANSACTIONAL |
并发更新频繁事务访问 |
表示并发写入很常见,并且通过使用完全的事务缓存提供程序来维护二级缓存和数据库之间的同步是唯一的方法。在这种情况下,缓存和数据库必须通过 JTA 或 XA 协议进行协作,而 Hibernate 本身承担维护缓存完整性的责任很小。 |
哪些策略有意义也可能取决于基础二级缓存实现。
JPA 有一个类似的注释,名为 @Cacheable 。不幸的是,它对我们几乎没用,因为:
它提供的指定缓存实体性质及管理其缓存的方式的信息,且
可能不能用于注释关联,因此我们甚至无法使用它将集合角色标记为有资格存储在二级缓存中。
=== 7.8. Caching by natural id
如果我们的实体有一个 natural id,我们可以通过注释实体 @NaturalIdCache 来启用一个附加缓存,该缓存保存从自然 ID 到主键 ID 的交叉引用。默认情况下,自然 ID 缓存存储在二级缓存的专用区域中,单独于缓存的实体数据。
@Entity
@Cache(usage=READ_WRITE, region="Book")
@NaturalIdCache(region="BookIsbn")
class Book {
...
@NaturalId
String isbn;
@NaturalId
int printing;
...
}当使用执行 lookup by natural id 的 Session 的操作之一来检索实体时,将使用此缓存。
由于自然 ID 缓存不包含实体的实际状态,因此除非实体已经符合存储在二级缓存中的条件(即也注释了 @Cache),否则对实体 @NaturalIdCache 进行注释毫无意义。
值得注意的是,与实体的主标识符不同,自然 ID 可能可变。
现在我们必须考虑一个精细之处,在处理所谓的“参考数据”时经常会出现,即能轻松装入内存且不太会发生变化的数据。
=== 7.9. Caching and association fetching
让我们再次考虑我们的 @{9} 类:
@Cache(usage=NONSTRICT_READ_WRITE, region="Publishers")
@Entity
class Publisher { ... }关于出版商的数据不会经常发生变化,而且数量也不多。假设我们已做好一切设置,以便出版商几乎 @{10} 可以在二级缓存中使用。
那么在这种情况下,我们需要仔细考虑类型 @{11} 的关联。
@ManyToOne
Publisher publisher;这个关联不需要延迟获取,因为我们希望它可以在内存中使用,因此我们不会设置它为 @{12}。但另一方面,如果我们将其标记为立即获取,则默认情况下,Hibernate 通常会使用连接来获取它。这会给数据库带来完全不必要的负载。
解决方案是 @Fetch 注释:
@ManyToOne @Fetch(SELECT)
Publisher publisher;通过对关联 @{14} 进行注解,我们压制连接获取,给 Hibernate 一个机会在缓存中找到关联的 @{15}。
因此,我们得出了以下经验法则:
到“引用数据”或几乎总是可用于缓存中的任何其他数据的多对一关联都应映射 EAGER , SELECT 。
其他关联,如我们 already made clear ,应为 LAZY 。
一旦我们将实体或集合标记为符合存储在二级缓存中的条件,我们仍然需要设置一个实际的缓存。
=== 7.10. Configuring the second-level cache provider
配置二级缓存提供程序是一个相当复杂的话题,并且超出了本文档的范围。但是,如果它有帮助,我们经常使用以下配置来测试 Hibernate,其中使用 EHCache 作为缓存实现,如上所示 Optional dependencies:
表格 48. EHCache 配置
Configuration property name |
Property value |
hibernate.cache.region.factory_class |
jcache |
hibernate.javax.cache.uri |
/ehcache.xml |
如果你正在使用 EHCache,你还需要包含一个 ehcache.xml 文件,该文件明确配置属于你的实体和集合的每个缓存区域的行为。有关配置 EHCache 的更多信息,请参阅 here。
我们可能使用 JCache 的任何其他实现,例如 Caffeine。JCache 会自动选择它在类路径中找到的任何实现。如果类路径上有多个实现,我们必须使用以下内容消除歧义:
表格 49. 消除 JCache 实现歧义
Configuration property name |
Property value |
hibernate.javax.cache.provider |
javax.cache.spiCachingProvider 的实现,例如:对于 EHCache_,org.ehcache.jsr107.EhcacheCachingProvider_对于 Caffeine,com.github.benmanes.caffeine.jcache.spi.CaffeineCachingProvider |
org.ehcache.jsr107.EhcacheCachingProvider |
for EHCache |
com.github.benmanes.caffeine.jcache.spi.CaffeineCachingProvider |
for Caffeine |
或者,要使用 Infinispan 作为缓存实现,需要以下设置:
表格 50. Infinispan 提供程序配置
Configuration property name |
Property value |
hibernate.cache.region.factory_class |
infinispan |
hibernate.cache.infinispan.cfg |
Infinispan 配置文件的路径,例如:_org/infinispan/hibernate/cache/commons/builder/infinispan-configs.xml_对于分布式缓存_org/infinispan/hibernate/cache/commons/builder/infinispan-configs-local.xml_用于以本地缓存进行测试 |
org/infinispan/hibernate/cache/commons/builder/infinispan-configs.xml |
for a distributed cache |
org/infinispan/hibernate/cache/commons/builder/infinispan-configs-local.xml |
使用本地缓存进行测试 |
当需要分布式缓存时,通常使用 Infinispan。有关将 Infinispan 与 Hibernate 配合使用的更多信息,请参阅 here。
最后,有一种方法可以全局禁用二级缓存:
表格 51. 禁用缓存的设置
Configuration property name |
Property value |
hibernate.cache.use_second_level_cache |
true 启用缓存,或 false 禁用缓存 |
设置 hibernate.cache.region.factory_class 时,此属性默认为 true。
此设置使我们能够在进行故障排除或性能分析时轻松完全禁用二级缓存。
您可以在 User Guide 中找到有关二级缓存的更多信息。
=== 7.11. Caching query result sets
我们上面介绍的缓存仅用于通过 ID 或自然 ID 优化查找。Hibernate 还可以缓存查询的结果集,尽管这通常不是有效的方法。
必须显式启用查询缓存:
表格 52. 启用查询缓存的设置
Configuration property name |
Property value |
hibernate.cache.use_query_cache |
true 启用查询缓存 |
要缓存查询结果,请调用 SelectionQuery.setCacheable(true):
session.createQuery("from Product where discontinued = false")
.setCacheable(true)
.getResultList();默认情况下,查询结果集存储在名为 default-query-results-region 的缓存区域中。由于不同的查询应具有不同的缓存策略,因此通常明确指定区域名称:
session.createQuery("from Product where discontinued = false")
.setCacheable(true)
.setCacheRegion("ProductCatalog")
.getResultList();结果集与 logical timestamp 一起缓存。所谓“逻辑”,即它实际上不会随着时间线性增加,它特别不是系统时间。
当 Product 更新时,Hibernate does not 遍历查询缓存,使受变更影响的每个已缓存结果集失效。而缓存有一个特殊区域存储每个表的最近更新的逻辑时间戳,称为 update timestamps cache,并且保留在区域 default-update-timestamps-region 中。
设置此高速缓存区域时必须确保使用了适当的策略。具体来说,更新时间戳绝不应过期或移除。
当从缓存中读取查询结果集时,Hibernate 会将时间戳与影响查询结果的每个表的时间戳进行比较,并且 only 在结果集不是过时的情况下返回结果集。如果结果集 is 过时,Hibernate 将继续执行针对数据库的查询并更新缓存的结果集。
通常情况下,二级缓存与任何二级缓存一样,都会破坏事务的 ACID 规则。
=== 7.12. Second-level cache management
二级缓存大多数是透明的。与 Hibernate 会话交互的程序逻辑不知道该缓存,并且不受缓存策略变更的影响。
最差情况下,可以通过指定显式 CacheMode 来控制与缓存的交互:
session.setCacheMode(CacheMode.IGNORE);或者,使用 JPA-standard API:
entityManager.setCacheRetrieveMode(CacheRetrieveMode.BYPASS);
entityManager.setCacheStoreMode(CacheStoreMode.BYPASS);JPA 定义的缓存模式分为两种:CacheRetrieveMode 和 CacheStoreMode。
表 53. JPA 定义的缓存检索模式
Mode |
Interpretation |
CacheRetrieveMode.USE |
在可用时从缓存读取数据 |
CacheRetrieveMode.BYPASS |
不要从缓存读取数据;直接转到数据库 |
如果我们担心从缓存读取陈旧数据,则可以选择 CacheRetrieveMode.BYPASS。
表 54. JPA 定义的缓存存储模式
Mode |
Interpretation |
CacheStoreMode.USE |
在从数据库读取数据或修改数据时将数据写入缓存;读取时不更新已缓存的项 |
CacheStoreMode.REFRESH |
在从数据库读取数据或修改数据时将数据写入缓存;读取时始终更新缓存的项 |
CacheStoreMode.BYPASS |
不要将数据写入缓存 |
如果我们查询不需要缓存的数据,则应该选择 CacheStoreMode.BYPASS。
在运行返回大型结果集的查询之前(查询返回的是我们认为不久后不需要的大量数据),最好将 CacheStoreMode 设置为 BYPASS。这样做可以节省工作,并防止新读取的数据将先前缓存的数据推出。
在 JPA 中,我们将使用此惯用语:
entityManager.setCacheStoreMode(CacheStoreMode.BYPASS);
List<Publisher> allpubs =
entityManager.createQuery("from Publisher", Publisher.class)
.getResultList();
entityManager.setCacheStoreMode(CacheStoreMode.USE);但是 Hibernate 有更好的方法:
List<Publisher> allpubs =
session.createSelectionQuery("from Publisher", Publisher.class)
.setCacheStoreMode(CacheStoreMode.BYPASS)
.getResultList();Hibernate CacheMode 使用 CacheStoreMode 打包 CacheRetrieveMode。
表 55. Hibernate 缓存模式和 JPA 等效项
Hibernate CacheMode |
Equivalent JPA modes |
NORMAL |
CacheRetrieveMode.USE, CacheStoreMode.USE |
IGNORE |
CacheRetrieveMode.BYPASS, CacheStoreMode.BYPASS |
GET |
CacheRetrieveMode.USE, CacheStoreMode.BYPASS |
PUT |
CacheRetrieveMode.BYPASS, CacheStoreMode.USE |
REFRESH |
CacheRetrieveMode.REFRESH, CacheStoreMode.BYPASS |
没有特别的理由选择 Hibernate 的 CacheMode 而不是 JPA 等效项。这种枚举只存在于 Hibernate 拥有缓存模式的时候,远早于将其添加到 JPA 的时候。
对于“参考”数据,即始终应在二级缓存中找到的数据,最好在启动时 prime 缓存。有一种方法非常简单:只需在获取 EntityManager 或 SessionFactory 后立即执行查询。
SessionFactory sessionFactory = setupHibernate(new Configuration()) .buildSessionFactory(); sessionFactory.inSession(session → { session.createSelectionQuery("from Country")) .setReadOnly(true) .getResultList(); session.createSelectionQuery("from Product where discontinued = false")) .setReadOnly(true) .getResultList(); }); SessionFactory sessionFactory = setupHibernate(new Configuration()) .buildSessionFactory(); sessionFactory.inSession(session → { session.createSelectionQuery("from Country")) .setReadOnly(true) .getResultList(); session.createSelectionQuery("from Product where discontinued = false")) .setReadOnly(true) .getResultList(); });
极少情况下,需要或可控明确地控制缓存,例如,清除我们知道已过时的某些数据。Cache 接口允许以编程方式清除缓存的项目。
sessionFactory.getCache().evictEntityData(Book.class, bookId);通过 Cache 接口管理二级缓存不会感知事务。Cache 的任何操作都不遵守基础高速缓存相关的任何隔离或事务语义。具体来说,通过此接口的方法进行移除会导致超出任何当前事务及/或锁定方案的立即“强制”移除。
但是,通常在修改后,Hibernate 会自动逐出或更新缓存的数据,此外,未使用的缓存数据最终会根据配置的策略过期。
这与一级缓存中发生的情况完全不同。
=== 7.13. Session cache management
当不再需要实体实例时,它们不会自动从会话缓存中清除。相反,它们在程序丢弃它们所在的会话之前一直固定在内存中。
方法 detach() 和 clear() 允许你从会话缓存中删除实体,使其可供垃圾回收。由于大多数会话的持续时间都很短,因此你不太需要进行这些操作。而且如果你发现自己在想自己在某种情况下需要 do,则应该认真考虑替代解决方案:一个 stateless session。
=== 7.14. Stateless sessions
Hibernate 一个可以说未被充分重视的特性是 StatelessSession 接口,它提供了一种面向命令、更底层的与数据库交互的方法。
你可以从 SessionFactory 获取无状态会话:
StatelessSession ss = getSessionFactory().openStatelessSession();一个无状态会话:
-
没有一级缓存(持久性上下文),也不与任何二级缓存交互,且
-
不执行事务性后台写入或自动污点检查,因此所有操作在明确调用时都会立即执行。
对于无状态会话,我们始终使用分离的对象。因此,编程模型有点不同:
表 56. StatelessSession 的重要方法
Method name and parameters |
Effect |
get(Class, Object) |
通过执行 select 获取具有其类型和 id 的分离对象 |
fetch(Object) |
获取分离对象的关联 |
refresh(Object) |
通过执行 select 刷新分离对象的状态 |
insert(Object) |
立即将给定瞬态对象的状态 insert 到数据库 |
update(Object) |
立即将给定分离对象的状态 update 到数据库 |
delete(Object) |
立即 delete 与数据库中的给定分离对象的状态分离 |
upsert(Object) |
立即 insert 或 update 使用 SQL merge into 语句给定分离对象的状态 |
在某些情况下,这使得无状态会话更容易处理和推理,但需要注意的是,无状态会话更容易受到数据别名影响,因为可以轻松得到两个非标识的 Java 对象,它们都表示同一数据库表的一行。
如果我们在无状态会话中使用 fetch(),我们可以非常轻松地得到表示同一数据库行的两个对象!
特别是,没有持久性上下文意味着我们可以安全地执行批量处理任务,而无需分配大量内存。使用 StatelessSession 减轻了调用它的需求:
-
_clear()_或 _detach()_执行一级缓存管理,且
-
_setCacheMode()_绕过与二级缓存的交互。
无状态会话可能很有用,但对于庞大数据集的批量操作,Hibernate 根本无法与存储过程竞争!
=== 7.15. Optimistic and pessimistic locking
最后,我们没有在上面提到的受载期间行为的一个方面是行级别数据争用。当许多事务尝试读取和更新相同数据时,程序可能会因锁升级、死锁和锁获取超时错误而失去响应。
Hibernate 中有两种基本的数据并发方法:
-
使用 _@Version_列进行乐观锁定,并
-
使用 SQL _for update_语法(或等效语法)进行数据库级悲观锁定。
在 Hibernate 社区中,使用乐观锁定更常见,而 Hibernate 让这件事变得非常容易。
在多用户系统中若有可能的话,避免跨用户交互持有一个悲观锁。事实上,一般的做法是避免使用跨越用户交互的事务。对于多用户系统,乐观锁是王者。
也就是说,那里 is 也有悲观锁,它有时可以降低事务回滚的可能性。
因此,响应会话的 find() 、 lock() 和 refresh() 方法接受一个可选的 LockMode 。我们还可以为查询指定一个 LockMode 。锁定模式可用于请求悲观锁定或自定乐观锁定的行为:
表 57. 乐观和悲观锁模式
LockMode type |
Meaning |
READ |
当使用 select 从数据库中读取实体时,隐式获取乐观锁 |
OPTIMISTIC |
当从数据库中读取实体时获取乐观锁,并在交易完成时使用 select 检查版本进行验证 |
OPTIMISTIC_FORCE_INCREMENT |
当从数据库中读取实体时获取乐观锁,并在交易完成时使用 update 增量版本进行强制执行 |
WRITE |
当使用 update 或 insert 将实体写入数据库时,隐式获取悲观锁 |
PESSIMISTIC_READ |
一个悲观 for share 锁 |
PESSIMISTIC_WRITE |
一个悲观 for update 锁 |
PESSIMISTIC_FORCE_INCREMENT |
使用立即 update 强制增量版本的悲观锁 |
NONE |
没有锁定; 当从二级缓存中读取实体时分配 |
请注意,即使实体未经修改,OPTIMISTIC 锁也会始终在事务结束时进行验证。这与大多数人谈论“乐观锁”时的意思略有不同。从不必要在已修改实体上请求 OPTIMISTIC 锁,因为版本号总是在执行 SQL update 时进行验证。
JPA 有自己的 LockModeType,它列举了大部分相同的模式。但是,JPA 的 LockModeType.READ 是 OPTIMISTIC 的同义词,它与 Hibernate 的 LockMode.READ 不同。同样,LockModeType.WRITE 是 OPTIMISTIC_FORCE_INCREMENT 的同义词,与 LockMode.WRITE 不同。
=== 7.16. Collecting statistics
我们可以通过设置此配置属性来让 Hibernate 收集其活动相关统计信息:
Configuration property name |
Property value |
hibernate.generate_statistics |
true 以启用统计信息收集 |
这些统计数据由 Statistics 对象公开:
long failedVersionChecks =
sessionFactory.getStatistics()
.getOptimisticFailureCount();
long publisherCacheMissCount =
sessionFactory.getStatistics()
.getEntityStatistics(Publisher.class.getName())
.getCacheMissCount()Hibernate 的统计信息支持可观察性。 Micrometer 和 SmallRye Metrics 都能够公开这些指标。
=== 7.17. Tracking down slow queries
当在生产环境中发现某个 SQL 查询性能欠佳时,有时很难准确地跟踪到查询的 Java 代码位于何处。Hibernate 提供了两个可以使识别缓慢查询及其来源变得更简单的配置属性。
表 58. 跟踪慢查询的设置
Configuration property name |
Purpose |
Property value |
hibernate.log_slow_query |
记录 INFO 级别上的缓慢查询 |
表征“慢”查询的最低执行时间(以毫秒为单位) |
hibernate.use_sql_comments |
在已执行的 SQL 前添加注释 |
true or false |
当 hibernate.use_sql_comments 启用时,HQL 查询的文本会作为注释添加到生成的 SQL 前面,这通常可以让用户轻松地在 Java 代码中找到 HQL。
可以自定义注释文本:
-
通过调用_Query.setComment(comment)或_Query.setHint(AvailableHints.HINT_COMMENT,comment),或者
-
via the @NamedQuery annotation.
一旦确定了速度较慢的查询,让查询速度更快的最佳方法之一就是 actually go and talk to someone who is an expert at making queries go fast。这些人被称为“数据库管理员”,如果您正在阅读此文档,您可能不是其中之一。数据库管理员了解大量 Java 开发人员不知道的东西。因此,如果足够幸运能有数据库管理员,您就不必依靠邓宁-克鲁格效应来解决查询速度较慢的问题。
一个专业定义的索引可能是修复慢查询所需的一切。
=== 7.18. Adding indexes
@Index 注释可用于向表格添加索引:
@Entity
@Table(indexes=@Index(columnList="title, year, publisher_id"))
class Book { ... }甚至可以为编制索引的列指定排序,或者指定索引应该不区分大小写:
@Entity
@Table(indexes=@Index(columnList="(lower(title)), year desc, publisher_id"))
class Book { ... }这使我们可以为特定查询创建自定义索引。
请注意,诸如 lower(title) 的 SQL 表达式必须用括号括起来放在索引定义的 columnList 中。
对于 Java 代码的注释中是否应包含有关索引的信息这一点尚不确定。索引通常由数据库管理员维护和修改,理想情况下是由精通优化特定 RDBMS 性能的专家进行维护和修改。因此,最好将索引定义保留在 SQL DDL 脚本中,以便 DBA 轻松读取和修改。 Remember 中,我们可以使用属性 javax.persistence.schema-generation.create-script-source 要求 Hibernate 执行 DDL 脚本。
=== 7.19. Dealing with denormalized data
一个规范化架构中的典型关系数据库表只包含少数列,因此,有选择地查询列并只填充实体类的某些字段几乎没有好处。
但是偶尔,我们听到有人询问如何映射有数百列或更多列的表!这种情况可能在以下情况下出现:
-
数据预先被非规范化(以提高性能),
-
复杂分析查询的结果通过视图公开,或者
-
有人做了件疯狂又错事。
我们假设我们正在_not_处理最后的可能性。那么我们希望能够查询该巨型表,而不返回其所有列。乍一看,Hibernate 并不能为该问题提供完美的瓶装解决方案。这种第一印象是误导。实际上,Hibernate 提供了多种应对这种情况的方法,而真正的问题在于如何在这些方法之间进行选择。我们可以:
-
将多个实体类映射到相同表或视图,谨慎处理“重叠”(其中一个可变列映射到多个实体),
-
使用 HQL或 native SQL,返回 results into record types的查询,而不是检索实体实例,或者
-
此示例中用到 bytecode enhancer 和 @LazyGroup 的属性级延迟提取。
其他一些 ORM 解决方案将第三个选项作为处理巨型表的推荐方法,但这一直不是 Hibernate 团队或 Hibernate 社区的偏好。使用前两个选项中的一个更加类型安全。
=== 7.20. Reactive programming with Hibernate
最后,现在许多需要高可扩展性的系统都会使用反应式编程和反应式流。 Hibernate Reactive 将 O/R 映射引入反应式编程的世界。你可以从其 Reference Documentation 了解更多有关 Hibernate Reactive 的信息。
Hibernate Reactive 可以与同一程序中的原生 Hibernate 一起使用,并且可以重复使用相同的实体类。这意味着您可以在需要的地方使用响应式编程模型,或许仅仅在您系统中的一个或两个位置。您不必使用响应式流重写整个程序。