Data Science 简明教程
Data Science - Getting Started
数据科学是从数据中提取和分析有用信息以解决难以通过分析解决的问题的过程。例如,当你访问一个电子商务网站,在购买之前查看一些类别和产品时,你正在创建分析师可以用来弄清楚你是如何进行购买的数据。
Data Science is the process of extracting and analysing useful information from data to solve problems that are difficult to solve analytically. For example, when you visit an e-commerce site and look at a few categories and products before making a purchase, you are creating data that Analysts can use to figure out how you make purchases.
它涉及不同的学科,例如数学和统计建模,从其来源中提取数据和应用数据可视化技术。它还涉及处理大数据技术以收集结构化和非结构化数据。
It involves different disciplines like mathematical and statistical modelling, extracting data from its source and applying data visualization techniques. It also involves handling big data technologies to gather both structured and unstructured data.
它可以帮助你找到隐藏在原始数据中的模式。术语“数据科学”已经演变,因为数学统计、数据分析和“大数据”已经随着时间而改变。
It helps you find patterns that are hidden in the raw data. The term "Data Science" has evolved because mathematical statistics, data analysis, and "big data" have changed over time.
数据科学是一个跨学科领域,它让你可以从有组织和无组织的数据中学习。利用数据科学,你可以将业务问题转化为研究项目,然后将其应用到实际解决方案中。
Data Science is an interdisciplinary field that lets you learn from both organised and unorganised data. With data science, you can turn a business problem into a research project and then apply into a real-world solution.
History of Data Science
约翰·图基在 1962 年使用术语“数据分析”来定义一个类似于当前现代数据科学的领域。在 1985 年对北京中国科学院的演讲中,C·F·杰夫·吴首次将短语“数据科学”作为统计的替代词。随后,在 1992 年于蒙彼利埃第二大学举办的会议上,从事统计工作的参与者认识到一个以多种来源和形式的数据为中心的新领域诞生,将统计和数据分析的已知思想和原则与计算机相结合。
John Tukey used the term "data analysis" in 1962 to define a field that resembled current modern data science. In a 1985 lecture to the Chinese Academy of Sciences in Beijing, C. F. Jeff Wu introduced the phrase "Data Science" as an alternative word for statistics for the first time. Subsequently, conference held at the University of Montpellier II in 1992 participants at a statistics recognised the birth of a new field centred on data of many sources and forms, integrating known ideas and principles of statistics and data analysis with computers.
彼得·诺尔在 1974 年建议将“数据科学”作为计算机科学的替代名称。国际分类学会联合会是第一个将数据科学作为专门主题予以突出的会议,是在 1996 年。然而,这个概念仍然在变化中。继在北京中国科学院的 1985 年的演讲后,C·F·杰夫·吴再次倡导在 1997 年将统计学更名为数据科学。他的理由是,一个新名称将有助于统计学摆脱不准确的刻板印象和观念,例如与会计有关或仅限于数据描述。林知己在 1998 年提出数据科学是一个包含数据设计、数据收集和数据分析三个组成部分的新型多学科概念。
Peter Naur suggested the phrase "Data Science" as an alternative name for computer science in 1974. The International Federation of Classification Societies was the first conference to highlight Data Science as a special subject in 1996. Yet, the concept remained in change. Following the 1985 lecture at the Chinese Academy of Sciences in Beijing, C. F. Jeff Wu again advocated for the renaming of statistics to Data Science in 1997. He reasoned that a new name would assist statistics in inaccurate stereotypes and perceptions, such as being associated with accounting or confined to data description. Hayashi Chikio proposed Data Science in 1998 as a new, multidisciplinary concept with three components: data design, data collecting, and data analysis.
在 20 世纪 90 年代,“知识发现”和“数据挖掘”是识别因数据集不断增长而产生的模式的过程的流行短语。
In the 1990s, "knowledge discovery" and "data mining" were popular phrases for the process of identifying patterns in datasets that were growing in size.
在 2012 年,工程师托马斯·H·戴文波特和 DJ·帕蒂尔宣称“数据科学家:21 世纪最热门的工作。”这个术语被纽约时报和波士顿环球报等主要都市出版物所采用。十年后,他们又重复了这一点,并补充说“这个职位的需求比以往任何时候都大。”
In 2012, engineers Thomas H. Davenport and DJ Patil proclaimed "Data Scientist: The Hottest Job of the 21st Century," a term that was taken up by major metropolitan publications such as the New York Times and the Boston Globe. They repeated it a decade later, adding that "the position is in more demand than ever"
威廉·S·克利夫兰经常与数据科学作为独立领域的当前理解联系在一起。在 2001 年的一项研究中,他主张将统计学发展为技术领域;由于这将从根本上改变科目,因此需要一个新名称。在随后的几年中,“数据科学”变得越来越流行。在 2002 年,科学技术数据委员会出版了《数据科学杂志》。哥伦比亚大学于 2003 年创办了《数据科学杂志》。美国统计协会的统计学习和数据挖掘部分在 2014 年更名为统计学习和数据科学部分,反映了数据科学越来越受欢迎。
William S. Cleveland is frequently associated with the present understanding of Data Science as a separate field. In a 2001 study, he argued for the development of statistics into technological fields; a new name was required as this would fundamentally alter the subject. In the following years, "Data Science" grew increasingly prevalent. In 2002, the Council on Data for Science and Technology published Data Science Journal. Columbia University established The Journal of Data Science in 2003. The Section on Statistical Learning and Data Mining of the American Statistical Association changed its name to the Section on Statistical Learning and Data Science in 2014, reflecting the growing popularity of Data Science.
在 2008 年,DJ·帕蒂尔和杰夫·哈默巴赫获得了“数据科学家”的专业资格。尽管国家科学委员会在他们 2005 年的研究“长期数字数据收集:支持 21 世纪的研究和教学”中使用了这个术语,但它指的是在管理数字数据收集方面任何重要的角色。
In 2008, DJ Patil and Jeff Hammerbacher were given the professional designation of "data scientist." Although it was used by the National Science Board in their 2005 study "Long-Lived Digital Data Collections: Supporting Research and Teaching in the 21st Century," it referred to any significant role in administering a digital data collection.
对于“数据科学”的含义尚未达成共识,而且一些人认为它是一个流行语。大数据在营销中是一个类似的概念。数据科学家负责将海量数据转化为有用信息,并开发软件和算法,以帮助企业和机构确定最佳运营。
An agreement has not yet been reached on the meaning of Data Science, and some believe it to be a buzzword. Big data is a similar concept in marketing. Data scientists are responsible for transforming massive amounts of data into useful information and developing software and algorithms that assist businesses and organisations in determining optimum operations.
Why Data Science?
据 IDC 称,到 2025 年,全球数据将达到 175 泽字节。数据科学帮助企业了解来自不同来源的海量数据,提取有用的见解,并做出更好的数据驱动决策。数据科学广泛应用于多个工业领域,例如营销、医疗保健、金融、银行和政策制定。
According to IDC, worldwide data will reach 175 zettabytes by 2025. Data Science helps businesses to comprehend vast amounts of data from different sources, extract useful insights, and make better data-driven choices. Data Science is used extensively in several industrial fields, such as marketing, healthcare, finance, banking, and policy work.
以下是使用数据分析技术的重要优势:-
Here are significant advantages of using Data Analytics Technology −
-
Data is the oil of the modern age. With the proper tools, technologies, and algorithms, we can leverage data to create a unique competitive edge.
-
Data Science may assist in detecting fraud using sophisticated machine learning techniques.
-
It helps you avoid severe financial losses.
-
Enables the development of intelligent machines
-
You may use sentiment analysis to determine the brand loyalty of your customers. This helps you to make better and quicker choices.
-
It enables you to propose the appropriate product to the appropriate consumer in order to grow your company.
Need for Data Science
The data we have and how much data we generate
根据福布斯的报道,2010 至 2020 年间,全球产生的、复制的、记录的和消耗的总数据量激增约 5,000%,从 1.2 万亿千兆字节增长到 59 万亿千兆字节。
According to Forbes, the total quantity of data generated, copied, recorded, and consumed in the globe surged by about 5,000% between 2010 and 2020, from 1.2 trillion gigabytes to 59 trillion gigabytes.
How companies have benefited from Data Science?
-
Several businesses are undergoing data transformation (converting their IT architecture to one that supports Data Science), there are data boot camps around, etc. Indeed, there is a straightforward explanation for this: Data Science provides valuable insights.
-
Companies are being outcompeted by firms that make judgments based on data. For example, the Ford organization in 2006, had a loss of $12.6 billion. Following the defeat, they hired a senior data scientist to manage the data and undertook a three-year makeover. This ultimately resulted in the sale of almost 2,300,000 automobiles and earned a profit for 2009 as a whole.
Demand and Average Salary of a Data Scientist
-
According to India Today, India is the second biggest centre for Data Science in the world due to the fast digitalization of companies and services. By 2026, analysts anticipate that the nation will have more than 11 million employment opportunities. In fact, recruiting in the Data Science field has surged by 46% since 2019.
-
Bank of America was one of the first financial institutions to provide mobile banking to its consumers a decade ago. Recently, the Bank of America introduced Erica, its first virtual financial assistant. It is regarded the as best financial invention in the world. Erica now serves as a client adviser for more than 45 million consumers worldwide. Erica uses Voice Recognition to receive client feedback, which represents a technical development in Data Science.
-
The Data Science and Machine Learning curves are steep. Although India sees a massive influx of data scientists each year, relatively few possess the needed skill set and specialization. As a consequence, people with specialised data skills are in great demand.
Impact of Data Science
数据科学对现代文明的各个方面产生了重大影响。数据科学对组织的重要性不断提高。根据一项调查,到 2023 年,数据科学的全球市场将达到 1150 亿美元。
Data Science has had a significant influence on several aspects of modern civilization. The significance of Data Science to organisations keeps on increasing. According to one research, the worldwide market for Data Science would reach $115 billion by 2023.
医疗保健行业受益于数据科学的兴起。2008 年,谷歌员工意识到他们可以实时监控流感毒株。以前的只能每周提供一次实例更新。谷歌能够利用数据科学构建出首批用于监测疾病传播的系统。
Healthcare industry has benefited from the rise of Data Science. In 2008, Google employees realised that they could monitor influenza strains in real time. Previous technologies could only provide weekly updates on instances. Google was able to build one of the first systems for monitoring the spread of diseases by using Data Science.
体育产业也同样受益于数据科学。2019 年,一位数据科学家找到了方法来衡量和计算进球尝试如何增加足球队的取胜几率。事实上,数据科学被用于轻松计算多种体育项目的统计数据。
The sports sector has similarly profited from data science. A data scientist in 2019 found ways to measure and calculate how goal attempts increase a soccer team’s odds of winning. In reality, data science is utilised to easily compute statistics in several sports.
政府机构也每天都在使用数据科学。全球各国的政府使用数据库监控有关社保、税收以及有关其居民的其他数据的信息。政府对新兴技术的使用不断发展。
Government agencies also use data science on a daily basis. Governments throughout the globe employ databases to monitor information regarding social security, taxes, and other data pertaining to their residents. The government’s usage of emerging technologies continues to develop.
由于互联网已成为人类交流的主要媒介,因此电子商务的普及度也在增加。利用数据科学,在线企业可以监控整个客户体验,包括营销活动、购买和消费者趋势。广告必须是电商企业使用数据科学的最大实例之一。您是否曾在网上搜索过某些内容或访问过电商产品网站,却发现社交网站和博客上充斥着该产品的广告?
Since the Internet has become the primary medium of human communication, the popularity of e-commerce has also grown. With data science, online firms may monitor the whole of the customer experience, including marketing efforts, purchases, and consumer trends. Ads must be one of the greatest instances of eCommerce firms using data science. Have you ever looked for anything online or visited an eCommerce product website, only to be bombarded by advertisements for that product on social networking sites and blogs?
广告像素对于在线收集和分析用户信息至关重要。企业利用在线消费者行为通过因特网重新投放目标消费者。这种对客户信息的利用超出了电子商务的范畴。诸如 Tinder 和 Facebook 等应用使用算法帮助用户找到他们想要找的内容。互联网是一个不断增长的数据宝库,收集和分析数据也将继续增长。
Ad pixels are integral to the online gathering and analysis of user information. Companies leverage online consumer behaviour to retarget prospective consumers throughout the internet. This usage of client information extends beyond eCommerce. Apps such as Tinder and Facebook use algorithms to assist users locate precisely what they are seeking. The Internet is a growing treasure trove of data, and the gathering and analysis of this data will also continue to expand.
Data Science - What is Data?
What is Data in Data Science?
数据是数据科学的基础。数据是对指定字符的系统记录、数量或符号,计算机对此执行操作,这些数据可以存储和传输。它是用于特定目的的数据汇编,例如调查或分析。当数据被结构化时,可以将该数据称为信息。数据源(原始数据、次要数据)也是需要考虑的重要因素。
Data is the foundation of data science. Data is the systematic record of a specified characters, quantity or symbols on which operations are performed by a computer, which may be stored and transmitted. It is a compilation of data to be utilised for a certain purpose, such as a survey or an analysis. When structured, data may be referred to as information. The data source (original data, secondary data) is also an essential consideration.
数据有许多形状和形式,但通常可以认为是某种随机实验的结果——一个无法预先确定结果,但其工作原理仍然受分析约束的实验。来自随机实验的数据通常存储在表格或电子表格中。用来表示变量的统计惯例通常称为特征或列,而将单个项目(或单位)称为行。
Data comes in many shapes and forms, but can generally be thought of as being the result of some random experiment - an experiment whose outcome cannot be determined in advance, but whose workings are still subject to analysis. Data from a random experiment are often stored in a table or spreadsheet. A statistical convention to denote variables is often called as features or columns and individual items (or units) as rows.
Types of Data
主要有两类数据,分别是:
There are mainly two types of data, they are −
Qualitative Data
定性数据由无法计算、量化或仅用数字表示的信息组成。它从文本、音频和图片中收集,并使用数据可视化工具进行分布,包括词云、概念图、图形数据库、时间线和信息图表。
Qualitative data consists of information that cannot be counted, quantified, or expressed simply using numbers. It is gathered from text, audio, and pictures and distributed using data visualization tools, including word clouds, concept maps, graph databases, timelines, and infographics.
定性数据分析的目标是回答有关个人活动和动机的问题。收集和分析此类数据可能需要花费很多时间。处理定性数据的研究员或分析师被称为定性研究员或分析师。
The objective of qualitative data analysis is to answer questions about the activities and motivations of individuals. Collecting, and analyzing this kind of data may be time-consuming. A researcher or analyst that works with qualitative data is referred to as a qualitative researcher or analyst.
定性数据可以为任何部门、用户群体或产品提供重要统计信息。
Qualitative data can give essential statistics for any sector, user group, or product.
Types of Qualitative Data
主要有两类定性数据,分别是:
There are mainly two types of Qualitative data, they are −
@[s0}
Nominal Data
在统计中,名义数据(也称为名义标度)用于指定变量,而不提供数值。它是基本测量标度的最基本类型。与序数数据相反,名义数据无法排序或量化。
In statistics, nominal data (also known as nominal scale) is used to designate variables without giving a numerical value. It is the most basic type of measuring scale. In contrast to ordinal data, nominal data cannot be ordered or quantified.
例如,一个人的姓名、头发颜色、国籍等。让我们假设一位名叫 Aby 的女孩头发是棕色的,她来自美国。
For example, The name of the person, the colour of the hair, nationality, etc. Let’s assume a girl named Aby her hair is brown and she is from America.
名义数据既可以是定性的,也可以是定量的。然而,定量标签(例如识别号)没有任何数值或链接与之关联。相反,可以以名义形式表达多个定性数据类别。这些可能包括单词、字母和符号。个人姓名、性别和国籍是最流行的名义数据实例。
Nominal data may be both qualitative and quantitative. Yet, there is no numerical value or link associated with the quantitative labels (e.g., identification number). In contrast, several qualitative data categories can be expressed in nominal form. These might consist of words, letters, and symbols. Names of individuals, gender, and nationality are some of the most prevalent instances of nominal data.
@[s1}
Analyze Nominal Data
可以使用分组方法分析名义数据。变量可以按组排序,并且可以确定每个类别的频率或百分比。此外还可以以图形方式显示数据,例如使用饼图。
Using the grouping approach, nominal data can be analyzed. The variables may be sorted into groups, and the frequency or percentage can be determined for each category. The data may also be shown graphically, for example using a pie chart.
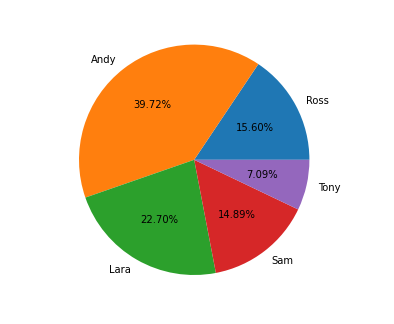
尽管名义数据不能使用数学运算符处理,但仍可以使用统计技术对其进行研究。假设检验是评估和分析数据的其中一种方法。
Although though nominal data cannot be processed using mathematical operators, they may still be studied using statistical techniques. Hypothesis testing is one approach to assess and analyse the data.
使用名义数据,可以使用卡方检验等非参数检验来检验假设。卡方检验的目的是评估给定值的预测频率和实际频率之间是否存在统计上显着的差异。
With nominal data, nonparametric tests such as the chi-squared test may be used to test hypotheses. The purpose of the chi-squared test is to evaluate whether there is a statistically significant discrepancy between the predicted frequency and the actual frequency of the provided values.
@[s2}
Ordinal Data
序数数据是统计数据中的一种数据类型,其中值按自然顺序排列。序数数据最重要的一点是,您无法区分数据值之间的差异。大多数情况下,数据类别的宽度与底层属性的增量不匹配。
Ordinal data is a type of data in statistics where the values are in a natural order. One of the most important things about ordinal data is that you can’t tell what the differences between the data values are. Most of the time, the width of the data categories doesn’t match the increments of the underlying attribute.
在某些情况下,可以通过对数据的值进行分组来找到间隔数据或比率数据的特征。例如,收入范围是序数数据,而实际收入是比率数据。
In some cases, the characteristics of interval or ratio data can be found by grouping the values of the data. For instance, the ranges of income are ordinal data, while the actual income is ratio data.
序数数据不能像间隔或比率数据一样使用数学运算符进行更改。因此,中位数是找出序数数据集中间位置的唯一方法。
Ordinal data can’t be changed with mathematical operators like interval or ratio data can. Because of this, the median is the only way to figure out where the middle of a set of ordinal data is.
此数据类型广泛存在于金融和经济领域。考虑一下一项研究各个国家 GDP 水平的经济研究。如果该报告根据各个国家的 GDP 对其进行评级,则排名就是序数统计数据。
This data type is widely found in the fields of finance and economics. Consider an economic study that examines the GDP levels of various nations. If the report rates the nations based on their GDP, the rankings are ordinal statistics.
@[s3}
Analyzing Ordinal Data
使用可视化工具评估有序数据是最简单的方法。例如,该数据可以显示为一个表格,其中每一行代表一个独立的类别。此外,它们可以使用不同的图表进行图形化表示。条形图是用来显示此类数据最流行的图形样式。
Using visualisation tools to evaluate ordinal data is the easiest method. For example, the data may be displayed as a table where each row represents a separate category. In addition, they may be represented graphically using different charts. The bar chart is the most popular style of graph used to display these types of data.
有序数据也可以使用假设检验等复杂的统计分析方法进行研究。需要注意的是,t 检验和 ANOVA 等参数化过程不能用于这些数据集。只有非参数检验(如曼惠特尼 U 检验或威尔科克森配对检验)可以用来评估关于数据的空假设。
Ordinal data may also be studied using sophisticated statistical analysis methods like hypothesis testing. Note that parametric procedures such as the t-test and ANOVA cannot be used to these data sets. Only nonparametric tests, such as the Mann-Whitney U test or Wilcoxon Matched-Pairs test, may be used to evaluate the null hypothesis about the data.
Qualitative Data Collection Methods
以下是一些收集定性数据的方法和收集方法——
Below are some approaches and collection methods to collect qualitative data −
-
Data Records − Utilizing data that is already existing as the data source is a best technique to do qualitative research. Similar to visiting a library, you may examine books and other reference materials to obtain data that can be utilised for research.
-
Interviews − Personal interviews are one of the most common ways to get deductive data for qualitative research. The interview may be casual and not have a set plan. It is often like a conversation. The interviewer or researcher gets the information straight from the interviewee.
-
Focus Groups − Focus groups are made up of 6 to 10 people who talk to each other. The moderator’s job is to keep an eye on the conversation and direct it based on the focus questions.
-
Case Studies − Case studies are in-depth analyses of an individual or group, with an emphasis on the relationship between developmental characteristics and the environment.
-
Observation − It is a technique where the researcher observes the object and take down transcript notes to find out innate responses and reactions without prompting.
Quantitative Data
定量数据由数值组成,具有数值特征,并且可以对这种类型的数据执行数学运算,例如加法。定量数据由于其定量特性而具有数学可验证性和可评估性。
Quantitative data consists of numerical values, has numerical features, and mathematical operations can be performed on this type of data such as addition. Quantitative data is mathematically verifiable and evaluable due to its quantitative character.
它们数学导出的简单性使得管理不同参数的测量成为可能。通常,它是通过授予人群一部分的问卷调查、民意调查或调查来收集的,用于统计分析。研究人员能够将收集到的研究结果应用于整个人群。
The simplicity of their mathematical derivations makes it possible to govern the measurement of different parameters. Typically, it is gathered for statistical analysis through surveys, polls, or questionnaires given to a subset of a population. Researchers are able to apply the collected findings to an entire population.
Types of Quantitative Data
定量数据主要有两种类型,它们是——
There are mainly two types of quantitative data, they are −
Discrete Data
Discrete Data
这些是只能采用特定值的数据,而不是范围。例如,有关人群血型或性别的信息被视为离散数据。
These are data that can only take on certain values, as opposed to a range. For instance, data about the blood type or gender of a population is considered discrete data.
离散定量数据的示例可能是您网站的访问者数量;一天可能有 150 次访问,但不可能有 150.6 次访问。通常,饼状图、条形图和饼图用于表示离散数据。
Example of discrete quantitative data may be the number of visitors to your website; you could have 150 visits in one day, but not 150.6 visits. Usually, tally charts, bar charts, and pie charts are used to represent discrete data.
Characteristics of Discrete Data
Characteristics of Discrete Data
由于总结和计算离散数据很简单,因此它通常用于基本的统计分析。让我们检查一下离散数据的一些其他基本特征——
Since it is simple to summarise and calculate discrete data, it is often utilized in elementary statistical analysis. Let’s examine some other essential characteristics of discrete data −
-
Discrete data is made up of discrete variables that are finite, measurable, countable, and can’t be negative (5, 10, 15, and so on).
-
Simple statistical methods, like bar charts, line charts, and pie charts, make it easy to show and explain discrete data.
-
Data can also be categorical, which means it has a fixed number of data values, like a person’s gender.
-
Data that is both time- and space-bound is spread out in a random way. Discrete distributions make it easier to look at discrete values.
Continuous Data
这些数据可能在一定范围内取值,包括最大值和最小值。最大值和最小值之间的差称为数据范围。例如,你学校学生的身高和体重。这被认为是连续数据。连续数据的表格表示称为频数分布。这些可以利用直方图直观地描述。
These are data that may take values between a certain range, including the greatest and lowest possible. The difference between the greatest and least value is known as the data range. For instance, the height and weight of your school’s children. This is considered continuous data. The tabular representation of continuous data is known as a frequency distribution. These may be depicted visually using histograms.
Characteristics of continuous data
Characteristics of continuous data
另一方面,连续数据可以是数字,或者随时间和日期变化。由于可能的值是无限的,所以此数据类型使用高级的统计分析方法。连续数据的以下重要特征 −
Continuous data, on the other hand, can be either numbers or spread out over time and date. This data type uses advanced statistical analysis methods because there are an infinite number of possible values. The important characteristics about continuous data are −
-
Continuous data changes over time, and at different points in time, it can have different values.
-
Random variables, which may or may not be whole numbers, make up continuous data.
-
Data analysis tools like line graphs, skews, and so on are used to measure continuous data.
-
One type of continuous data analysis that is often used is regression analysis.
Quantitative Data Collection Methods
下面是一些用于收集定量数据的方法和采集方法 −
Below are some approaches and collection methods to collect quantitative data −
-
Surveys and Questionnaires − These types of research are good for getting detailed feedback from users and customers, especially about how people feel about a product, service, or experience.
-
Open-source Datasets − There are a lot of public datasets that can be found online and analysed for free. Researchers sometimes look at data that has already been collected and try to figure out what it means in a way that fits their own research project.
-
Experiments − A common method is an experiment, which usually has a control group and an experimental group. The experiment is set up so that it can be controlled and the conditions can be changed as needed.
-
Sampling − When there are a lot of data points, it may not be possible to survey each person or data point. In this case, quantitative research is done with the help of sampling. Sampling is the process of choosing a sample of data that is representative of the whole. The two types of sampling are Random sampling (also called probability sampling), and non-random sampling.
Types of Data Collection
根据来源,数据收集可以分为两类 −
Data collection can be classified into two types according to the source −
-
Primary Data − These are the data that are acquired for the first time for a particular purpose by an investigator. Primary data are 'pure' in the sense that they have not been subjected to any statistical manipulations and are authentic. Examples of primary data include the Census of India.
-
Secondary Data − These are the data that were initially gathered by a certain entity. This indicates that this kind of data has already been gathered by researchers or investigators and is accessible in either published or unpublished form. This data is impure because statistical computations may have previously been performed on it. For example, Information accessible on the website of the Government of India or the Department of Finance, or in other archives, books, journals, etc.
Big Data
大数据被定义为具有更大数据量的数据,需要克服后勤方面的挑战来处理它们。大数据指的是更大、更复杂的数据集合,特别是来自新型数据源的数据。一些数据集非常庞大,以至于传统的的数据处理软件无法处理它们。然而,这些海量数据可以用来解决以前无法解决的业务难题。
Big data is defined as data with a larger volume and require overcoming logistical challenges to deal with them. Big data refers to bigger, more complicated data collections, particularly from novel data sources. Some data sets are so extensive that conventional data processing software is incapable of handling them. But, these vast quantities of data can be use to solve business challenges that were previously unsolvable.
数据科学是关于如何分析巨量数据并从中获取信息的研究。你可以将大数据和数据科学比作原油和炼油厂。数据科学和大数据源于统计学和传统的数据管理方式,但现在被视为独立的领域。
Data Science is the study of how to analyse huge amount of data and get the information from them. You can compare big data and data science to crude oil and an oil refinery. Data Science and big data grew out of statistics and traditional ways of managing data, but they are now seen as separate fields.
人们常常使用三个 V 来描述大数据的特性 −
People often use the three Vs to describe the characteristics of big data −
-
Volume − How much information is there?
-
Variety − How different are the different kinds of data?
-
Velocity − How fast do new pieces of information get made?
How do we use Data in Data Science?
每条数据都必须经过预处理。这是一系列将原始数据转换为更易理解且有价值的格式以供进一步处理的基本流程。常见流程为−
Every data must undergo pre-processing. This is an essential series of processes that converts raw data into a more comprehensible and valuable format for further processing. Common procedures are −
-
Collect and Store the Dataset
-
Data Cleaning
-
Data Integration
-
Data Transformation
我们将在接下来的章节中详细讨论这些流程。
We will discuss these processes in detail in upcoming chapters.
Data Science - Lifecycle
What is Data Science Lifecycle?
数据科学生命周期是一种寻找数据问题的解决方案的系统方法,它显示了开发、交付/部署和维护数据科学项目所需的步骤。我们可以假设一个通用数据科学生命周期,其中包含一些最重要的常见步骤,如下面的图片所示,但由于每个项目不同,因此某些步骤可能因项目而异,因为并非每个数据科学项目都是以相同的方式构建的
A data science lifecycle is a systematic approach to find a solution for a data problem which shows the steps that are taken to develop, deliver/deploy , and maintain a data science project. We can assume a general data science lifecycle with some of the most important common steps that is shown in the figure given below but some steps may differ from project to project as each project is different so life cycle may differ since not every data science project is built the same way
一种标准数据科学生命周期方法包括使用机器学习算法和统计程序,这些程序会产生更准确的预测模型。数据提取、准备、清理、建模、评估等,是数据科学中最重要的阶段。这种技术在数据科学领域被称为“数据挖掘的跨行业标准程序”。
A standard data science lifecycle approach comprises the use of machine learning algorithms and statistical procedures that result in more accurate prediction models. Data extraction, preparation, cleaning, modelling, assessment, etc., are some of the most important data science stages. This technique is known as "Cross Industry Standard Procedure for Data Mining" in the field of data science.
How many phases are there in the Data Science Life Cycle?
数据科学生命周期主要有六个阶段−
There are mainly six phases in Data Science Life Cycle −

Identifying Problem and Understanding the Business
数据科学生命周期从“为什么?”开始,就像任何其他业务生命周期一样。数据科学过程中最重要的部分之一是找出问题所在。这有助于找到一个明确的目标,可以围绕该目标制定所有其他步骤。简而言之,尽早了解业务目标非常重要,因为它将决定分析的最终目标。
The data science lifecycle starts with "why?" just like any other business lifecycle. One of the most important parts of the data science process is figuring out what the problem is. This helps to find a clear goal around which all the other steps can be planned out. In short, it’s important to know the business goal as earliest because it will determine what the end goal of the analysis will be.
此阶段应评估业务趋势、评估可比分析的案例研究,并研究行业领域。该组将根据可用的员工、设备、时间和技术评估项目的可行性。一旦发现并评估了这些因素,将制定一个初步假设来解决现有环境造成的业务问题。本阶段应−
This phase should evaluate the trends of business, assess case studies of comparable analyses, and research the industry’s domain. The group will evaluate the feasibility of the project given the available employees, equipment, time, and technology. When these factors been discovered and assessed, a preliminary hypothesis will be formulated to address the business issues resulting from the existing environment. This phrase should −
-
Specify the issue that why the problem must be resolved immediately and demands answer.
-
Specify the business project’s potential value.
-
Identify dangers, including ethical concerns, associated with the project.
-
Create and convey a flexible, highly integrated project plan.
Data Collection
数据科学生命周期的下一步是数据收集,这意味着从适当且可靠的来源获取原始数据。收集的数据可以是有序的,也可以是无序的。数据可以从网站日志、社交媒体数据、在线数据存储库中收集,甚至可以使用 API、网络抓取或可能存在于 Excel 或其他来源中的数据从在线来源流式传输数据。
The next step in the data science lifecycle is data collection, which means getting raw data from the appropriate and reliable source. The data that is collected can be either organized or unorganized. The data could be collected from website logs, social media data, online data repositories, and even data that is streamed from online sources using APIs, web scraping, or data that could be in Excel or any other source.
从事这项工作的人员应该了解可用的不同数据集之间的差异,以及组织如何投资其数据。专业人士很难追踪每条数据的来源,以及它是否是最新的。在数据科学项目整个生命周期内,追踪这些信息非常重要,因为它可以帮助验证假设或运行任何其他新实验。
The person doing the job should know the difference between the different data sets that are available and how an organization invests its data. Professionals find it hard to keep track of where each piece of data comes from and whether it is up to date or not. During the whole lifecycle of a data science project, it is important to keep track of this information because it could help test hypotheses or run any other new experiments.
信息可以通过调查或更流行的自动数据收集方法(如互联网 Cookie)收集,互联网 Cookie 是未经分析的数据的主要来源。
The information may be gathered by surveys or the more prevalent method of automated data gathering, such as internet cookies which is the primary source of data that is unanalysed.
我们还可以使用开放源数据集等辅助数据。我们可以从许多可用网站收集数据,例如
We can also use secondary data which is an open-source dataset. There are many available websites from where we can collect data for example
-
Kaggle (https://www.kaggle.com/datasets),
-
Google Public Datasets (https://cloud.google.com/bigquery/public-data/)
Python 中有一些预定义的数据集。让我们从 Python 中导入鸢尾花数据集,并使用它来定义数据科学的阶段。
There are some predefined datasets available in python. Let’s import the Iris dataset from python and use it to define phases of data science.
from sklearn.datasets import load_iris
import pandas as pd
# Load Data
iris = load_iris()
# Create a dataframe
df = pd.DataFrame(iris.data, columns = iris.feature_names)
df['target'] = iris.target
X = iris.dataData Processing
从可靠的来源收集到高质量的数据后,下一步是对其进行处理。数据处理的目的是确保所获取的数据中是否存在任何问题,以便在进入下一阶段之前解决这些问题。如果没有这一步,我们可能会产生错误或不准确的发现。
After collecting high-quality data from reliable sources, next step is to process it. The purpose of data processing is to ensure if there is any problem with the acquired data so that it can be resolved before proceeding to the next phase. Without this step, we may produce mistakes or inaccurate findings.
所获得的数据可能存在若干困难。例如,数据可能有多行或多列缺少若干值。它可能包含若干离群值、不准确的数字、具有不同时区的 timestamp 等。数据可能潜在地存在日期范围问题。在某些国家/地区,日期的格式为 DD/MM/YYYY,而在其他国家/地区,日期的格式为 MM/DD/YYYY。在数据收集过程中可能会出现许多问题,例如,如果从多个温度计中收集数据且其中任何一个出现故障,则可能需要丢弃或重新收集数据。
There may be several difficulties with the obtained data. For instance, the data may have several missing values in multiple rows or columns. It may include several outliers, inaccurate numbers, timestamps with varying time zones, etc. The data may potentially have problems with date ranges. In certain nations, the date is formatted as DD/MM/YYYY, and in others, it is written as MM/DD/YYYY. During the data collecting process numerous problems can occur, for instance, if data is gathered from many thermometers and any of them are defective, the data may need to be discarded or recollected.
在此阶段,必须解决与数据相关的各种问题。其中一些问题有多种解决方案,例如,如果数据包含缺失值,我们可以用零或列的平均值替换它们。不过,如果该列缺少大量值,则最好完全移除该列,因为它拥有太少数据而无法用于求解问题的数据科学生命周期的方法。
At this phase, various concerns with the data must be resolved. Several of these problems have multiple solutions, for example, if the data includes missing values, we can either replace them with zero or the column’s mean value. However, if the column is missing a large number of values, it may be preferable to remove the column completely since it has so little data that it cannot be used in our data science life cycle method to solve the issue.
当时区混乱时,我们无法使用这些列中的数据,可能必须将其移除,直至我们能够定义提供的时间戳中使用的时区。如果知道收集每个时间戳所用的时区,我们可能会将所有时间戳数据转换为某个时区。此种方式有许多策略可以解决所获取数据中可能存在的各种问题。
When the time zones are all mixed up, we cannot utilize the data in those columns and may have to remove them until we can define the time zones used in the supplied timestamps. If we know the time zones in which each timestamp was gathered, we may convert all timestamp data to a certain time zone. In this manner, there are a number of strategies to address concerns that may exist in the obtained data.
接下来我们将使用 Python 访问数据,然后将其存储在数据框内。
We will access the data and then store it in a dataframe using python.
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
# Load Data
iris = load_iris()
# Create a dataframe
df = pd.DataFrame(iris.data, columns = iris.feature_names)
df['target'] = iris.target
X = iris.data机器学习模型的所有数据都必须以数字表示。这意味着,如果数据集包含分类数据,则必须将其转换为数字值,然后才能执行模型。因此,我们将实施标签编码。
All data must be in numeric representation for machine learning models. This implies that if a dataset includes categorical data, it must be converted to numeric values before the model can be executed. So we will be implementing label encoding.
Label Encoding
Label Encoding
species = []
for i in range(len(df['target'])):
if df['target'][i] == 0:
species.append("setosa")
elif df['target'][i] == 1:
species.append('versicolor')
else:
species.append('virginica')
df['species'] = species
labels = np.asarray(df.species)
df.sample(10)
labels = np.asarray(df.species)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(labels)
labels = le.transform(labels)
df_selected1 = df.drop(['sepal length (cm)', 'sepal width (cm)', "species"], axis=1)Data Analysis
数据分析 探索性数据分析 (EDA) 是一组用于分析数据的可视化技术。采用此方法,我们可能会获取有关数据统计摘要的具体详细信息。此外,我们将能够处理重复数字、离群值,并在集合内找出趋势或模式。
Data analysis Exploratory Data Analysis (EDA) is a set of visual techniques for analysing data. With this method, we may get specific details on the statistical summary of the data. Also, we will be able to deal with duplicate numbers, outliers, and identify trends or patterns within the collection.
在此阶段,我们尝试对所获取和已处理的数据有更深入的理解。我们应用统计和分析技术对数据做出结论,并确定我们数据集中的多列之间的联系。借助图片、图表、流程图、绘图等,我们可以使用可视化来更好地理解和描述数据。
At this phase, we attempt to get a better understanding of the acquired and processed data. We apply statistical and analytical techniques to make conclusions about the data and determine the link between several columns in our dataset. Using pictures, graphs, charts, plots, etc., we may use visualisations to better comprehend and describe the data.
专业人员使用均值和中位数等数据统计技术来更好地理解数据。他们还使用直方图、频谱分析和总体分布来可视化数据并评估其分布模式。数据将根据问题进行分析。
Professionals use data statistical techniques such as the mean and median to better comprehend the data. Using histograms, spectrum analysis, and population distribution, they also visualise data and evaluate its distribution patterns. The data will be analysed based on the problems.
Example
以下代码用于检查数据集中是否存在任何空值:
Below code is used to check if there are any null values in the dataset −
df.isnull().sum()Output
sepal length (cm) 0
sepal width (cm) 0
petal length (cm) 0
petal width (cm) 0
target 0
species 0
dtype: int64从上述输出中我们可以得出结论,数据集中没有空值,因为列中所有空值的总和为 0。
From the above output we can conclude that there are no null values in the dataset as the sum of all the null values in the column is 0.
我们将使用 shape 参数来检查数据集的形状(行、列)。
We will be using shape parameter to check the shape (rows, columns) of the dataset −
Example
df.shapeOutput
(150, 5)接下来我们将使用 info() 检查列及其数据类型:
Now we will use info() to check the columns and their data types −
Example
df.info()Output
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
4 target 150 non-null int64
dtypes: float64(4), int64(1)
memory usage: 6.0 KB只有一列包含分类数据,而其他列包含非空数字值。
Only one column contains category data, whereas the other columns include non-Null numeric values.
现在我们将在数据上使用 describe()。describe() 方法对数据集执行基础统计计算,例如极值、数据点数量、标准偏差等。任何缺失值或 NaN 值都会立即被忽略。describe() 方法准确描绘了数据的分布。
Now we will use describe() on the data. The describe() method performs fundamental statistical calculations to a dataset, such as extreme values, the number of data points, standard deviation, etc. Any missing or NaN values are immediately disregarded. The describe() method accurately depicts the distribution of data.
Example
df.describe()Output

Data Visualization
Target column - 我们的目标列将是 Species 列,因为我们最终只需要基于物种的结果即可。
Target column − Our target column will be the Species column since we will only want results based on species in the end.
我们将使用 Matplotlib 和 seaborn 库进行数据可视化。
Matplotlib and seaborn library will be used for data visualization.
以下是物种计量图−
Below is the species countplot −
Example
import seaborn as sns
import matplotlib.pyplot as plt
sns.countplot(x='species', data=df, )
plt.show()Output

数据科学中还有许多其他可视化图。要了解更多信息,请参阅 https://www.tutorialspoint.com/machine_learning_with_python
There are many other visualization plots in Data Science. To know more about them refer https://www.tutorialspoint.com/machine_learning_with_python
Data Modeling
数据建模是数据科学中最重要的方面之一,有时被称为数据分析的核心。模型的预期输出应从已准备和分析的数据中得出。在达到指定标准之前,将选择并构建执行数据模型所需的模型。
Data Modeling is one of the most important aspects of data science and is sometimes referred to as the core of data analysis. The intended output of a model should be derived from prepared and analysed data. The environment required to execute the data model will be chosen and constructed, before achieving the specified criteria.
在这个阶段,我们将为生产相关任务开发数据集以对模型进行训练和测试。它还涉及选择正确的模式类型并确定问题是否涉及分类、回归或聚类。在分析模型类型后,我们必须选择适当的实现算法。必须仔细执行,因为从提供的数据中提取相关见解至关重要。
At this phase, we develop datasets for training and testing the model for production-related tasks. It also involves selecting the correct mode type and determining if the problem involves classification, regression, or clustering. After analysing the model type, we must choose the appropriate implementation algorithms. It must be performed with care, as it is crucial to extract the relevant insights from the provided data.
机器学习在这里发挥了作用。机器学习基本上分为分类、回归或聚类模型,每个模型都有一些算法应用于数据集以获取相关信息。这些模型用于此阶段。我们将在机器学习章节详细讨论这些模型。
Here machine learning comes in picture. Machine learning is basically divided into classification, regression, or clustering models and each model have some algorithms which is applied on the dataset to get the relevant information. These models are used in this phase. We will discuss these models in detail in the machine learning chapter.
Model Deployment
我们已经到达数据科学生命周期的最后阶段。经过详细的审查过程后,该模型终于可以按照所需的格式在所选渠道中部署。请注意,机器学习模型只有在生产中部署后才有用。一般来说,这些模型与产品和应用程序相关联并集成。
We have reached the final stage of the data science lifecycle. The model is finally ready to be deployed in the desired format and chosen channel after a detailed review process. Note that the machine learning model has no utility unless it is deployed in the production. Generally speaking, these models are associated and integrated with products and applications.
模型部署包含建立将模型部署到市场消费者或另一个系统所需的交付方法。机器学习模型也在设备上实施,并获得接受和吸引力。根据项目的复杂性,此阶段可能从 Tableau 仪表板的基本模型输出到拥有数百万用户的复杂云部署。
Model Deployment contains the establishment of a delivery method necessary to deploy the model to market consumers or to another system. Machine learning models are also being implemented on devices and gaining acceptance and appeal. Depending on the complexity of the project, this stage might range from a basic model output on a Tableau Dashboard to a complicated cloud-based deployment with millions of users.
Who are all involved in Data Science lifecycle?
数据正在从个人层面到组织层面,在大量的服务器和数据仓库中生成、收集和存储。但是您将如何访问这个庞大的数据存储库?这就是数据科学家介入的地方,因为他们专门从非结构化文本和统计数据中提取见解和模式。
Data is being generated, collected, and stored on voluminous servers and data warehouses from the individual level to the organisational level. But how will you access this massive data repository? This is where the data scientist comes in, since he or she is a specialist in extracting insights and patterns from unstructured text and statistics.
下文,我们将介绍参加数据科学生命周期的许多数据科学团队工作简介。
Below, we present the many job profiles of the data science team participating in the data science lifecycle.
S.No |
Job Profile & Role |
1 |
*Business Analyst*Understanding business requirements and find the right target customers. |
2 |
*Data Analyst*Format and clean the raw data, interpret and visualise them to perform the analysis and provide the technical summary of the same |
3 |
*Data Scientists*Improve quality of machine learning models. |
4 |
*Data Engineer*They are in charge of gathering data from social networks, websites, blogs, and other internal and external web sources ready for further analysis. |
5 |
*Data Architect*Connect, centralise, protect, and keep up with the organization’s data sources. |
6 |
*Machine Learning Engineer*Design and implement machine learning-related algorithms and applications. |
Data Science - Prerequisites
你需要具备多种技术和非技术技能才能成为一名成功的数据科学家。具备某些技能对于成为一名知识渊博的数据科学家至关重要,而另一些技能只是为了让数据科学家的事情变得更容易。不同的工作角色决定了你必须具备的特定技能熟练程度。
You need to have several technical and non-technical skills to become a successful Data Scientist. Some of the skills are essential to have to become a well-versed data scientist while some for just for making thing things easier for a data scientist. Different job roles determine the level of skill-specific proficiency you need to possess.
以下列出了一些成为数据科学家所需具备的技能。
Given below are some skills you will require to become a data scientist.
Technical Skills
Python
数据科学家大量使用 Python,因为它是最流行的编程语言之一,易于学习,并拥有可用于数据操作和数据分析的大型库。因为它是一种灵活的语言,所以它可以在数据科学的所有阶段中使用,例如数据挖掘或运行应用程序。Python 拥有一个庞大的开源库,其中包含强大的数据科学库,如 Numpy、Pandas、Matplotlib、PyTorch、Keras、Scikit Learn、Seaborn 等。这些库有助于完成不同的数据科学任务,例如读取大型数据集,绘制和可视化数据和相关性,训练和拟合机器学习模型以适应你的数据,评估模型的性能等。
Data Scientists use Python a lot because it is one of the most popular programming languages, easy to learn and has extensive libraries that can be used for data manipulation and data analysis. Since it is a flexible language, it can be used in all stages of Data Science, such as data mining or running applications. Python has a huge open-source library with powerful Data Science libraries like Numpy, Pandas, Matplotlib, PyTorch, Keras, Scikit Learn, Seaborn, etc. These libraries help with different Data Science tasks, such as reading large datasets, plotting and visualizing data and correlations, training and fitting machine learning models to your data, evaluating the performance of the model, etc.
SQL
SQL 是在开始数据科学之前需要的另一个基本条件。与其他编程语言相比,SQL 相对简单,但要成为一名数据科学家是必需的。此编程语言用于管理和查询关系数据库存储的数据。我们可以使用 SQL 检索、插入、更新和删除数据。要从数据中提取见解,能够创建复杂的 SQL 查询(包括连接、分组、具有等)至关重要。连接方法使你能够同时查询多个表格。SQL 还可以执行分析操作和转换数据库结构。
SQL is an additional essential prerequisite before getting started with Data Science. SQL is relatively simple compared to other programming languages, but is required to become a Data Scientist. This programming language is used to manage and query relational database-stored data. We can retrieve, insert, update, and remove data with SQL. To extract insights from data, it is crucial to be able to create complicated SQL queries that include joins, group by, having, etc. The join method enables you to query many tables simultaneously. SQL also enables the execution of analytical operations and the transformation of database structures.
R
R 是一种高级语言,用于制作复杂的统计模型。R 还允许你使用阵列、矩阵和向量。R 以其图形库而闻名,使用户能够绘制精美的图表并使图表易于理解。
R is an advanced language that is used to make complex models of statistics. R also lets you work with arrays, matrices, and vectors. R is well-known for its graphical libraries, which let users draw beautiful graphs and make them easy to understand.
借助 R Shiny,程序员可以使用 R 制作 Web 应用程序,用于将可视化元素嵌入到网页中,并为用户提供大量与其交互的方式。此外,数据提取是数据科学的一个关键部分。R 允许你将 R 代码连接到数据库管理系统。
With R Shiny, programmers can make web applications using R, which is used to embed visualizations in web pages and gives users a lot of ways to interact with them. Also, data extraction is a key part of the science of data. R lets you connect your R code to database management systems.
R 还为你提供了更高级数据分析的多种选择,例如构建预测模型、机器学习算法等。R 还有许多用于处理图像的软件包。
R also gives you a number of options for more advanced data analysis, such as building prediction models, machine learning algorithms, etc. R also has a number of packages for processing images.
Statistics
在数据科学中,高度依赖统计才能存储和翻译数据模式用于预测的高级机器算法。数据科学家利用统计执行数据收集、评估、分析和从数据中推论结论,以及使用相关的量化数学模型和变量。数据科学家担任程序员、研究员和商务主管等职位,所有这些学科都具有统计基础。统计在数据科学中的重要性与编程语言相当。
In data science, advanced machine learning algorithms that stores and translate data patterns for prediction rely heavily on statistics. Data scientists utilize statistics to collect, assess, analyze, and derive conclusions from data, as well as to apply relevant quantitative mathematical models and variables. Data scientists work as programmers, researchers, and executives in business, among other roles, all of these disciplines have a statistical foundation. The importance of statistics in data science is comparable to that of programming languages.
Hadoop
数据科学家在海量数据上执行操作,但有时系统的内存无法处理这些海量数据。那么如何在如此海量的数据上执行数据处理?这里 Hadoop 就发挥了作用。它可用于快速分割数据并将其传输至多个服务器以进行数据处理和其他操作(如筛选)。尽管 Hadoop 基于分布式计算概念,但许多公司要求数据科学家基本了解分布式系统原则(如 Pig、Hive、MapReduce 等)。许多公司已经开始使用 Hadoop 即服务(HaaS),这是云中 Hadoop 的另一个名称,这样数据科学家就不需要了解 Hadoop 的内部工作原理。
Data scientists perform operations on enormous amount of data but sometimes the memory of the system is not able to carry out processing on these huge amount of data. So how data processing will be performed on such huge amount of data? Here Hadoop comes in the picture. It is used to rapidly divide and transfer data to numerous servers for data processing and other actions such as filtering. While Hadoop is based on the concept of Distributed Computing, several firms require that Data Scientists have a fundamental understanding of Distributed System principles such as Pig, Hive, MapReduce, etc. Several firms have begun to use Hadoop-as-a-Service (HaaS), another name for Hadoop in the cloud, so that Data Scientists do not need to understand Hadoop’s inner workings.
Spark
Spark 是一个用于大数据计算的框架,它在数据科学领域中越来越流行。Hadoop 从磁盘读取数据并写入数据,而 Spark 计算结果在系统内存中,使得它与 Hadoop 相比更容易且更快。Apache Spark 的功能是加快复杂算法的速度,其专门用于数据科学。如果数据集很大,它会分布式处理数据,这会节省大量时间。使用 Apache Spark 的主要原因在于其速度和为运行数据科学任务和流程提供的平台。Spark 可以在一台计算机或多个计算机集群上运行,使得使用 Spark 非常方便。
Spark is a framework for big data computation like Hadoop and has gained some popularity in Data Science world. Hadoop reads data from the disk and writes data to the disk while on the other hand Spark Calculates the computation results in the system memory, making it comparatively easy and faster than Hadoop. The function of Apache Spark is to facilitate the speed of the complex algorithms and it is specially designed for the data science. If the dataset is huge then it distributes data processing which saves a lot of time. The main reason of using apache spark is because of its speed and the platform it provides to run data science tasks and processes. It is possible to run Spark on a single machine or a cluster of machines which makes it convenient to work with.
Machine Learning
机器学习是数据科学的关键组成部分。机器学习算法是分析海量数据的有效方式。它可以帮助自动化各种相关数据科学操作。但是,对机器学习原理的深入了解并非在行业内开始职业生涯的必需条件。大多数数据科学家缺乏机器学习技能。只有极少数数据科学家对推荐引擎、对抗性学习、强化学习、自然语言处理、异常值检测、时序分析、计算机视觉、生存分析等高级主题拥有广泛的知识和专门知识。因此,这些能力将帮助你在数据科学职业中脱颖而出。
Machine Learning is crucial component of Data Science. Machine Learning algorithms are an effective method for analysing massive volumes of data. It may assist in automating a variety of Data Science-related operations. Nevertheless, an in-depth understanding of Machine Learning principles is not required to begin a career in this industry. The majority of Data Scientists lack skills in Machine Learning. Just a tiny fraction of Data Scientists has extensive knowledge and expertise in advanced topics such as Recommendation Engines, Adversarial Learning, Reinforcement Learning, Natural Language Processing, Outlier Detection, Time Series Analysis, Computer Vision, Survival Analysis, etc. These competencies will consequently help you stand out in a Data Science profession.
Non-Technical Skills
Understanding of Business Domain
数据科学家对特定业务领域或涉猎领域的了解越深入,就越容易对该特定领域的数据进行分析。
More understanding one has for a particular business area or domain, easier it will be for a data scientist to do the analysis on the data from that particular domain.
Understanding of Data
数据科学涉及所有数据,因此了解数据非常重要,例如什么是数据、如何存储数据、表、行和列的知识。
Data Science is all about data so it is very important to have an understanding of data that what is data, how data is stored, knowledge of tables, rows and columns.
Critical and Logical Thinking
批判性思维是在理解和明确了解思想如何匹配过程中明确、合乎逻辑地思考的能力。在数据科学中,您需要具备批判性思维,以便获得有用的见解并改善业务运营。批判性思维可能是数据科学中最重要的技能之一。它使他们能够更深入地挖掘信息并找出最重要的事情。
Critical thinking is the ability to think clearly and logically while figuring out and understanding how ideas fit together. In data science, you need to be able to think critically to get useful insights and improve business operations. Critical thinking is probably one of the most important skills in data science. It makes it easier for them to dig deeper into information and find the most important things.
Product Understanding
设计模型并非数据科学家的全部工作。数据科学家必须提出可用于提高产品质量的见解。通过系统方法,如果专业人士了解整个产品,他们可以快速加速。他们可以帮助模型启动(引导)并改善特性工程。此技能还可以帮助他们通过揭示以前可能没有想到过的有关产品的想法和见解来改善他们的讲故事能力。
Designing models isn’t the entire job of a data scientist. Data scientists have to come up with insights that can be used to improve the quality of products. With a systematic approach, professionals can accelerate quickly if they understand the whole product. They can help models get started (bootstrap) and improve feature engineering. This skill also helps them improve their storytelling by revealing thoughts and insights about products that they may not have thought of before.
Adaptability
在现代人才获取流程中,数据科学家最抢手的软技能之一是适应能力。由于新技术正在更快地被制造和使用,因此专业人士必须快速学会如何使用它们。作为一名数据科学家,您必须跟上不断变化的业务趋势并能够适应。
One of the most sought-after soft skills for data scientists in the modern talent acquisition process is the ability to adapt. Because new technologies are being made and used more quickly, professionals have to quickly learn how to use them. As a data scientist, you have to keep up with changing business trends and be able to adapt.
Data Science - Applications
数据科学涉及不同的学科,如数学和统计建模、从其来源提取数据和应用数据可视化技术。它还涉及处理大数据技术以收集结构化和非结构化数据。下面,我们将看到一些数据科学的应用——
Data Science involves different disciplines like mathematical and statistical modelling, extracting data from its source and applying data visualization techniques. It also involves handling big data technologies to gather both structured and unstructured data. Below, we will see some applications of data science −
Gaming Industry
通过建立社交媒体影响力,体育组织应对许多问题。游戏公司 Zynga 推出了社交媒体游戏,例如 Zynga Poker、Farmville、Chess with Friends、Speed Guess Something 和 Words with Friends。这产生了大量的用户连接和海量数据。
By establishing a presence on social media, sports organizations deal with a number of issues. Zynga, a gaming corporation, has produced social media games like Zynga Poker, Farmville, Chess with Friends, Speed Guess Something, and Words with Friends. This has generated many user connections and large data volumes.
这就是游戏行业中数据科学的必要性所在,以便使用从所有社交网络中获取的玩家数据。数据分析为玩家提供了一种迷人、创新的娱乐方式,让他们始终领先于竞争对手!数据科学最有趣的应用之一是在游戏制作的功能和程序中。
Here comes the necessity for data science within the game business in order to use the data acquired from players across all social networks. Data analysis provides a captivating, innovative diversion for players to keep ahead of the competition! One of the most interesting applications of data science is inside the features and procedures of game creation.
Health Care
数据科学在医疗保健领域发挥着重要作用。数据科学家的责任是将所有数据科学方法集成到医疗保健软件中。数据科学家帮助从数据中收集有用的见解,以便创建预测模型。数据科学家在医疗保健领域的总体职责如下——
Data Science plays an important role in the field of healthcare. A Data Scientist’s responsibility is to integrate all Data Science methodologies into healthcare software. The Data Scientist helps in collecting useful insights from the data in order to create prediction models. The overall responsibilities of a Data Scientist in the field of healthcare are as follows −
-
Collecting information from patients
-
Analyzing hospitals' requirements
-
Organizing and classifying the data for usage
-
Implementing Data Analytics with diverse methods
-
Using algorithms to extract insights from data.
-
Developing predictive models with the development staff.
以下是数据科学的一些应用:
Given below are some of the applications of data science −
Medical Image Analysis
数据科学通过对扫描图像执行图像分析,帮助确定人体的异常,从而帮助医生制定适当的治疗计划。这些图片检查包括 X 射线、超声波、MRI(磁共振成像)、CT 扫描等。医生可以通过研究这些测试照片获得重要信息,从而为患者提供更好的护理。
Data Science helps to determine the abnormalities in a human body by performing image analysis on scanned images, hence assisting physicians in developing an appropriate treatment plan. These picture examinations include X-ray, sonography, MRI (Magnetic Resonance Imaging), and CT scan, among others. Doctors are able to give patients with better care by gaining vital information from the study of these test photos.
Predictive Analysis
使用数据科学开发的预测分析模型可以预测患者的病情。此外,它还有助于制定患者适当治疗的策略。预测分析是数据科学中一个非常重要的工具,在医疗保健业务中发挥着重要作用。
The condition of a patient is predicted by the predictive analytics model developed using Data Science. In addition, it facilitates the development of strategies for the patient’s suitable treatment. Predictive analytics is a highly important tool of data science that plays a significant part in the healthcare business.
Image Recognition
图像识别是一种图像处理技术,可以识别图像中的所有内容,包括人物、图案、徽标、物品、位置、颜色和形式。
Image recognition is a technique of image processing that identifies everything in an image, including individuals, patterns, logos, items, locations, colors, and forms.
数据科学技术已经开始识别人的面部,并将其与数据库中的所有图像进行匹配。此外,带有摄像头的手机正在生成无限数量的数字图像和视频。大量数字数据正被企业用于为客户提供更优质、更便捷的服务。通常,人工智能的面部识别系统分析所有面部特征,并将其与数据库进行比较以查找匹配项。
Data Science techniques have begun to recognize the human face and match it with all the images in their database. In addition, mobile phones with cameras are generating infinite number of digital images and videos. This vast amount of digital data is being utilized by businesses to provide customers with superior and more convenient services. Generally, the facial recognition system of AI analyses all facial characteristics and compares them to its database to find a match.
例如,iPhone 中面容锁功能中的面部检测。
For example, Facial detection in Face lock feature in iPhone.
Recommendation systems
随着在线购物的日益普及,电子商务平台能够捕捉到用户的购物偏好以及市场上各种产品的表现。这导致创建推荐系统,该系统创建预测购物者需求的模型,并展示购物者最有可能购买的产品。诸如亚马逊和 Netflix 等公司使用推荐系统,以便帮助其用户找到他们正在寻找的正确电影或产品。
As online shopping becomes more prevalent, the e-commerce platforms are able to capture users shopping preferences as well as the performance of various products in the market. This leads to creation of recommendation systems, which create models predicting the shoppers needs and show the products the shopper is most likely to buy. Companies like Amazon and Netflix use recommendation system so that they can help their user to find the correct movie or product they are looking for.
Airline Routing Planning
数据科学在航空业中呈现出众多机会。高空飞行飞机提供了大量有关发动机系统、燃油效率、天气、乘客信息等方面的数据。当该行业使用更多配备了传感器和其他数据收集技术的现代化飞机时,将创建更多数据。如果使用得当,这些数据可能会为该行业提供新的可能性。
Data Science in the Airline Industry presents numerous opportunities. High-flying aircraft provide an enormous amount of data about engine systems, fuel efficiency, weather, passenger information, etc. More data will be created when more modern aircraft equipped with sensors and other data collection technologies are used by the industry. If appropriately used, this data may provide new possibilities for the sector.
它还有助于决定是直接降落在目的地还是在中途停靠,例如航班可以有直达航线。
It also helps to decide whether to directly land at the destination or take a halt in between like a flight can have a direct route.
Finance
数据科学在银行业的重要性与相关性与数据科学在企业决策的其他领域中的重要性相关。金融业的数据科学专业人士通过帮助他们开发工具和仪表盘来增强投资流程,为公司内的相关团队,特别是投资和财务团队提供支持和帮助。
The importance and relevance of data science in the banking sector is comparable to that of data science in other areas of corporate decision-making. Professionals in data science for finance give support and assistance to relevant teams within the company, particularly the investment and financial team, by assisting them in the development of tools and dashboards to enhance the investment process.
Improvement in Health Care services
医疗保健行业处理各种数据,这些数据可分为技术数据、财务数据、患者信息、药物信息和法律法规。所有这些数据都需要以协调的方式进行分析,以产生见解,从而为医疗保健提供者和护理接受者节省成本,同时保持法律合规性。
The health care industry deals with a variety of data which can be classified into technical data, financial data, patient information, drug information and legal rules. All this data need to be analyzed in a coordinated manner to produce insights that will save cost, both for the health care provider and care receiver, while remaining legally compliant.
Computer Vision
计算机识别图像的进步涉及处理来自同一类别多个对象的成组图像数据。例如,面部识别。对这些数据集进行建模,并创建算法将模型应用于更新的图像(测试数据集)以获得满意的结果。处理这些海量数据集和创建模型需要数据科学中使用的各种工具。
The advancement in recognizing an image by a computer involves processing large sets of image data from multiple objects of same category. For example, Face recognition. These data sets are modelled, and algorithms are created to apply the model to newer images (testing dataset) to get a satisfactory result. Processing of these huge data sets and creation of models need various tools used in Data Science.
Efficient Management of Energy
随着能源消耗需求的增加,能源生产公司需要更有效地管理能源生产和分配的各个阶段。这包括优化生产方法、存储和分配机制,以及研究客户的消费模式。链接来自所有这些来源的数据并得出见解似乎是一项艰巨的任务。通过使用数据科学工具可以更轻松地实现这一点。
As the demand for energy consumption rises, the energy producing companies need to manage the various phases of the energy production and distribution more efficiently. This involves optimizing the production methods, the storage and distribution mechanisms as well as studying the customers’ consumption patterns. Linking the data from all these sources and deriving insight seems a daunting task. This is made easier by using the tools of data science.
Internet Search
多个搜索引擎使用数据科学来了解用户行为和搜索模式。这些搜索引擎使用多种数据科学方法为每个用户提供最相关的搜索结果。随着时间的推移,Google、Yahoo、Bing 等搜索引擎在几秒钟内回复搜索的能力越来越强。
Several search engines use data science to understand user behaviour and search patterns. These search engines use diverse data science approaches to give each user with the most relevant search results. Search engines such as Google, Yahoo, Bing, etc. are becoming increasingly competent at replying to searches in seconds as time passes.
Speech Recognition
Google 的语音助手、Apple 的 Siri 和 Microsoft 的 Cortana 都使用大型数据集,并由数据科学和自然语言处理 (NLP) 算法提供支持。随着更多数据的分析,语音识别软件得到改进,对人类本性的理解也得到了加深,这得益于数据科学的应用。
Google’s Voice Assistant, Apple’s Siri, and Microsoft’s Cortana all utilise large datasets and are powered by data science and natural language processing (NLP) algorithms. Speech recognition software improves and gains a deeper understanding of human nature due to the application of data science as more data is analysed.
Education
当世界经历 COVID-19 流行病时,大多数学生总是随身携带电脑。印度教育体系一直使用在线课程、作业和考试的电子提交等。对我们大多数人来说,做任何事情“在线”仍然具有挑战性。技术和当代已经发生了变革。因此,随着数据科学进入我们的教育系统,它成为教育中比以往任何时候都至关重要。
While the world experienced the COVID-19 epidemic, the majority of students were always carrying their computers. Online Courses, E-Submissions of assignments and examinations, etc., have been used by the Indian education system. For the majority of us, doing everything "online" remains challenging. Technology and contemporary times have undergone a metamorphosis. As a result, Data Science in education is more crucial than ever as it enters our educational system.
现在,讲师和学生在日常互动中的表现通过各种平台进行记录,课堂参与度和其他因素正在接受评估。因此,在线课程数量的增加提升了教育数据深度的价值。
Now, instructors’ and students' everyday interactions are being recorded through a variety of platforms, and class participation and other factors are being evaluated. As a result, the rising quantity of online courses has increased the value of Educational data’s depth.
Data Science - Machine Learning
机器学习使机器能够从数据中自动学习、从经验中提高性能并预测事物,而无需明确编程。机器学习主要涉及开发算法,让计算机能够自行从数据和过去的经验中学习。机器学习一词最早由阿瑟·塞缪尔在 1959 年提出。
Machine learning enables a machine to automatically learn from data, improve performance from experiences, and predict things without being explicitly programmed. Machine Learning is mainly concerned with the development of algorithms which allow a computer to learn from the data and past experiences on their own. The term machine learning was first introduced by Arthur Samuel in 1959.
数据科学是一门从数据中获取有用见解的科学,以便获取最关键和最相关的的信息来源。并在给定可靠数据流的情况下,使用机器学习生成预测。
Data Science is the science of gaining useful insights from data in order to get the most crucial and relevant information source. And given a dependable stream of data, generating predictions using machine learning.
数据科学和机器学习是计算机科学的子领域,重点在于分析和利用大量数据,以改进产品、服务、基础设施系统等的开发和向市场推出这些产品的流程。
Data Science and machine learning are subfields of computer science that focus on analyzing and making use of large amounts of data to improve the processes by which products, services, infrastructural systems, and more are developed and introduced to the market.
两者之间的关系类似于正方形是矩形,但矩形不是正方形。数据科学是包罗万象的矩形,而机器学习则是正方形,是它自己的实体。它们都是数据科学家在其工作中常用的,并且越来越受到几乎所有企业的接受。
The two relate to each other in a similar manner that squares are rectangles, but rectangles are not squares. Data Science is the all-encompassing rectangle, while machine learning is a square that is its own entity. They are both commonly employed by data scientists in their job and are increasingly being accepted by practically every business.
What is Machine Learning?
机器学习 (ML) 是一种算法,它让软件能够更准确地预测未来会发生什么,而无需专门编程来执行此操作。机器学习的基本思想是制定算法,让其可以将数据作为输入,并使用统计分析来预测输出,并且随着新数据的出现,还会更新输出。
Machine learning (ML) is a type of algorithm that lets software get more accurate at predicting what will happen in future without being specifically programmed to do so. The basic idea behind machine learning is to make algorithms that can take data as input and use statistical analysis to predict an output while also updating outputs as new data becomes available.
机器学习是使用算法在数据中查找模式,然后预测这些模式在未来如何变化的人工智能的一部分。这使工程师能够使用统计分析来查找数据中的模式。
Machine learning is a part of artificial intelligence that uses algorithms to find patterns in data and then predict how those patterns will change in the future. This lets engineers use statistical analysis to look for patterns in the data.
Facebook、Twitter、Instagram、YouTube 和 TikTok 基于你过去的行为收集有关其用户的信息,它可以猜测你的兴趣和要求,并推荐适合你需要的产品、服务或文章。
Facebook, Twitter, Instagram, YouTube, and TikTok collect information about their users, based on what you’ve done in the past, it can guess your interests and requirements and suggest products, services, or articles that fit your needs.
机器学习是一组工具和概念,用于数据科学,但它们也出现在其他领域。数据科学家通常在他们的工作中使用机器学习,以帮助他们更快地获取更多信息或找出趋势。
Machine learning is a set of tools and concepts that are used in data science, but they also show up in other fields. Data scientists often use machine learning in their work to help them get more information faster or figure out trends.
Types of Machine Learning
机器学习可以分为三种类型的算法——
Machine learning can be classified into three types of algorithms −
-
Supervised learning
-
Unsupervised learning
-
Reinforcement learning
Supervised Learning
监督式学习是一种机器学习和人工智能。它也被称为“监督式机器学习”。它的定义是它使用标记数据集来训练算法如何正确分类数据或预测结果。当数据被放入模型时,其权重会发生变化,直到模型正确合适。这是交叉验证过程的一部分。监督式学习帮助组织为广泛的现实世界问题找到大规模解决方案,例如像 Gmail 中将垃圾邮件分类到与收件箱分开的文件夹一样,我们有一个垃圾邮件文件夹。
Supervised learning is a type of machine learning and artificial intelligence. It is also called "supervised machine learning." It is defined by the fact that it uses labelled datasets to train algorithms how to correctly classify data or predict outcomes. As data is put into the model, its weights are changed until the model fits correctly. This is part of the cross validation process. Supervised learning helps organisations find large-scale solutions to a wide range of real-world problems, like classifying spam in a separate folder from your inbox like in Gmail we have a spam folder.
Supervised Learning Algorithms
一些监督式学习算法有——
Some supervised learning algorithms are −
-
Naive Bayes − Naive Bayes is a classification algoritm that is based on the Bayes Theorem’s principle of class conditional independence. This means that the presence of one feature doesn’t change the likelihood of another feature, and that each predictor has the same effect on the result/outcome.
-
Linear Regression − Linear regression is used to find how a dependent variable is related to one or more independent variables and to make predictions about what will happen in the future. Simple linear regression is when there is only one independent variable and one dependent variable.
-
Logistic Regression − When the dependent variables are continuous, linear regression is used. When the dependent variables are categorical, like "true" or "false" or "yes" or "no," logistic regression is used. Both linear and logistic regression seek to figure out the relationships between the data inputs. However, logistic regression is mostly used to solve binary classification problems, like figuring out if a particular mail is a spam or not.
-
Support Vector Machines(SVM) − A support vector machine is a popular model for supervised learning developed by Vladimir Vapnik. It can be used to both classify and predict data. So, it is usually used to solve classification problems by making a hyperplane where the distance between two groups of data points is the greatest. This line is called the "decision boundary" because it divides the groups of data points (for example, oranges and apples) on either side of the plane.
-
K-nearest Neighbour − The KNN algorithm, which is also called the "k-nearest neighbour" algorithm, groups data points based on how close they are to and related to other data points. This algorithm works on the idea that data points that are similar can be found close to each other. So, it tries to figure out how far apart the data points are, using Euclidean distance and then assigns a category based on the most common or average category. However, as the size of the test dataset grows, the processing time increases, making it less useful for classification tasks.
-
Random Forest − Random forest is another supervised machine learning algorithm that is flexible and can be used for both classification and regression. The "forest" is a group of decision trees that are not correlated to each other. These trees are then combined to reduce variation and make more accurate data predictions.
Unsupervised Learning
无监督学习(也称为无监督机器学习)使用机器学习算法查看未标记数据集并将其分组在一起。这些程序可以找到隐藏的模式或数据组。它查找信息中相似性和差异性的能力使其非常适合探索性数据分析、交叉销售策略、客户细分和图像识别。
Unsupervised learning, also called unsupervised machine learning, uses machine learning algorithms to look at unlabelled datasets and group them together. These programmes find hidden patterns or groups of data. Its ability to find similarities and differences in information makes it perfect for exploratory data analysis, cross-selling strategies, customer segmentation, and image recognition.
Common Unsupervised Learning Approaches
无监督学习模型用于以下三个主要任务:聚类、建立连接和降低维度。下面,我们将介绍学习方法和常用算法 -
Unsupervised learning models are used for three main tasks: clustering, making connections, and reducing the number of dimensions. Below, we’ll describe learning methods and common algorithms used −
Clustering - 聚类是一种数据挖掘方法,可根据相似性或差异性对未标记数据进行组织。聚类技术用于根据数据中的结构或模式将未分类、未经处理的数据项组织到组中。聚类算法有很多类型,包括排他、重叠、层次和概率。
Clustering − Clustering is a method for data mining that organises unlabelled data based on their similarities or differences. Clustering techniques are used to organise unclassified, unprocessed data items into groups according to structures or patterns in the data. There are many types of clustering algorithms, including exclusive, overlapping, hierarchical, and probabilistic.
K-means Clustering 是聚类方法的一个流行示例,其中数据点根据到每个组的质心的距离分配到 K 组。最接近某个质心的数据点将被归入同一类别。较高的 K 值表示具有更多粒度的较小组,而较低的 K 值表示具有较少粒度的较大组。K 均值聚类的常见应用包括市场细分、文档聚类、图像分割和图像压缩。
K-means Clustering is a popular example of an clustering approach in which data points are allocated to K groups based on their distance from each group’s centroid. The data points closest to a certain centroid will be grouped into the same category. A higher K number indicates smaller groups with more granularity, while a lower K value indicates bigger groupings with less granularity. Common applications of K-means clustering include market segmentation, document clustering, picture segmentation, and image compression.
Dimensionality Reduction - 尽管更多的数据通常会产生更准确的发现,但它也可能影响机器学习算法的有效性(例如,过拟合)并使数据集难以可视化。降维是一种在数据集具有过多特征或维度时使用的策略。它将数据输入量减少到可管理的水平,同时尽可能保持数据集的完整性。降维通常应用于数据预处理阶段,有很多方法,其中之一就是 -
Dimensionality Reduction − Although more data typically produces more accurate findings, it may also affect the effectiveness of machine learning algorithms (e.g., overfitting) and make it difficult to visualize datasets. Dimensionality reduction is a strategy used when a dataset has an excessive number of characteristics or dimensions. It decreases the quantity of data inputs to a manageable level while retaining the integrity of the dataset to the greatest extent feasible. Dimensionality reduction is often employed in the data pre-processing phase, and there are a number of approaches, one of them is −
Principal Component Analysis (PCA) - 这是通过特征提取消除冗余和压缩数据集的降维方法。此方法采用线性变换来生成新的数据表示,从而产生一组“主成分”。第一个主成分是使方差最大化的数据集方向。尽管第二个主成分同样在数据中找到了最大的方差,但它与第一个完全不相关,从而产生了与第一个正交的方向。此过程根据维度的数量重复,下一个主分量是与最可变前一个分量正交的方向。
Principal Component Analysis (PCA) − It is a dimensionality reduction approach used to remove redundancy and compress datasets through feature extraction. This approach employs a linear transformation to generate a new data representation, resulting in a collection of "principal components." The first principal component is the dataset direction that maximises variance. Although the second principal component similarly finds the largest variance in the data, it is fully uncorrelated with the first, resulting in a direction that is orthogonal to the first. This procedure is repeated dependent on the number of dimensions, with the next main component being the direction orthogonal to the most variable preceding components.
Reinforcement Learning
强化学习 (RL) 是一种机器学习,它允许代理通过反复试验和利用其自身行为和经验的反馈在交互式环境中学习。
Reinforcement Learning (RL) is a type of machine learning that allows an agent to learn in an interactive setting via trial and error utilising feedback from its own actions and experiences.
Key terms in reinforcement learning
一些描述 RL 问题基本组件的重要概念有 -
Some significant concepts describing the fundamental components of an RL issue are −
-
Environment − The physical surroundings in which an agent functions
-
Condition − The current standing of the agent
-
Reward − Environment-based feed-back
-
Policy − Mapping between agent state and actions
-
Value − The future compensation an agent would obtain for doing an action in a given condition.
Data Science Vs Machine Learning
数据科学是对数据的研究以及如何从中得出有意义的见解,而机器学习是对使用数据来提高性能或为预测提供信息的模型的研究和开发。机器学习是人工智能的一个子领域。
Data Science is the study of data and how to derive meaningful insights from it, while machine learning is the study and development of models that use data to enhance performance or inform predictions. Machine learning is a subfield of artificial intelligence.
近年来,机器学习和人工智能 (AI) 已开始主导数据科学的部分领域,在数据分析和商业智能中发挥着至关重要的作用。机器学习通过使用模型和算法收集和分析有关特定人群的巨量数据,自动执行数据分析并根据这些数据进行预测。数据科学和机器学习是相关的,但并不相同。
In recent years, machine learning and artificial intelligence (AI) have come to dominate portions of data science, playing a crucial role in data analytics and business intelligence. Machine learning automates data analysis and makes predictions based on the collection and analysis of massive volumes of data about certain populations using models and algorithms. Data Science and machine learning are related to each other, but not identical.
数据科学是一个广阔的领域,涵盖从数据中获取见解和信息的所有方面。它涉及收集、清理、分析和解释大量数据,以发现可能指导业务决策的模式、趋势和见解。
Data Science is a vast field that incorporates all aspects of deriving insights and information from data. It involves gathering, cleaning, analysing, and interpreting vast amount of data to discover patterns, trends, and insights that may guide business choices.
机器学习是数据科学的一个子领域,它专注于开发可以从数据中学习并根据其获取的知识进行预测或判断的算法。机器学习算法旨在通过获取新知识自动随着时间的推移提高其性能。
Machine learning is a subfield of data science that focuses on the development of algorithms that can learn from data and make predictions or judgements based on their acquired knowledge. Machine learning algorithms are meant to enhance their performance automatically over time by acquiring new knowledge.
换句话说,数据科学包含机器学习作为其众多方法之一。机器学习是数据分析和预测的有力工具,但它只是整个数据科学的一个子领域。
In other words, data science encompasses machine learning as one of its numerous methodologies. Machine learning is a strong tool for data analysis and prediction, but it is just a subfield of data science as a whole.
下面是对比表,以清晰理解。
Given below is the table of comparison for a clear understanding.
Data Science |
Machine Learning |
Data Science is a broad field that involves the extraction of insights and knowledge from large and complex datasets using various techniques, including statistical analysis, machine learning, and data visualization. |
Machine learning is a subset of data science that involves defining and developing algorithms and models that enable machines to learn from data and make predictions or decisions without being explicitly programmed. |
Data Science focuses on understanding the data, identifying patterns and trends, and extracting insights to support decision-making. |
Machine learning, on the other hand, focuses on building predictive models and making decisions based on the learned patterns. |
Data Science includes a wide range of techniques, such as data cleaning, data integration, data exploration, statistical analysis, data visualization, and machine learning. |
Machine learning, on the other hand, primarily focuses on building predictive models using algorithms such as regression, classification, and clustering. |
Data Science typically requires large and complex datasets that require significant processing and cleaning to derive insights. |
Machine learning, on the other hand, requires labelled data that can be used to train algorithms and models. |
Data Science requires skills in statistics, programming, and data visualization, as well as domain knowledge in the area being studied. |
Machine learning requires a strong understanding of algorithms, programming, and mathematics, as well as a knowledge of the specific application area. |
Data Science techniques can be used for a variety of purposes beyond prediction, such as clustering, anomaly detection, and data visualization |
Machine learning algorithms are primarily focused on making predictions or decisions based on data |
Data Science often relies on statistical methods to analyze data, |
Machine learning relies on algorithms to make predictions or decisions. |
Data Science - Data Analysis
What is Data Analysis in Data Science?
数据分析是数据科学的关键组成部分之一。数据分析被描述为一个清理、转换和建模数据的过程,以获得可操作的商业智能。它使用统计和计算方法来从大量数据中获取见解并提取信息。数据分析的目标是从数据中提取相关信息,并基于此知识做出决策。
Data analysis is one of the key component of data science. Data analysis is described as the process of cleaning, converting, and modelling data to obtain actionable business intelligence. It uses statistical and computational methods to gain insights and extract information form the large amount of data. The objective of data analysis is to extract relevant information from data and make decisions based on this knowledge.
尽管数据分析可能会纳入统计流程,但通常是一个持续、迭代的流程,其中持续收集数据,并同时进行分析。事实上,研究人员通常在整个数据收集过程中评估趋势方面的观察。特定的定性技术(实地调查、人种学内容分析、口述历史、传记、不受干扰的研究)和数据的本质决定分析的结构。
Although data analysis might incorporate statistical processes, it is often an ongoing, iterative process in which data are continually gathered and analyzed concurrently. In fact, researchers often assess observations for trends during the whole data gathering procedure. The particular qualitative technique (field study, ethnographic content analysis, oral history, biography, unobtrusive research) and the nature of the data decide the structure of the analysis.
更确切地说,数据分析将原始数据转换成有意义的见解和有价值的信息,这有助于在医疗保健、教育、商业等各个领域做出明智的决策。
To be more precise, Data analysis converts raw data into meaningful insights and valuable information which helps in making informed decisions in various fields like healthcare, education, business, etc.
Why Data Analysis is important?
以下是数据分析为何在当今至关重要的原因列表 −
Below is the list of reasons why is data analysis crucial today −
-
Accurate Data − We need data analysis that helps businesses acquire relevant and accurate information that they can use to plan business strategies and make informed decisions related to future plans and realign the company’s vision and goal.
-
Better decision-making − Data analysis helps in making informed decisions by identifying patterns and trends in the data and providing valuable insights. This enables businesses and organizations to make data-driven decisions, which can lead to better outcomes and increased success.
-
Improved Efficiency − Analyzing data can help identify inefficiencies and areas for improvement in business operations, leading to better resource allocation and increased efficiency.
-
Competitive Advantage − By analyzing data, businesses can gain a competitive advantage by identifying new opportunities, developing new products or services, and improving customer satisfaction.
-
Risk Management − Analyzing data can help identify potential risks and threats to a business, enabling proactive measures to be taken to mitigate those risks.
-
Customer insights − Data analysis can provide valuable insights into customer behavior and preferences, enabling businesses to tailor their products and services to better meet customer needs.
Data Analysis Process
随着企业可访问数据复杂程度和数量的增长,对数据分析的需求也随之增加,用于清理数据并提取企业可用于做出明智决策的相关信息。
As the complexity and quantity of data accessible to business grows the complexity, so does the need for data analysis increases for cleaning the data and to extract relevant information that can be used by the businesses to make informed decisions.
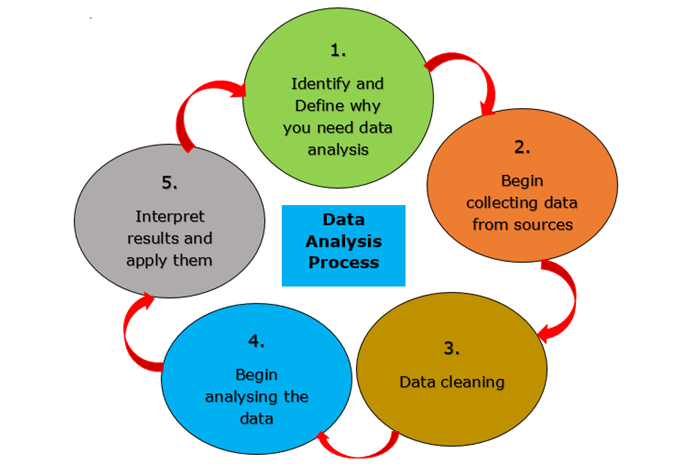
通常,数据分析过程涉及许多迭代。让我们更详细地检查每一个。
Typically, the data analysis process involves many iterative rounds. Let’s examine each in more detail.
-
Identify − Determine the business issue you want to address. What issue is the firm attempting to address? What must be measured, and how will it be measured?
-
Collect − Get the raw data sets necessary to solve the indicated query. Internal sources, such as client relationship management (CRM) software, or secondary sources, such as government records or social media application programming interfaces, may be used to gather data (APIs).
-
Clean − Prepare the data for analysis by cleansing it. This often entails removing duplicate and anomalous data, resolving inconsistencies, standardizing data structure and format, and addressing white spaces and other grammatical problems.
-
Analyze the Data − You may begin to identify patterns, correlations, outliers, and variations that tell a narrative by transforming the data using different data analysis methods and tools. At this phase, you may utilize data mining to identify trends within databases or data visualization tools to convert data into an easily digestible graphical format.
-
Interpret − Determine how effectively the findings of your analysis addressed your initial query by interpreting them. Based on the facts, what suggestions are possible? What constraints do your conclusions have?
Types of Data Analysis
数据可以通过多种方式用于回答问题并协助决策制定。要选择最佳数据分析方法,您必须了解该领域广泛使用的四种数据分析类型,这可能有帮助。
Data may be utilized to answer questions and assist decision making in several ways. To choose the optimal method for analyzing your data, you must have knowledge about the four types of data analysis widely used in the area might be helpful.
我们将在下面的章节中详细讨论每一部分−
We will discuss each one in detail in the below sections −
Descriptive Analysis
描述性分析是对当前和过去数据进行检查以查找模式和趋势的过程。它有时被称为观察数据的最简单方法,因为它显示了趋势和关系,而不深入详情。
Descriptive analytics is the process of looking at both current and past data to find patterns and trends. It’s sometimes called the simplest way to look at data because it shows about trends and relationships without going into more detail.
描述性分析简单易用,而且可能是几乎每家公司每天都在做的事情。Microsoft Excel 等简单的统计软件或 Google Charts 和 Tableau 等数据可视化工具可以帮助分离数据、查找变量之间的趋势和关系,以及以可视化的方式显示信息。
Descriptive analytics is easy to use and is probably something almost every company does every day. Simple statistical software like Microsoft Excel or data visualisation tools like Google Charts and Tableau can help separate data, find trends and relationships between variables, and show information visually.
描述性分析是一种展示事物随着时间推移如何变化的好方法。它还使用趋势作为更多分析的起点以帮助做出决策。
Descriptive analytics is a good way to show how things have changed over time. It also uses trends as a starting point for more analysis to help make decisions.
这种类型的分析回答了“发生了什么?”的问题。
This type of analysis answers the question, “What happened?”.
描述性分析的一些示例包括财务报表分析、调查报告。
Some examples of descriptive analysis are financial statement analysis, survey reports.
Diagnostic Analysis
诊断分析是使用数据找出趋势和变量之间的相关发生的缘故的过程。这是在使用描述性分析识别趋势之后的下一步。您可以使用算法或统计软件(例如 Microsoft Excel)手动进行诊断分析。
Diagnostic analytics is the process of using data to figure out why trends and correlation between variables happen. It is the next step following identifying trends using descriptive analytics. You can do diagnostic analysis manually, with an algorithm, or with statistical software (such as Microsoft Excel).
在进行诊断分析之前,你必须了解如何进行假设检验,相关性和因果关系的区别,以及诊断回归分析是什么。
Before getting into diagnostic analytics, you should know how to test a hypothesis, what the difference is between correlation and causation, and what diagnostic regression analysis is.
此类型的分析回答以下问题:“为什么会发生这种情况”?
This type of analysis answers the question, “Why did this happened?”.
一些诊断分析的示例是考察市场需求、解释客户行为。
Some examples of diagnostic analysis are examining market demand, explaining customer behavior.
Predictive Analysis
预测分析是使用数据来尝试找出未来会发生什么事的过程。它使用过去的数据对可能发生的未来情况进行预测,这有助于制定战略决策。
Predictive analytics is the process of using data to try to figure out what will happen in the future. It uses data from the past to make predictions about possible future situations that can help make strategic decisions.
预测可能是针对近期或未来,例如预测当天晚些时候设备会发生故障,或预测公司明年的现金流等远期预测。
The forecasts might be for the near term or future, such as anticipating the failure of a piece of equipment later that day, or for the far future, such as projecting your company’s cash flows for the next year.
预测分析可以手动完成,也可以借助机器学习算法来完成。在这两种情况下,都使用过去的数据对未来将发生的事情进行猜测或预测。
Predictive analysis can be done manually or with the help of algorithms for machine learning. In either case, data from the past is used to make guesses or predictions about what will happen in the future.
回归分析是一种预测分析方法,它可以检测两个变量(线性回归)或三个或更多个变量(多元回归)之间的关联。变量之间的关联用一个数学等式表示,该等式可用于预测如果一个变量发生变化,结果会如何。
Regression analysis, which may detect the connection between two variables (linear regression) or three or more variables, is one predictive analytics method (multiple regression). The connections between variables are expressed in a mathematical equation that may be used to anticipate the result if one variable changes.
回归分析使我们能够深入了解该关联的结构,并提供有关数据与该关联的匹配程度的度量。此类见解对于评估过去模式和制定预测非常有用。预测有助于我们制定数据驱动的计划并做出更明智的决策。
Regression allows us to gain insights into the structure of that relationship and provides measures of how well the data fit that relationship. Such insights can be extremely useful for assessing past patterns and formulating predictions. Forecasting can help us to build data-driven plans and make more informed decisions.
此类型的分析回答以下问题:“未来可能发生什么事”?
This type of analysis answers the question, “What might happen in the future?”.
一些预测分析的示例是市场行为定位、医疗保健疾病或过敏反应的早期检测。
Some examples of predictive analysis are Marketing-behavioral targeting, Healthcare-early detection of a disease or an allergic reaction.
Prescriptive Analysis
规范分析是使用数据找出下一步最佳行动的过程。此类型的分析会研究所有重要因素,并提出接下来该做什么的建议。这使得规范分析成为一个基于数据进行决策的实用工具。
Prescriptive analytics is the process of using data to figure out the best thing to do next. This type of analysis looks at all the important factors and comes up with suggestions for what to do next. This makes prescriptive analytics a useful tool for making decisions based on data.
在规范分析中,机器学习算法经常用于比人更快、通常更高效地对大量数据进行分类。算法使用 “if” 和 “else” 语句对数据进行分类,并根据一定的要求提出建议。例如,如果一个数据集中的至少 50% 的客户表示他们对你的客服团队“非常不满意”,则该算法可能会建议你的团队需要更多培训。
In prescriptive analytics, machine-learning algorithms are often used to sort through large amounts of data faster and often more efficiently than a person can. Using "if" and "else" statements, algorithms sort through data and make suggestions based on a certain set of requirements. For example, if at least 50% of customers in a dataset said they were "very unsatisfied" with your customer service team, the algorithm might suggest that your team needs more training.
请务必记住,算法可以根据数据提出建议,但它们不能取代人的判断。规范分析是一个工具,应将其用作帮助做出决策和制定战略的工具。在理解和限制算法产生的结果时,你的判断非常重要且必要。
It’s important to remember that algorithms can make suggestions based on data, but they can’t replace human judgement. Prescriptive analytics is a tool that should be used as such to help make decisions and come up with strategies. Your judgement is important and needed to give context and limits to what an algorithm comes up with.
此类型的分析回答以下问题:“接下来我们应该做什么”?
This type of analysis answers the question, “What should we do next?”.
一些规范分析的示例是:投资决策、销售:潜在客户评分。
Some examples of prescriptive analysis are: Investment decisions, Sales: Lead scoring.
Data Science - Tools in Demand
数据科学工具用于深入挖掘原始且复杂的数据(非结构化或结构化数据),并使用统计学、计算机科学、预测建模和分析以及深度学习等不同的数据处理技术对其进行处理、提取和分析,从而找到有价值的见解。
Data Science tools are used to dig deeper into raw and complicated data (unstructured or structured data) and process, extract, and analyse it to find valuable insights by using different data processing techniques like statistics, computer science, predictive modelling and analysis, and deep learning.
数据科学家在数据科学生命周期的不同阶段使用各种工具,每天处理泽字节和尧字节的结构化和/或非结构化数据,并从中获取有用的见解。这些工具最重要的是,它们使得无需使用复杂的编程语言即可完成数据科学任务。这是因为这些工具具有已设置好的算法、函数和图形用户界面(GUI)。
Data scientists use a wide range of tools at different stages of the data science life cycle to deal with zettabytes and yottabytes of structured and/or unstructured data every day and get useful insights from it. The most important thing about these tools is that they make it possible to do data science tasks without using complicated programming languages. This is because these tools have algorithms, functions, and graphical user interfaces that are already set up (GUIs).
Best Data Science Tools
市场上有很多数据科学工具。因此,很难决定哪种工具最适合你的旅程和职业生涯。以下图表根据需要表示了一些最好的数据科学工具——
There are a lot of tools for data science in the market. So, it can be hard to decide which one is best for your journey and career. Below is the diagram that reperesents some of the best data science tools according to the need −

SQL
数据科学是对数据的综合研究。要访问数据并对其进行操作,必须从数据库中提取数据,为此需要 SQL。数据科学在很大程度上依赖于关系数据库管理。利用 SQL 命令和查询,数据科学家可以管理、定义、更改、创建和查询数据库。
Data Science is the comprehensive study of data. To access data and work with it, data must be extracted from the database for which SQL will be needed. Data Science relies heavily on Relational Database Management. With SQL commands and queries, a Data Scientist may manage, define, alter, create, and query the database.
一些当代领域采用 NoSQL 技术对其产品数据管理进行了装备,但对于许多商业智能工具和办公流程,SQL 仍然是最佳选择。
Several contemporary sectors have equipped their product data management with NoSQL technology, yet SQL remains the best option for many business intelligence tools and in-office processes.
DuckDB
DuckDB 是一款基于表格的关系型数据库管理系统,它还让您可以使用 SQL 查询来进行分析。它开源且免费,并拥有众多功能,例如更快的分析查询、更简单的操作等等。
DuckDB is a relational database management system based on tables that also lets you use SQL queries to do analysis. It is free and open source, and it has many features like faster analytical queries, easier operations, and so on.
DuckDB 还与数据科学中使用的 Python、R、Java 等编程语言配合使用。您可以使用这些语言来创建、注册并处理数据库。
DuckDB also works with programming languages like Python, R, Java, etc. that are used in Data Science. You can use these languages to create, register, and play with a database.
Beautiful Soup
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取信息或拉取信息。它是一个易于使用的工具,使您可以读取网站的 HTML 内容,从中获取信息。
Beautiful Soup is a Python library that can pull or extract information from HTML or XML files. It is an easy-to-use tool that lets you read the HTML content of websites to get information from them.
该库可帮助数据科学家或数据工程师设置自动网络抓取,这是完全自动数据管道中的一个重要步骤。
This library can help Data Scientists or Data Engineers set up automatic Web scraping, which is an important step in fully automated data pipelines.
它主要用于网络抓取。
It is mainly used for web scrapping.
Scrapy
Scrapy 是一款开源 Python 网络爬取框架,用于抓取大量网页。它是一款网络爬虫,可以爬取和抓取网络。它为您提供了从网站快速获取数据、根据需要处理数据,并以所需的结构和格式存储数据所需的全部工具。
Scrapy is an open-source Python web crawling framework that is used to scrape a lot of web pages. It is a web crawler that can both scrape and crawl the web. It gives you all the tools you need to get data from websites quickly, process them in the way you want, and store them in the structure and format you want.
Selenium
Selenium 是一个免费的开源测试工具,用于在不同的浏览器上测试网络应用程序。Selenium 只能测试网络应用程序,因此无法用于测试桌面或移动应用程序。Appium 和 HP 的 QTP 是可用于测试软件和移动应用程序的另外两个工具。
Selenium is a free, open-source testing tool that is used to test web apps on different browsers. Selenium can only test web applications, so it can’t be used to test desktop or mobile apps. Appium and HP’s QTP are two other tools that can be used to test software and mobile apps.
Python
数据科学家最常使用 Python,这也是最流行的编程语言。Python 在数据科学领域如此受欢迎的一个主要原因是它的易用性和简单的语法。这使得没有工程背景的人也能轻松学习和使用。此外,还有很多开源库和在线指南,用于执行数据科学任务,如机器学习、深度学习、数据可视化等。
Data Scientists use Python the most and it is the most popular programming language. One of the main reasons why Python is so popular in the field of Data Science is that it is easy to use and has a simple syntax. This makes it easy for people who don’t have a background in engineering to learn and use. Also, there are a lot of open-source libraries and online guides for putting Data Science tasks like Machine Learning, Deep Learning, Data Visualization, etc. into action.
python 中数据科学使用最频繁的一些库包括:
Some of the most commonly used libraries of python in data science are −
-
Numpy
-
Pandas
-
Matplotlib
-
SciPy
-
Plotly
R
R 是数据科学中仅次于 Python 的第二常用的编程语言。它最初是为了解决统计问题,但现在已发展成为一个完整的数据科学生态系统。
R is the second most-used programming language in Data Science, after Python. It was first made to solve problems with statistics, but it has since grown into a full Data Science ecosystem.
大多数人使用库 Dpylr 和 readr 来加载数据并对其进行更改和添加。ggplot2 允许您使用不同的方法以图表方式显示数据。
Most people use Dpylr and readr, which are libraries, to load data and change and add to it. ggplot2 allows you use different ways to show the data on a graph.
Tableau
Tableau 是一个可视化分析平台,它正在改变人们和组织使用数据来解决问题的方式。它为人们和组织提供了充分利用其数据的所需工具。
Tableau is a visual analytics platform that is changing the way people and organizations use data to solve problems. It gives people and organizations the tools they need to extract the most out of their data.
在沟通方面,Tableau 非常重要。数据科学家通常需要分解信息,以便其团队、同事、经理和客户能够更好地理解信息。在这些情况下,信息需要易于查看和理解。
When it comes to communication, tableau is very important. Most of the time, Data Scientists have to break down the information so that their teams, colleagues, executives, and customers can understand it better. In these situations, the information needs to be easy to see and understand.
Tableau 帮助团队深入挖掘数据,找出通常隐藏在其中的见解,然后以既美观又易于理解的方式展示数据。Tableau 还有助于数据科学家快速浏览数据,在浏览数据的过程中添加和删除内容,最终以交互方式描述所有重要内容。
Tableau helps teams dig deeper into data, find insights that are usually hidden, and then show that data in a way that is both attractive and easy to understand. Tableau also helps Data Scientists quickly look through the data, adding and removing things as they go so that the end result is an interactive picture of everything that matters.
Tensorflow
TensorFlow 是一个开源且免费使用的机器学习平台,它使用数据流图。该图的节点是数学运算,边缘是流经它们的多维数据数组(张量)。它的架构非常灵活,机器学习算法可以描述为协同工作的运算图。可以在便携式设备、台式机和高端服务器等不同平台上的 GPU、CPU 和 TPU 上对其进行训练和运行,而无需更改代码。这意味着来自各种背景的程序员可以使用相同的工具进行合作,从而大大提高他们的生产力。Google 大脑团队创建该系统是为了研究机器学习和深度神经网络(DNN)。但是,该系统足够灵活,可用于广泛的其他领域。
TensorFlow is a platform for machine learning that is open-source, free to use and uses data flow graphs. The nodes of the graph are mathematical operations, and the edges are the multidimensional data arrays (tensors) that flow between them. The architecture is so flexible; machine learning algorithms can be described as a graph of operations that work together. They can be trained and run on GPUs, CPUs, and TPUs on different platforms, like portable devices, desktops, and high-end servers, without changing the code. This means that programmers from all kinds of backgrounds can work together using the same tools, which makes them much more productive. The Google Brain Team created the system to study machine learning and deep neural networks (DNNs). However, the system is flexible enough to be used in a wide range of other fields as well.
Scikit-learn
Scikit-learn 是一个易于使用的流行开源 Python 机器学习库。它拥有广泛的监督和无监督学习算法,以及用于模型选择、评估和数据预处理的工具。Scikit-learn 在学术界和商业中都被广泛使用。它以速度快、可靠且易于使用而著称。
Scikit-learn is a popular open-source Python library for machine learning that is easy to use. It has a wide range of supervised and unsupervised learning algorithms, as well as tools for model selection, evaluation, and data preprocessing. Scikit-learn is used a lot in both academia and business. It is known for being fast, reliable, and easy to use.
它还具有减少维度、选择特征、提取特征、使用集成技术和使用程序附带数据集的功能。我们将依次查看这些组件。
It also has features for reducing the number of dimensions, choosing features, extracting features, using ensemble techniques, and using datasets that come with the program. We will look at each of these things in turn.
Keras
Google 的 Keras 是一个用于创建神经网络的高级深度学习 API。它是用 Python 构建的,用于简化神经网络的构建。此外,它支持不同的后端神经网络计算。
Google’s Keras is a high-level deep learning API for creating neural networks. It is built in Python and is used to facilitate neural network construction. Moreover, different backend neural network computations are supported.
由于它提供具有高度抽象的 Python 接口和大量用于计算的后端,因此 Keras 相对容易理解和使用。这使得 Keras 比其他深度学习框架慢,但对初学者非常友好。
Since it offers a Python interface with a high degree of abstraction and numerous backends for computation, Keras is reasonably simple to understand and use. This makes Keras slower than other deep learning frameworks, but very user-friendly for beginners.
Jupyter Notebook
Jupyter Notebook 是一个开源在线应用程序,允许创建和共享带有实时代码、方程式、可视化效果和叙述性文本的文档。它在数据科学家和机器学习从业者中很受欢迎,因为它为数据探索和分析提供了一个交互式环境。
Jupyter Notebook is an open-source online application that allows the creation and sharing of documents with live code, equations, visualisations, and narrative texts. It is popular among data scientists and practitioners of machine learning because it offers an interactive environment for data exploration and analysis.
使用 Jupyter Notebook,您可以在网络浏览器中编写并运行 Python 代码(以及用其他编程语言编写的代码)。结果显示在同一文档中。这使您可以将代码、数据和文本说明全部放在一个地方,从而可以轻松地分享和复制您的分析结果。
With Jupyter Notebook, you can write and run Python code (and code written in other programming languages) right in your web browser. The results are shown in the same document. This lets you put code, data, and text explanations all in one place, making it easy to share and reproduce your analysis.
Dash
Dash 是数据科学的一个重要工具,因为它可以让您使用 Python 创建交互式网络应用程序。它使得创建数据可视化仪表盘和应用变得既轻松又快捷,而无需了解如何为网络编写代码。
Dash is an important tool for data science because it lets you use Python to create interactive web apps. It makes it easy and quick to create data visualisation dashboards and apps without having to know how to code for the web.
Data Science - Careers
有许多工作与数据科学家领域相关或重叠。
There are several jobs available that are linked to or overlap with the field of data scientist.
与数据科学相关的工作清单−
List of jobs related to data science −
以下是与数据科学家相关的工作清单。
Below is a list of jobs that are related to data scientists.
-
Data Analyst
-
Data Scientist
-
Database Administrator
-
Big Data Engineer
-
Data Mining Engineer
-
Machine Learning Engineer
-
Data Architect
-
Hadoop Engineer
-
Data Warehouse Architect
Data Analyst
数据分析师分析数据集,以找出客户相关问题的解决方案。此信息也由数据分析师传达给管理层和其他利益相关者。这些人从事于各种领域的工作,包括商业、银行、刑事司法、科学、医疗和政府。
A data analyst analyses data sets to identify solutions to customer-related issues. This information is also communicated to management and other stakeholders by a data analyst. These people work in a variety of fields, including business, banking, criminal justice, science, medical, and government.
数据分析师是具有专业知识和能力,可以将原始数据转换为可用于做出业务决策的信息和见解的人。
A data analyst is someone who has the expertise and abilities to transform raw data into information and insight that can be utilized to make business choices.
Data Scientist
数据科学家是一个使用分析、统计和编程能力获取海量数据的人。他们有义务利用数据为组织的特定需求创建个性化解决方案。
A Data Scientist is a professional who uses analytical, statistical, and programming abilities to acquire enormous volumes of data. It is their obligation to utilize data to create solutions that are personalized to the organization’s specific demands.
公司在日常运营中越来越依赖数据。数据科学家检查原始数据并从中提取有意义的含义。然后,他们利用这些数据来识别趋势并提供业务增长和竞争所需的解决方案。
Companies are increasingly relying on data in their day-to-day operations. A data scientist examines raw data and pulls meaningful meaning from it. They then utilize this data to identify trends and provide solutions that a business needs to grow and compete.
Database Administrator
数据库管理员负责管理和维护业务数据库。数据库管理员负责执行数据管理策略,并确保企业数据库在发生内存丢失时可操作并得到备份。
Database administrators are responsible for managing and maintaining business databases. Database administrators are responsible for enforcing a data management policy and ensuring that corporate databases are operational and backed up in the case of memory loss.
数据库管理员(有时称为数据库经理)管理业务数据库,以确保信息得到安全维护,并且只有获得授权的人员才能访问。数据库管理员还必须保证这些人能够在他们需要的时间以他们需要的方式访问他们需要的信息。
Database administrators (sometimes known as database managers) administer business databases to ensure that information is maintained safely and is only accessible to authorized individuals. Database administrators must also guarantee that these persons have access to the information they need at the times they want it and in the format they require.
Big Data Engineer
大数据工程师为一家公司创建、测试和维护使用大数据解决方案。他们的工作是从许多不同来源收集大量数据,并确保以后使用数据的人员能够快速轻松地获得这些数据。大数据工程师基本上确保公司的 data pipeline 可扩展、安全且能够为多个用户服务。
Big data engineers create, test, and maintain solutions for a company that use Big Data. Their job is to gather a lot of data from many different sources and make sure that people who use the data later can get to it quickly and easily. Big data engineers basically make sure that the company’s data pipelines are scalable, secure, and able to serve more than one user.
当今制作和使用的数据量似乎是无穷无尽的。问题是如何保存、分析和展示这些信息。大数据工程师处理这些问题的办法和技术。
The amount of data made and used today seems to be endless. The question is how this information will be saved, analyzed, and shown. A big data engineer works on the methods and techniques to deal with these problems.
Data Mining Engineer
数据挖掘是对信息进行分类的过程,以查找企业可用于改善其系统和操作的答案。如果数据没有以正确的方式进行处理和展示,那么它就没有多大用处。
Data mining is the process of sorting through information to find answers that a business can use to improve its systems and operations. Data isn’t very useful if it isn’t manipulated and shown in the right way.
数据挖掘工程师设置并运行用于存储和分析数据的系统。总体任务包括设置数据仓库、组织数据以使其易于查找以及安装数据流经的管道。数据挖掘工程师需要知道数据的来源、使用方法以及谁将使用它。ETL(提取、转换和加载)是一个数据挖掘工程师的关键首字母缩略词。
A data mining engineer sets up and runs the systems that are used to store and analyze data. Overarching tasks include setting up data warehouses, organizing data so it’s easy to find, and installing conduits for data to flow through. A data mining engineer needs to know where the data comes from, how it will be used, and who will use it. ETL, which stands for "extract, transform, and load," is the key acronym for a data mining engineer.
Machine Learning Engineer
机器学习 (ML) 开发人员知道如何使用数据训练模型。然后,这些模型用于自动执行诸如图像分组、语音识别和市场预测之类的事情。
A machine learning (ML) developer knows how to train models with data. The models are then used to automate things like putting images into groups, recognising speech, and predicting the market.
机器学习可用于不同的角色。数据科学家和人工智能 (AI) 工程师的工作往往存在一定的重叠之处,有时这两个工作甚至会相互混淆。机器学习是人工智能的一个子领域,专注于查看数据以查找输入和预期输出之间的联系。
Different roles can be given to machine learning. There is often some overlap between the jobs of a data scientist and an AI (artificial intelligence) engineer, and sometimes the two jobs are even confused with each other. Machine learning is a subfield of AI that focuses on looking at data to find connections between what was put in and what was wanted to come out.
机器学习开发人员确保每个问题都有一个完美的解决方案。只有通过仔细处理数据并选择最适合情况的算法,才能获得最佳结果。
A machine learning developer makes sure that each problem has a solution that fits it perfectly. Only by carefully processing the data and choosing the best algorithm for the situation can you get the best results.
Data Architect
数据架构师通过找到设置和构建它的最佳方式来构建和管理公司的数据库。他们与数据库管理员和分析师合作以确保公司数据易于访问。任务包括创建数据库解决方案、确定需求和编写设计报告。
Data architects build and manage a company’s database by finding the best ways to set it up and structure it. They work with database managers and analysts to make sure that company data is easy to get to. Tasks include making database solutions, figuring out what needs to be done, and making design reports.
数据架构师是一位设计组织的数据策略的专家,其中包括数据质量标准、数据在组织内的流动方式以及数据的安全存储方式。数据管理专业人员看待事物的态度将业务需求转化为技术需求。
A data architect is an expert who comes up with the organization’s data strategy, which includes standards for data quality, how data moves around the organisation, and how data is kept safe. The way this professional in data management sees things is what turns business needs into technical needs.
作为业务和技术之间的关键纽带,对数据架构师的需求正与日俱增。
As the key link between business and technology, data architects are becoming more and more in demand.
Hadoop Engineer
Hadoop 开发人员负责创建和编码 Hadoop 应用程序。Hadoop 是一个开源框架,用于管理和存储处理大量数据并在集群系统上运行的应用程序。基本上,Hadoop 开发人员构建应用程序来帮助公司管理和跟踪其大数据。
Hadoop Developers are in charge of making and coding Hadoop applications. Hadoop is an open-source framework for managing and storing applications that work with large amounts of data and run on cluster systems. Basically, a Hadoop developer makes apps that help a company manage and keep track of its big data.
Hadoop 开发人员负责编写 Hadoop 应用程序的代码。此角色类似于软件开发人员。这两个角色非常相似,但前者属于大数据领域。我们来看看 Hadoop 开发人员必须做什么以更好地了解此角色。
A Hadoop Developer is the person in charge of writing the code for Hadoop applications. This job is like being a Software Developer. The jobs are pretty similar, but the first one is in the Big Data domain. Let’s look at some of the things a Hadoop Developer has to do to get a better idea of what this job is about.
Data Warehouse Architect
数据仓库架构师负责提出数据仓库解决方案并使用标准数据仓库技术来提出计划,以最大程度地帮助企业或组织。在设计特定架构时,数据仓库架构师通常会考虑雇主的目标或客户的需求。然后,该架构可以由工作人员维护并用于实现目标。
Data warehouse architects are responsible coming up with solutions for data warehouses and working with standard data warehouse technologies to come up with plans that will help a business or organization the most. When designing a specific architecture, data warehouse architects usually take into account the goals of the employer or the needs of the client. This architecture can then be maintained by the staff and used to achieve the goals.
因此,就像普通建筑师设计建筑物或海军建筑师设计船舶一样,数据仓库架构师设计和帮助启动数据仓库,根据客户的需求对其进行定制。
So, just like a regular architect designs a building or a naval architect designs a ship, data warehouse architects design and help launch data warehouses, customizing them to meet the needs of the client.
Data Science Job Trends 2022
到 2022 年,对数据科学家的需求将大幅增长。IBM 表示,在 2020 年将创造 364,000 到 2,720,000 个新工作岗位。这种需求将持续增长,很快将出现 700,000 个职位空缺。
By 2022, there will be a big rise in the need for data scientists. IBM says that between 364,000 and 2,720,000 new jobs will be created in the year 2020. This demand will continue to rise, and soon there will be a 700,000 openings.
Glassdoor 表示,其网站上的头号工作是数据科学家。未来,这个职位不会有任何改变。也有人认为数据科学的职位空缺将持续 45 天。这比平均劳动力市场长五天。
Glassdoor says that the top job on its site is for a Data Scientist. In the future, nothing will change about this position. It is also looked at that the job openings in data science are open for 45 days. This is five days longer than the average job market.
IBM 将与学校和企业合作,为有抱负的数据科学家创造一个工作学习环境。这将有助于缩小技能差距。
IBM will work with schools and businesses to create a work-study environment for aspiring data scientists. This will help close the skills gap.
对数据科学家的需求以二次方速度增长。这是因为新的工作和行业已经产生。数据的不断增加和不同类型的数据加剧了这种情况。
The need for data scientists is growing at a rate that is a power of two. This is because new jobs and industries have been created. This is made worse by the growing amount of data and the different kinds of data.
未来,数据科学家只会扮演更多角色,而且数量也会更多。数据科学家的工作包括数据工程师、数据科学经理和大数据架构师。此外,金融和保险行业正成为数据科学家的最大雇主之一。
In the future, there will only be more roles for data scientists and more of them. Data scientist jobs include data engineer, data science manager, and big data architect. Also, the financial and insurance sectors are becoming some of the biggest employers of data scientists.
随着培训数据科学家的机构越来越多,使用数据的人也可能越来越多。
As the number of institutes that train data scientists grows, it is likely that more and more people will know how to use data.
Data Science - Scientists
数据科学家是一位经过培训的专业人士,他们分析并理解数据。他们利用其对数据科学的了解来帮助企业做出更好的决策并更好地运营。大多数数据科学家在数学、统计学和计算机科学方面都有丰富的经验。他们使用这些信息来查看大量数据并找出趋势或模式。数据科学家还可能提出收集和存储数据的新方法。
A data scientist is a trained professional who analyzes and makes sense of data. They use their knowledge of data science to help businesses make better decisions and run better. Most data scientists have a lot of experience with math, statistics, and computer science. They use this information to look at big sets of data and find trends or patterns. Data scientists might also come up with new ways to collect and store data.
How to become a Data Scientist?
迫切需要懂得如何使用数据分析为公司提供竞争优势的人员。作为一名数据科学家,您将根据数据做出业务解决方案和分析。
There is a big need for people who know how to use data analysis to give their companies a competitive edge. As a data scientist, you will make business solutions and analytics that are based on data.
成为数据科学家的途径有很多,但由于它通常是一份高级工作,因此大多数数据科学家都拥有数学、统计学、计算机科学和其他相关领域的学位。
There are many ways to become a Data Scientist, but because it’s usually a high-level job, most Data Scientists have degrees in math, statistics, computer science, and other related fields.
以下是成为数据科学家的步骤:
Below are some steps to become a data scientist −
Step 1 − Right Data Skills
如果你没有数据相关的工作经验,那么你可以成为一名数据科学家,但你需要获得从事数据科学的必要基础。
You can become a Data Scientist if you have no data-related job experience, but you will need to acquire the necessary foundation to pursue a data science profession.
数据科学家是一个高级职位;在达到这一专业水平之前,你应该在相关主题中获得全面的知识基础。这可能包括数学、工程、统计、数据分析、编程或信息技术;一些数据科学家从银行或棒球侦查开始他们的职业生涯。
A Data Scientist is a high-level role; prior to attaining this level of expertise, you should acquire a comprehensive knowledge foundation in a related topic. This might include mathematics, engineering, statistics, data analysis, programming, or information technology; some Data Scientists began their careers in banking or baseball scouting.
但是,无论你从哪个领域开始,你都应该从 Python、SQL 和 Excel 开始。这些能力对于处理和组织原始数据非常重要。熟悉 Tableau 有利,这是一种你经常用来构建可视化效果的工具。
But regardless of the area you begin in, you should begin with Python, SQL, and Excel. These abilities will be important for processing and organizing raw data. It is beneficial to be acquainted with Tableau, a tool you will use often to build visuals.
Step 2 − Learn Data Science Fundamentals
数据科学训练营可能是学习或提高数据科学原理的完美方法。你可以参考 Data Science BootCamp ,其中包含了详细涵盖的每个主题。
A data science boot camp might be a perfect approach to learn or improve upon the principles of data science. You can refer Data Science BootCamp which has each and every topic covered in detail.
学习数据科学基础知识,例如如何收集和存储数据、分析和建模数据,以及使用数据科学工具集中所有工具(例如 Tableau 和 PowerBI 等)显示和呈现数据。
Learn data science fundamentals such as how to gather and store data, analyze and model data, and display and present data using every tool in the data science arsenal, such as Tableau and PowerBI, among others.
在培训结束时,你应该能够利用 Python 和 R 创建评估行为和预测未知数的模型,以及使用户友好的格式重新打包数据。
You should be able to utilize Python and R to create models that assess behavior and forecast unknowns, as well as repackage data in user-friendly formats, by the conclusion of your training.
一些数据科学工作清单规定高级学位是先决条件。有时,这是不可协商的,但当需求超过供应时,这越来越多地揭示了真相。也就是说,必要才能的证明常常超越了仅凭证书。
Several Data Science job listings state advanced degrees as a prerequisite. Sometimes, this is non-negotiable, but when demand exceeds supply, this increasingly reveals the truth. That is, proof of the necessary talents often surpasses credentials alone.
招聘经理最关心的是你如何很好地展示你对该科目的了解,越来越多的人认识到,不必以传统方式去做。
Hiring managers care most about how well you can show that you know the subject, and more and more people are realizing that this doesn’t have to be done in the traditional ways.
Data Science Fundamentals
-
Collect and store data.
-
Analyze and model the data.
-
Build a model that can make prediction using the given data.
-
Visualizing and presenting data in user-friendly forms.
Step 3 − Learn Key Programming Languages for Data Science
数据科学家使用各种工具和程序,这些工具和程序专门用于清理、分析和建模数据。数据科学家需要了解的不仅仅是 Excel。他们还需要了解一门统计编程语言,如 Python、R 或 Hive,以及一门查询语言,如 SQL。
Data Scientists use a variety of tools and programs that were made just for cleaning, analyzing, and modeling data. Data Scientists need to know more than just Excel. They also need to know a statistical programming language like Python, R, or Hive, as well as a query language like SQL.
RStudio 服务器为在服务器上使用 R 工作提供了开发环境,它是数据科学家最重要的工具之一。另一个流行的软件是开源 Jupyter Notebook,它可用于统计建模、数据可视化、机器学习等。
RStudio Server, which provides a development environment for working with R on a server, is one of the most important tools for a Data Scientist. Another popular software is the open-source Jupyter Notebook, which can be used for statistical modeling, data visualization, machine learning, and more.
机器学习最常用于数据科学。它指的是使用人工智能的工具,使系统能够学习和改进,而无需专门对其进行编程。
Machine learning is being used most in data science. This refers to tools that use artificial intelligence to give systems the ability to learn and get better without being specifically programmed to do so.
Step 4 − Learn how to do visualizations and practice them
练习使用 Tableau、PowerBI、Bokeh、Plotly 或 Infogram 等程序从头开始制作自己的可视化效果。找到让数据自己说明问题的最佳方式。
Practice making your own visualizations from scratch with programs like Tableau, PowerBI, Bokeh, Plotly, or Infogram. Find the best way to let the data speak for itself.
此步骤中通常使用 Excel。尽管电子表格背后的基本思想很简单——通过关联单元格中的信息进行计算或绘图——但 Excel 在 30 多年后仍然非常有用,没有它几乎不可能进行数据科学。
Excel is generally used in this step. Even though the basic idea behind spreadsheets is simple-making calculations or graphs by correlating the information in their cells-Excel is still very useful after more than 30 years, and it is almost impossible to do data science without it.
但制作美丽的图片仅仅是个开始。作为一名数据科学家,你还需要能够使用这些可视化效果向现场观众展示你的调查结果。你可能已经具备了这些沟通技巧,但如果没有,也不必担心。每个人都可以通过练习来提高自身。如果你需要,可以从向一个朋友甚至你的宠物进行演示开始,然后再进行小组演示。
But making beautiful pictures is just the start. As a Data Scientist, you’ll also need to be able to use these visualizations to show your findings to a live audience. You may have these communication skills already, but if not, don’t worry. Anyone can get better with practice. If you need to, start small by giving presentations to one friend or even your pet before moving on to a group.
Step 5 − Work on some Data Science projects that will help develop your practical data skills
一旦你了解了数据科学家使用的编程语言和数字工具的基础知识,你就可以开始使用它们来练习和提高你的新技能。尝试承担需要广泛技能的项目,例如使用 Excel 和 SQL 管理和查询数据库,以及使用 Python 和 R 使用统计方法分析数据、构建分析行为并为你提供新见解的模型,以及使用统计分析预测你不知道的事情。
Once you know the basics of the programming languages and digital tools that Data Scientists use, you can start using them to practice and improve your new skills. Try to take on projects that require a wide range of skills, like using Excel and SQL to manage and query databases and Python and R to analyze data using statistical methods, build models that analyze behavior and give you new insights, and use statistical analysis to predict things you don’t know.
在你练习时,请尝试涵盖该过程的不同部分。从研究公司或市场领域开始,然后定义和收集适合手头任务的正确数据。最后,清理并测试该数据,以使其尽可能有用。
As you practice, try to cover different parts of the process. Start with researching a company or market sector, then define and collect the right data for the task at hand. Finally, clean and test that data to make it as useful as possible.
最后,你可以制作和使用自己的算法来分析和建模数据。然后你可以将结果放入简单易读的可视化或仪表板中,供用户使用它与你的数据互动并就此询问问题。你甚至可以尝试向其他人展示你的调查结果以提高你的沟通能力。
Lastly, you can make and use your own algorithms to analyze and model the data. You can then put the results into easy-to-read visuals or dashboards that users can use to interact with your data and ask questions about it. You could even try showing your findings to other people to get better at communicating.
你也应该习惯处理不同类型的数据,比如文本、结构化数据、图像、音频甚至视频。每个行业都有其自己的数据类型,这些数据可以帮助领导者制定更好的、更明智的决策。
You should also get used to working with different kinds of data, like text, structured data, images, audio, and even video. Every industry has its own types of data that help leaders make better, more informed decisions.
作为一名职业数据科学家,你可能只精通其中一两个领域,但作为一名培养技能的初学者,你应该学习尽可能多类型的基础知识。
As a working Data Scientist, you’ll probably be an expert in just one or two, but as a beginner building your skillset, you’ll want to learn the basics of as many types as possible.
承担更复杂项目将让你有机会了解如何用不同方式来使用数据。一旦你知道如何使用描述性分析法来查找数据中的模式,你就可以更好地准备尝试诸如数据挖掘、预测模型和机器学习等更复杂的统计方法来预测未来事件或提出建议。
Taking on more complicated projects will give you the chance to see how data can be used in different ways. Once you know how to use descriptive analytics to look for patterns in data, you’ll be better prepared to try more complicated statistical methods like data mining, predictive modelling, and machine learning to predict future events or even make suggestions.
Step 6 − Make a Portfolio that shows your Data Science Skills
一旦你完成初步研究、接受培训并通过制作各种令人印象深刻的项目来实践你的新技能,下一步就是通过制作精美的作品集来展示你的新技能,这会帮你获得理想的工作。
Once you’ve done your preliminary research, gotten the training, and practiced your new skills by making a wide range of impressive projects, the next step is to show off your new skills by making the polished portfolio that will get you your dream job.
事实上,在你求职时,你的作品集可能是最重要的东西。如果你想成为一名数据科学家,你或许应该在 GitHub 上展示你的作品,而不仅仅是(或加上)你自己的网站。GitHub 能让你轻松展示你的工作、流程和结果,同时也能在公共网络中提升你的个人形象。不过,不要就此止步。
In fact, your portfolio might be the most important thing you have when looking for a job. If you want to be a Data Scientist, you might want to show off your work on GitHub instead of (or in addition to) your own website. GitHub makes it easy to show your work, process, and results while also raising your profile in a public network. Don’t stop there, though.
用你的数据加入一个引人入胜的故事,并展示你试图解决的问题,以便雇主能够看到你有多好。你可以在 GitHub 上将你的代码放在更大的图片中,而不仅仅是单凭代码本身,这使得你的贡献更容易理解。
Include a compelling story with your data and show the problems you’re trying to solve so the employer can see how good you are. You can show your code in a bigger picture on GitHub instead of just by itself, which makes your contributions easier to understand.
在你申请特定工作时,不必列出你所有的工作。仅强调最贴合你要申请的工作的几个部分,这些部分最能展示你贯穿整个数据科学流程的技能范围,从使用基本的数据库开始,到定义问题、清理数据、建立模型并找到解决方案。
Don’t list all of your work when you’re applying for a specific job. Highlight just a few pieces that are most relevant to the job you’re applying for and that best show your range of skills throughout the whole data science process, from starting with a basic data set to defining a problem, cleaning up, building a model, and finding a solution.
你的作品集是你展示自己不仅能处理数字还能有效沟通的机会。
Your portfolio is your chance to show that you can do more than just crunch numbers and communicate well.
Step 7 − Demonstrate Your Abilities
你独立完成的一个出色的项目可以是一个展示你技能并给可能会雇用你的招聘经理留下深刻印象的绝佳方式。
A well-done project that you do on your own can be a great way to show off your skills and impress hiring managers who might hire you.
选择一些真正感兴趣的事物,向其中提问,并尝试用数据回答这个问题。
Choose something that really interests you, ask a question about it, and try to answer that question with data.
记录你的旅程,并通过以美丽的方式呈现你的调查结果并说明你是如何做到的来炫耀你的技术技能和创造力。你的数据应该附带一个引人入胜的故事,该故事展示了你解决的问题,突出你的流程和所采取的创造性步骤,以便雇主能够看出你的价值。
Document your journey and show off your technical skills and creativity by presenting your findings in a beautiful way and explaining how you got there. Your data should be accompanied by a compelling narrative that shows the problems you’ve solved, highlighting your process and the creative steps you’ve taken, so that an employer can see your worth.
加入 Kaggle 等在线数据科学网络是另一种展示你投身于社区、作为一个有志向的数据科学家展示你的技能以及不断提升你的专业知识和影响力的绝佳方式。
Joining an online data science network like Kaggle is another great way to show that you’re involved in the community, show off your skills as an aspiring Data Scientist, and continue to grow both your expertise and your reach.
Step 8 − Start Applying to Data Science Jobs
数据科学领域有很多工作。在学习基础知识后,人们往往会继续专门从事不同子领域,例如数据工程师、数据分析师或机器学习工程师等。
There are many jobs in the field of data science. After learning the basics, people often go on to specialize in different subfields, such as Data Engineers, Data Analysts, or Machine Learning Engineers, among many others.
了解公司重视什么以及他们正在做些什么,并确保它符合你的技能、目标和未来想做的事情。而且不要只盯着硅谷。波士顿、芝加哥和纽约等城市难以找到技术人才,因此有很多机会。
Find out what a company values and what they’re working on, and make sure it fits with your skills, goals, and what you want to do in the future. And don’t just look in Silicon Valley. Cities like Boston, Chicago, and New York are having trouble finding technical talent, so there are lots of opportunities.
Data Scientist - Salary
随着数字化在世界范围内的推广,数据科学已成为世界上薪酬最高的工作之一。在印度,数据科学家的年收入在 18 万卢比至 1 千万卢比之间,具体取决于他们的资格、技能和经验。
As digitalization has spread around the world, data science has become one of the best-paying jobs in the world. In India, data scientists make between 1.8 Lakhs and 1 Crore a year, depending on their qualifications, skills, and experience.
Top Factors that decide Data Scientist Salaries
影响数据科学家薪酬的一些因素。当然,最重要的因素是您的经验,但印度数据科学家的薪酬还基于其技能、工作角色、就职的公司和居住地。
There are a few things that affect the salary of a data scientist. Of course, what matters most is your experience, but a data scientist’s salary in India is also based on their skills, job roles, the company they work for, and where they live.
Salary Based on Skills
印度的数据科学薪酬还基于您在该领域的熟练程度。您在该领域拥有的技能越多,您获得更高薪酬的可能性就越大。即使在印度,对于具备不同 IT 技能的人来说,数据科学家的起薪也更高。如果您的简历脱颖而出,招聘人员会更加关注您。如果您具备机器学习、Python、统计分析和大数据分析等技能,您就有可能获得更高的薪酬。
The data science salary in India is also based on how skilled you are in the pitch. The more skills you have in your field, the more likely you are to get a higher salary. Even the starting salary for a data scientist in India is higher for people with different IT skills. Recruiters will notice you more if your resume stands out. You might be able to get a higher salary if you have skills like Machine Learning, Python, Statistical Analysis, and Big Data Analytics.
Salary Based on the Experience
在印度数据科学工作的薪酬中,经验是一个主要因素。PayScale 称,在印度经验不足一年的新人数据科学家的平均工资约为 577,893。具有 1-4 年经验的人员的平均工资为 809,952。具有 5-9 年经验的职业生涯中的数据科学家年收入最高可达 1448,144。在印度,具有 1-19 年投球经验的人员每年平均收入可达 1944,566。
When it comes to data science jobs salaries in India, experience is a main factor. PayScale says that the average salary for a new data scientist in India with less than one year of experience is about 5,77,893. The average salary for someone with 1–4 years of experience is 8,09,952. With 5–9 years of experience, a data scientist in the middle of their career could make up to 14,48,144 per year. And in India, a person with 1–19 years of experience in the pitch can make an average of 19,44,566 per year.
Salary Based on Location
地点是影响您在印度数据科学工作中获得多少报酬的另一个因素。印度有许多大城市聘用数据科学家,但不同城市的薪酬待遇各不相同。
Location is another factor that affects how much you get paid for a data science job in India. There are a lot of big cities in India that hire data scientists, but the packages vary from city to city.
Salary Based on Companies
许多公司定期聘用数据科学家,但大多数时候他们有不同的工作或角色。如果您为其中一家公司工作,您的薪酬将取决于您获得的工作。印度的其他公司每年也会向其数据科学家支付不同的薪酬。在接受工作邀请之前,您可以随时了解印度数据科学家的月收入或年收入。
Many companies hire data scientists on a regular basis, but most of the time, they have different jobs or roles. If you work for one of these companies, your salary will depend on what job you get. Other companies in India also pay their data scientists different salaries each year. Before you accept a job offer, you can always find out how much a data scientist in India makes per month or per year at other companies.
Data Scientist Salary in India
下表显示了印度不同数据科学专家平均工资 −
Given below is the table that shows the average salary of different data science profiles in India −
S.No |
Job Title |
Average Annual Base Salary in India |
1 |
Data Scientist |
₹ 10.0 LPA |
2 |
Data Architect |
₹ 24.7 LPA |
3 |
Data Engineer |
₹ 8.0 LPA |
4 |
Data Analyst |
₹ 4.2 LPA |
5 |
Database Administrator |
₹ 10.0 LPA |
6 |
Machine Learning Engineer |
₹ 6.5 LPA |
上方表格中的数据取自 Ambition Box。
The data in the table above is taken from Ambition Box.
Data Scientist Salary in USA
以下是展示美国不同数据科学专业人员平均工资的表格:
Given below is the table that shows the average salary of different data science profiles in USA −
S.No |
Job Title |
Average Annual Base Salary in USA |
1 |
Data Scientist |
$123,829 |
2 |
Data Architect |
$1,28,205 |
3 |
Data Engineer |
$126,443 |
4 |
Data Analyst |
$71,047 |
5 |
Database Administrator |
$90,078 |
6 |
Machine Learning Engineer |
$146,799 |
上表中的数据取自 Indeed。
The data in the table above is taken from Indeed.
美利坚合众国支付的平均数据科学家工资最高,其次是澳大利亚、加拿大和德国。
The United States of America pays the highest data scientist salaries on average, followed by Australia, Canada, and Germany.
据 Payscale 称,经验不足 1 年的入门级数据科学家可以期望获得 589,126 印度卢比的平均总薪酬(包括小费、奖金和加班费),该数据基于 498 份工资单计算得出。拥有 1-4 年经验的职业生涯早期数据科学家可以获得 830,781 印度卢比的平均总薪酬,该数据基于 2,250 份工资单计算得出。拥有 5-9 年经验的职业生涯中期数据科学家可以获得 1,477,290 印度卢比的平均总薪酬,该数据基于 879 份工资单计算得出。拥有 10-19 年经验的资深数据科学家可以获得 1,924,803 印度卢比的平均总薪酬,该数据基于 218 份工资单计算得出。在职业生涯后期(20 年及以上),员工可以获得 1,350,000 印度卢比的平均总薪酬。
According to Payscale, an entry-level Data Scientist with less than 1-year experience can expect to earn an average total compensation (includes tips, bonus, and overtime pay) of ₹589,126 based on 498 salaries. An early career Data Scientist with 1-4 years of experience earns an average total compensation of ₹830,781 based on 2,250 salaries. A mid-career Data Scientist with 5-9 years of experience earns an average total compensation of ₹1,477,290 based on 879 salaries. An experienced Data Scientist with 10-19 years of experience earns an average total compensation of ₹1,924,803 based on 218 salaries. In their late career (20 years and higher), employees earn an average total compensation of ₹1,350,000.
近年来,技术的进步使数据科学在许多不同领域变得更加重要。数据科学不仅仅用于收集和分析数据。它现在是一个拥有许多不同角色的多学科领域。随着高薪酬和职业生涯增长的保障,越来越多的人每天都涌入数据科学领域。
In recent years, improvements in technology have made Data Science more important in many different fields of work. Data Science is used for more than just collecting and analyzing data. It is now a multidisciplinary field with many different roles. With high salaries and guaranteed career growth, more and more people are getting into the field of data science every day.
Data Science - Resources
本文列出了 2023 年你可以参加以提升你的技能并获得最佳的数据科学家工作之一的最佳数据科学项目和课程。你应该参加其中一项数据科学家的在线课程和认证,以踏上精通数据科学的正确道路。
This article lists the best programs and courses in data science that you can take to improve your skills and get one of the best data scientist jobs in 2023. You should take one of these online courses and certifications for data scientists to get started on the right path to mastering data science.
Top Data Science Courses
在这一部分,我们将讨论互联网上一些流行的数据科学课程。
In this section we will discuss some the popular courses for data science that are available on the internet.
编制 2023 年顶级数据科学课程列表时考虑了多种因素/方面,包括:
A variety of factors/aspects were considered when producing the list of top data science courses for 2023, including −
@s0 − 编译列表时考虑了教学大纲的广度,以及它满足不同经验水平的有效程度。
Curriculum Covered − The list is compiled with the breadth of the syllabus in mind, as well as how effectively it has been tailored to fit varied levels of experience.
Course Features and Outcomes − 我们还讨论了课程成果和其他方面,比如查询解决、实践项目等,这将帮助学生获得适销对路的技能。
Course Features and Outcomes − We have also discussed the course outcomes and other aspects, such as Query resolve, hands-on projects, and so on, that will help students obtain marketable skills.
Course Length − 我们已经计算了每门课程的时长。
Course Length − We have calculated the length of each course.
Skills Required − 我们已经讨论了申请者参加课程必须具备的技能要求。
Skills Required − We have addressed the required skills that applicants must have in order to participate in the course.
Course Fees − 根据每门课程的特点和价格对课程进行评级,确保你物有所值。
Course Fees − Each course is graded based on its features and prices to ensure that you get the most value for your money.
Course Highlights
-
Covers all areas of data science, beginning with the fundamentals of programming (binary, loops, number systems, etc.) and on through intermediate programming subjects (arrays, OOPs, sorting, recursion, etc.) and ML Engineering (NLP, Reinforcement Learning, TensorFlow, Keras, etc.).
-
Lifetime access.
-
30-Days Money Back Guarantee.
-
After completion certificate.
Course Duration: 94 小时。
Course Duration: 94 hours.
查看课程详情 here
Check the course details here
Course Highlights
-
This course will enable you to build a Data Science foundation, whether you have basic Python skills or not. The code-along and well planned-out exercises will make you comfortable with the Python syntax right from the outset. At the end of this short course, you’ll be proficient in the fundamentals of Python programming for Data Science and Data Analysis.
-
In this truly step-by-step course, every new tutorial video is built on what you have already learned. The aim is to move you one extra step forward at a time, and then, you are assigned a small task that is solved right at the beginning of the next video. That is, you start by understanding the theoretical part of a new concept first. Then, you master this concept by implementing everything practically using Python.
-
Become a Python developer and Data Scientist by enrolling in this course. Even if you are a novice in Python and data science, you will find this illustrative course informative, practical, and helpful. And if you aren’t new to Python and data science, you’ll still find the hands-on projects in this course immensely helpful.
Course Duration: 14 小时
Course Duration: 14 hour
查看课程详情 here.
Check course details here.
Course Description
-
The course demonstrates the importance and advantages of R language as a start, then it presents topics on R data types, variable assignment, arithmetic operations, vectors, matrices, factors, data frames and lists. Besides, it includes topics on operators, conditionals, loops, functions, and packages. It also covers regular expressions, getting and cleaning data, plotting, and data manipulation using the dplyr package.
-
Lifetime access.
-
30-Days Money Back Guarantee.
-
After completion certificate.
Course Duration: 6 小时
Course Duration: 6 hours
查看课程详情 here.
Check the course details here.
在本课程中,你将学习 −
In this course you will learn about −
-
Life Cycle of a Data Science Project.
-
Python libraries like Pandas and Numpy used extensively in Data Science.
-
Matplotlib and Seaborn for Data Visualization.
-
Data Preprocessing steps like Feature Encoding, Feature Scaling etc…
-
Machine Learning Fundamentals and different algorithms
-
Cloud Computing for Machine Learning
-
Deep Learning
-
5 projects like Diabetes Prediction, Stock Price Prediction etc…
Course Duration: 7 小时
Course Duration: 7 hours
查看课程详情 here.
Check the course details here.
Course Description
此 Pandas 课程全面介绍了此功能强大的工具,用于实施数据分析、数据清理、数据转换、不同数据格式、文本操作、正则表达式、数据 I/O、数据统计、数据可视化、时间序列等。
This Course of Pandas offers a complete view of this powerful tool for implementing data analysis, data cleaning, data transformation, different data formats, text manipulation, regular expressions, data I/O, data statistics, data visualization, time series and more.
本课程是一门实践课程,例子众多,因为学习最简单的方法就是通过实践!然后,我们将把我们学到所有知识整合到一个 Capstone 项目,利用著名的 IMDB 数据集来开发初步分析、清理、过滤、转换和可视化数据。
This course is a practical course with many examples because the easiest way to learn is by practicing! then we’ll integrate all the knowledge we have learned in a Capstone Project developing a preliminary analysis, cleaning, filtering, transforming, and visualizing data using the famous IMDB dataset.
Course Duration: 6 小时
Course Duration: 6 hours
查看课程详情 here.
Check the course details here.
-
This course is meant for beginners and intermediates who wants to expert on Python programming concepts and Data Science libraries for analysis, machine Learning models etc.
-
They can be students, professionals, Data Scientist, Business Analyst, Data Engineer, Machine Learning Engineer, Project Manager, Leads, business reports etc.
-
The course have been divided into 6 parts - Chapters, Quizzes, Classroom Hands-on Exercises, Homework Hands-on Exercises, Case Studies and Projects.
-
Practice and Hands-on concepts through Classroom, Homework Assignments, Case Studies and Projects
-
This Course is ideal for anyone who is starting their Data Science Journey and building ML models and Analytics in future.
-
This course covers all the important Python Fundamentals and Data Science Concepts requires to succeed in Academics and Corporate Industry.
-
Opportunity to Apply Data Science Concepts in 3 Real World Case Studies and 2 Real World Projects.
-
The 3 Case Studies are on Loan Risk Analysis, Churn Prediction and Customer Segmentation.
-
The 2 Projects are on Titanic Dataset and NYC Taxi Trip Duration.
Course Duration: 8.5 小时
Course Duration: 8.5 hours
查看课程详情 here.
Check the course details here.
Course Description
学生们将获得关于统计学基础的知识
Students will gain knowledge about the basics of statistics
他们将对不同类型数据有清晰的理解,包括对理解数据分析非常重要的示例
They will have a clear understanding of different types of data with examples which is very important to understand data analysis
学生们将能分析、解释和解读数据
Students will be able to analyze, explain and interpret the data
他们将通过学习皮尔森相关系数、散点图以及变量之间的线性回归分析来了解关系和依赖性,并且将能够了解如何进行预测
They will understand the relationship and dependency by learning Pearson’s correlation coefficient, scatter diagram, and linear regression analysis between the variables and will be able to know to make the prediction
学生们将了解不同的数据分析方法,例如集中趋势的测量(平均值、中值、众数)、离散度的测量(方差、标准差、变异系数)、如何计算四分位数、偏度和箱线图
Students will understand the different methods of data analysis such as a measure of central tendency (mean, median, mode), a measure of dispersion (variance, standard deviation, coefficient of variation), how to calculate quartiles, skewness, and box plot
他们将能够在学习偏度和箱线图后清晰地理解数据形状,这是数据分析中的一个重要部分
They will have a clear understanding of the shape of data after learning skewness and box plot, which is an important part of data analysis
学生们将对概率有基本的理解,懂得如何利用最简单的示例来解释和理解贝叶斯定理
Students will have a basic understanding of probability and how to explain and understand Bayes theorem with the simplest example
Course Duration: 7 小时
Course Duration: 7 hours
查看课程详情 here.
Check the course details here.
Top Data Science ebooks
在此部分中,我们将讨论可在网上找到的一些关于数据科学的流行电子书。
In this section we will discuss some the popular ebooks for data science that are available on the internet.
Beginners Course on Data Science
在这本电子书中,你将找到关于开始学习数据科学以及熟练掌握其方法和工具所需了解的所有内容。了解数据科学以及它如何帮助预测在当今快节奏的世界中至关重要。本书的目的是提供对数据科学及其方法的高级概述。数据科学起源于统计学。然而,在此领域取得成功需要在编程、商业和统计学方面具备专业知识。最佳的学习方式是深入熟悉每个学科。
In this book, you’ll find everything you need to know to get started with data science and become proficient with its methods and tools. Understanding data science and how it aids prediction is crucial in today’s fast-paced world. The purpose of this book is to provide a high-level overview of data science and its methodology.Data Science has its origins in statistics. However, expertise in programming, business, and statistics is necessary for success in this arena. The best way to learn is to familiarize yourself with each subject at length.
在数据集中发现趋势和见解是一项古老的艺术。古埃及人使用人口普查信息来更好地征税。尼罗河洪水预测也是使用数据分析做出的。在数据集中找到模式或令人兴奋的见解片段需要回顾之前的数据。该公司将能够利用这些信息做出更好的选择。数据科学家的需求不再隐蔽;如果你喜欢分析数字信息,那么这就是你的领域。数据科学是一个不断发展的领域,如果你决定接受这方面的教育,那么你应该抓住机会,在它出现时立即开始从事这项工作。
Finding trends and insights within a dataset is an age-old art. The ancient Egyptians used census information to better levy taxes. Nile flood predictions were also made using data analysis. Finding a pattern or exciting nugget of information in a dataset requires looking back at the data that came before it. The company will be able to use this information to make better choices.The need for data scientists is no longer hidden; if you enjoy analyzing numerical information, this is your field. Data Science is a growing field, and if you decide to pursue an education in it, you should jump at the chance to work in it as soon as it presents itself.
查看电子书 here.
Check the ebook here.
Building Data Science Solutions With Anaconda
在本书中,您将学习如何将 Anaconda 用作轻松按钮,让您全面了解 conda 等工具的功能,其中包括如何指定新渠道以提取所需的任何软件包,以及发现可以使用的新的开源工具。您还将清晰地了解如何评估要训练的模型,以及识别它们何时因漂移而变得不可用。最后,您将了解可用于解释模型工作原理的强大而简单的技术。
In this book, you’ll learn how using Anaconda as the easy button, can give you a complete view of the capabilities of tools such as conda, which includes how to specify new channels to pull in any package you want as well as discovering new open source tools at your disposal. You’ll also get a clear picture of how to evaluate which model to train and identify when they have become unusable due to drift. Finally, you’ll learn about the powerful yet simple techniques that you can use to explain how your model works.
在本课程结束时,您将自信地使用 conda 和 Anaconda Navigator 来管理依赖关系,并全面了解端到端数据科学工作流。
By the end of this book, you’ll feel confident using conda and Anaconda Navigator to manage dependencies and gain a thorough understanding of the end-to-end data science workflow.
查看电子书 here.
Check the ebook here.
Practical Data Science With Python
本书首先概述了基本的 Python 技能,然后介绍基础数据科学技术,接下来是执行这些技术所需的 Python 代码的详尽说明。您将通过学习示例来理解代码。代码已被分解为小块(一次几行或一个函数),以便进行深入讨论。
The book starts with an overview of basic Python skills and then introduces foundational data science techniques, followed by a thorough explanation of the Python code needed to execute the techniques. You’ll understand the code by working through the examples. The code has been broken down into small chunks (a few lines or a function at a time) to enable thorough discussion.
随着您的进步,您将学习如何执行数据分析,同时探索关键数据科学 Python 包的功能,包括 pandas、SciPy 和 scikit-learn。最后,本书涵盖了数据科学中的道德和隐私问题,并提出了提高数据科学技能的资源,以及随时了解新的数据科学发展的途径。
As you progress, you will learn how to perform data analysis while exploring the functionalities of key data science Python packages, including pandas, SciPy, and scikit-learn. Finally, the book covers ethics and privacy concerns in data science and suggests resources for improving data science skills, as well as ways to stay up to date on new data science developments.
在本课程结束时,您应该能够轻松地使用 Python 进行基本的数据科学项目,并具备在任何数据源上执行数据科学流程的技能。
By the end of the book, you should be able to comfortably use Python for basic data science projects and should have the skills to execute the data science process on any data source.
查看电子书 here.
Check the ebook here.
Cleaning Data for Effective Data Science
本书深入探讨了数据导入、异常检测、值填补和特征工程所需工具和技术的实际应用。它还提供每一章末尾的长篇练习,以练习所获得的技能。
The book dives into the practical application of tools and techniques needed for data ingestion, anomaly detection, value imputation, and feature engineering. It also offers long-form exercises at the end of each chapter to practice the skills acquired.
您将首先查看 JSON、CSV、SQL RDBMS、HDF5、NoSQL 数据库、图像格式文件和二进制序列化数据结构等数据格式的数据导入。此外,本书提供了大量示例数据集和数据文件,可供下载和独立探索。
You will begin by looking at data ingestion of data formats such as JSON, CSV, SQL RDBMSes, HDF5, NoSQL databases, files in image formats, and binary serialized data structures. Further, the book provides numerous example data sets and data files, which are available for download and independent exploration.
从格式开始,您将填补缺失值、检测不可靠的数据和统计异常,并生成成功数据分析和可视化目标所需的合成特征。
Moving on from formats, you will impute missing values, detect unreliable data and statistical anomalies, and generate synthetic features that are necessary for successful data analysis and visualization goals.
在本课程结束时,您将对执行现实世界数据科学和机器学习任务所需的数据清理流程有一个坚定的理解。
By the end of this book, you will have acquired a firm understanding of the data cleaning process necessary to perform real-world data science and machine learning tasks.
查看电子书 here.
Check the ebook here.
Essentials of Data Science And Analytics
本书结合了数据科学和分析的关键概念,帮助您对这些领域有实际的了解。本书的四个不同的部分被分成章节,解释了数据科学的核心。鉴于对数据科学的兴趣激增,这本书是及时且内容丰富的。
This book combines the key concepts of data science and analytics to help you gain a practical understanding of these fields. The four different sections of the book are divided into chapters that explain the core of data science. Given the booming interest in data science, this book is timely and informative.
查看电子书 here.
Check the ebook here.
Data Science - Interview Questions
以下是面试中一些最常问的问题。
Below are some most commonly asked questions in the interviews.
Q1. What is data science and how is it different from other data-related fields?
数据科学是一个研究领域,使用计算和统计方法从数据中获取知识和见解。它利用数学、统计、计算机科学和特定领域知识来分析大数据集,从数据中发现趋势和模式,并对未来进行预测。
Data Science is the domain of study that uses computational and statistical methods to get knowledge and insights from data. It utilizes techniques from mathematics, statistics, computer science and domain-specific knowledge to analyse large datasets, find trends and patterns from the data and make predictions for the future.
数据科学与其他数据相关领域不同,因为它不仅仅是收集和组织数据。数据科学过程包括分析、建模、可视化和评估数据集。数据科学使用机器学习算法、数据可视化工具和统计模型来分析数据,做出预测,并在数据中找到模式和趋势。
Data Science is different from other data related fields because it is not only about collecting and organising data. The data science process consists of analysing, modelling, visualizing and evaluating the data set. Data Science uses tools like machine learning algorithms, data visualisation tools and statistical models to analyse data, make predictions and find patterns and trends in the data.
其他数据相关领域,例如机器学习、数据工程和数据分析,更专注于特定事物,例如机器学习工程师的目标是设计和创建能够从数据中学习并做出预测的算法,数据工程的目标是设计和管理数据管道、基础设施和数据库。数据分析完全是关于探索和分析数据以找到模式和趋势。而数据科学则对模型进行建模、探索、收集、可视化、预测和部署。
Other data related fields such as machine learning, data engineering and data analytics are more focused on a particular thing like the goal of a machine leaning engineer is to design and create algorithms that are capable of learning from the data and making predictions, the goal of data engineering is to design and manage data pipelines, infrastructures and databases. Data analysis is all about exploring and analysing data to find patterns and trends. Whereas data science does modelling, exploring, collecting, visualizing, predicting, and deploying the model.
总体而言,数据科学是一种更全面的数据分析方式,因为它包含从准备数据到做出预测的整个过程。处理数据的其他领域有更具体的专业领域。
Overall, data science is a more comprehensive way to analyse data because it includes the whole process, from preparing the data to making predictions. Other fields that deal with data have more specific areas of expertise.
Q2. What is the data science process and what are the key steps involved?
数据科学流程也称为数据科学生命周期,是一种解决数据问题的系统方法,它展示了为开发、交付和维护数据科学项目而采取的步骤。
A data science process also known as data science lifecycle is a systematic approach to find a solution for a data problem which shows the steps that are taken to develop, deliver, and maintain a data science project.
标准数据科学生命周期方法包括使用机器学习算法和统计程序,从而产生更准确的预测模型。数据提取、准备、清理、建模、评估等是一些最重要的数据科学阶段。数据科学流程涉及的关键步骤有:
A standard data science lifecycle approach comprises the use of machine learning algorithms and statistical procedures that result in more accurate prediction models. Data extraction, preparation, cleaning, modelling, assessment, etc., are some of the most important data science stages. Key steps involved in data science process are −
Identifying Problem and Understanding the Business
数据科学生命周期与任何其他业务生命周期一样,都始于“为什么”。数据科学流程中最重要的部分之一是找出问题所在。这有助于找到明确的目标,所有其他步骤都可以围绕该目标进行。简而言之,了解业务目标非常重要,因为它将确定分析的最终目标。
The data science lifecycle starts with "why?" just like any other business lifecycle. One of the most important parts of the data science process is figuring out what the problems are. This helps to find a clear goal around which all the other steps can be made. In short, it’s important to know the business goal as earliest because it will determine what the end goal of the analysis will be.
Data Collection
数据科学生命周期的下一步是数据收集,这意味着从适当且可靠的来源获取原始数据。收集的数据可以是有序的,也可以是无序的。数据可以从网站日志、社交媒体数据、在线数据存储库中收集,甚至可以使用 API、网络抓取或可能存在于 Excel 或其他来源中的数据从在线来源流式传输数据。
The next step in the data science lifecycle is data collection, which means getting raw data from the appropriate and reliable source. The data that is collected can be either organized or unorganized. The data could be collected from website logs, social media data, online data repositories, and even data that is streamed from online sources using APIs, web scraping, or data that could be in Excel or any other source.
Data Processing
从可靠来源收集高质量数据后,下一步是处理它。数据处理的目的是确保在进入下一阶段之前已经解决了所获取数据的任何问题。如果没有此步骤,我们可能会产生错误或不准确的发现。
After collecting high-quality data from reliable sources, next step is to process it. The purpose of data processing is to ensure that any problems with the acquired data have been resolved before proceeding to the next phase. Without this step, we may produce mistakes or inaccurate findings.
Data Analysis
数据分析 探索性数据分析 (EDA) 是一组用于分析数据的可视化技术。采用此方法,我们可能会获取有关数据统计摘要的具体详细信息。此外,我们将能够处理重复数字、离群值,并在集合内找出趋势或模式。
Data analysis Exploratory Data Analysis (EDA) is a set of visual techniques for analysing data. With this method, we may get specific details on the statistical summary of the data. Also, we will be able to deal with duplicate numbers, outliers, and identify trends or patterns within the collection.
Data Visualization
数据可视化是在图表上展示信息和数据的过程。利用图表、图形和地图之类的直观元素,数据可视化工具可以轻松了解数据中的趋势、异常值和模式。对于员工或企业所有者而言,这也是一种向不精通技术的人员展示数据而无需让他们感到困惑的出色方法。
Data visualisation is the process of demonstrating information and data on a graph. Data visualisation tools make it easy to understand trends, outliers, and patterns in data by using visual elements like charts, graphs, and maps. It’s also a great way for employees or business owners to present data to people who aren’t tech-savvy without making them confused.
Data Modelling
数据建模是数据科学中最重要的方面之一,有时被称为数据分析的核心。模型的目标输出应源自已准备好的经过分析的数据。
Data Modelling is one of the most important aspects of data science and is sometimes referred to as the core of data analysis. The intended output of a model should be derived from prepared and analysed data.
在这个阶段,我们将为生产相关任务开发数据集以对模型进行训练和测试。它还涉及选择正确的模式类型并确定问题是否涉及分类、回归或聚类。在分析模型类型后,我们必须选择适当的实现算法。必须仔细执行,因为从提供的数据中提取相关见解至关重要。
At this phase, we develop datasets for training and testing the model for production-related tasks. It also involves selecting the correct mode type and determining if the problem involves classification, regression, or clustering. After analysing the model type, we must choose the appropriate implementation algorithms. It must be performed with care, as it is crucial to extract the relevant insights from the provided data.
Model Deployment
模型部署包含为将模型部署到市场消费者或另一系统而建立的交付方法。机器学习模型也正在设备上实施,并且越来越受欢迎。根据项目的复杂性,此阶段的范围可能从 Tableau 仪表盘上的基本模型输出到拥有数百万用户的复杂的基于云的部署。
Model deployment contains the establishment of a delivery method necessary to deploy the model to market consumers or to another system. Machine learning models are also being implemented on devices and gaining acceptance and appeal. Depending on the complexity of the project, this stage might range from a basic model output on a Tableau Dashboard to a complicated cloud-based deployment with millions of users.
Q3. What is the difference between supervised and unsupervised learning?
监督学习 - 监督学习是一种机器学习和人工智能。它也被称为“监督机器学习”。其定义为使用标记数据集来培训算法如何正确分类数据或预测结果。在将数据放入模型时,模型的权重会发生变化,直到模型正确拟合为止。这是交叉验证过程的一部分。监督学习可以帮助组织找到解决各种实际问题的规模化解决方案,例如在 Gmail 中将垃圾邮件分类到与收件箱分开的文件夹中,我们在 Gmail 中有一个垃圾邮件文件夹。
*Supervised Learning * − Supervised learning is a type of machine learning and artificial intelligence. It is also called "supervised machine learning." It is defined by the fact that it uses labelled datasets to train algorithms how to correctly classify data or predict outcomes. As data is put into the model, its weights are changed until the model fits correctly. This is part of the cross validation process. Supervised learning helps organisations find large-scale solutions to a wide range of real-world problems, like classifying spam in a separate folder from your inbox like in Gmail we have a spam folder.
Supervised Learning Algorithms - 朴素贝叶斯、线性回归、逻辑回归。
Supervised Learning Algorithms − Naive Bayes, Linear regression, Logistic regression.
Unsupervised learning - 无监督学习也称为无监督机器学习,使用机器学习算法查看未标记数据集并将其分组在一起。这些程序查找隐藏的模式或数据组。其查找信息中的相似性和差异的能力使其非常适合探索性数据分析、交叉销售策略、客户细分和图像识别。
Unsupervised learning − Unsupervised learning, also called unsupervised machine learning, uses machine learning algorithms to look at unlabelled datasets and group them together. These programmes find hidden patterns or groups of data. Its ability to find similarities and differences in information makes it perfect for exploratory data analysis, cross-selling strategies, customer segmentation, and image recognition.
Unsupervised Learning Algorithms - K 均值聚类
Unsupervised Learning Algorithms − K-means clustering
Q4. What is regularization and how does it help to avoid overfitting?
正则化是一种向模型添加信息的方法,以防止模型过度拟合。它是一种回归,旨在尽可能使系数的估计值接近零以缩小模型。在这种情况下,减少模型容量意味着去除额外的权重。
Regularization is a method that adds information to a model to stop it from becoming overfitted. It is a type of regression that tries to get the estimates of the coefficients as close to zero as possible to make the model smaller. In this case, taking away extra weights is what it means to reduce a model’s capacity.
正则化从所选特征中去除任何额外权重,并重新分配权重,使其全部相同。这意味着正则化增加了学习既灵活又有很多活动部件的模型的难度。能够拟合尽可能多数据点的模型就是灵活的模型。
Regularization takes away any extra weights from the chosen features and redistributes the weights so that they are all the same. This means that regularisation makes it harder to learn a model that is both flexible and has a lot of moving parts. A model with a lot of flexibility is one that can fit as many data points as possible.
Q5. What is cross-validation and why is it important in machine learning?
交叉验证是一种通过在可用输入数据的不同子集上对其进行训练并针对另一个子集对其进行测试来测试机器学习模型的技术。我们可以使用交叉验证来检测过度拟合,即无法概括模式。
Cross-validation is a technique to test ML models by training them on different subsets of the available input data and then testing them on the other subset. We can use cross-validation to detect overfitting, ie, failing to generalise a pattern.
对于交叉验证,我们可以使用 k 折交叉验证法。在 k 折交叉验证中,我们将初始数据分为 k 组(也称为折叠)。我们在所有子集减去一个子集(k-1)上训练机器学习模型,然后在未用于训练的子集上测试该模型。此过程执行 k 次,每次将不同的子集留作评估(不用于训练)。
For cross-validation, we can use the k-fold cross-validation method. In k-fold cross-validation, we divide the data you start with into k groups (also known as folds). We train an ML model on all but one (k-1) of the subsets, and then we test the model on the subset that wasn’t used for training. This process is done k times, and each time a different subset is set aside for evaluation (and not used for training).
Q6. What is the difference between classification and regression in machine learning?
回归和分类之间的主要区别在于,回归有助于预测连续量,而分类有助于预测离散类标签。两种机器学习算法的一些组件也相同。
The major difference between regression and classification is that regression helps predict a continuous quantity, while classification helps predict discrete class labels. Some components of the two kinds of machine learning algorithms are also the same.
回归算法可以对离散值(全整数)进行预测。
A regression algorithm can make a prediction about a discrete value, which is a whole number.
如果值采用类别标签概率的形式,那么分类算法可以预测此类数据。
If the value is in the form of a class label probability, a classification algorithm can predict this type of data.
Q7. What is clustering and what are some popular clustering algorithms?
聚类是一种基于数据的相似性或差异组织未标记数据的数据挖掘方法。聚类技术用于根据数据中的结构或模式将未分类的未处理数据项组织到组中。有许多类型的聚类算法,包括排他性的、重叠的、层次的和概率性的。
Clustering is a method for data mining that organises unlabelled data based on their similarities or differences. Clustering techniques are used to organise unclassified, unprocessed data items into groups according to structures or patterns in the data. There are many types of clustering algorithms, including exclusive, overlapping, hierarchical, and probabilistic.
K-means clustering 是聚类方法的一个流行示例,其中根据数据点与每个组质心的距离将数据点分配到 K 组中。最接近某个质心的数据点将被分组到同一类别中。较高的 K 值表示具有更高粒度的较小组,而较低的 K 值表示具有较低粒度的较大组。K 均值聚类的常见应用包括市场细分、文档聚类、图像细分和图像压缩。
K-means clustering is a popular example of a clustering approach in which data points are allocated to K groups based on their distance from each group’s centroid. The data points closest to a certain centroid will be grouped into the same category. A higher K number indicates smaller groups with more granularity, while a lower K value indicates bigger groupings with less granularity. Common applications of K-means clustering include market segmentation, document clustering, picture segmentation, and image compression.
Q8. What is gradient descent and how does it work in machine learning?
梯度下降是一种优化算法,通常用于训练神经网络和机器学习模型。训练数据帮助这些模型随着时间的推移进行学习,而梯度下降中的成本函数作为一个晴雨表来衡量每次参数更新的准确率。该模型将继续改变其参数以尽可能减小误差,直到函数接近或等于 0。一旦机器学习模型调整到尽可能准确,则可以使用其以强大的方式用于人工智能 (AI) 和计算机科学。
Gradient descent is an optimisation algorithm that is often used to train neural networks and machine learning models. Training data helps these models learn over time, and the cost function in gradient descent acts as a barometer to measure how accurate it is with each iteration of parameter updates. The model will keep changing its parameters to make the error as small as possible until the function is close to or equal to 0. Once machine learning models are tuned to be as accurate as possible, they can be used in artificial intelligence (AI) and computer science in powerful ways.
Q9. What is A/B testing and how can it be used in data science?
A/B 测试是一种常见的随机对照实验。这是一种在受控环境中确定两个变量版本中哪一个执行得更好的方法。A/B 测试是数据科学和整个技术行业中最重要的概念之一,因为它是就任何假设得出结论的最有效方法之一。理解什么是 A/B 测试以及它通常如何工作至关重要。A/B 测试是评估商品的常用方法,并且在数据分析领域势头正盛。在测试增量更改(例如 UX 修改、新功能、排名和页面加载速度)时,A/B 测试更有效。
A/B testing is a common form of randomised controlled experiment. It is a method for determining which of two versions of a variable performs better in a controlled setting. A/B testing is one of the most important concepts in data science and the technology industry as a whole since it is one of the most efficient approaches for drawing conclusions regarding any hypothesis. It is essential that you comprehend what A/B testing is and how it normally works. A/B testing is a common method for evaluating goods and is gaining momentum in the area of data analytics. A/B testing is more effective when testing incremental changes such as UX modifications, new features, ranking, and page load speeds.
Q10. Can you explain overfitting and underfitting, and how to mitigate them?
过度拟合是在函数过度拟合到有限数量的数据点时出现的建模错误。它是训练点过多和复杂性过高的模型的结果。
Overfitting is a modelling error that arises when a function is overfit to a restricted number of data points. It is the outcome of a model with an excessive amount of training points and excessive complexity.
欠拟合是一种建模错误,当一个函数与数据点不完全匹配时就会出现。这是简单的模型与训练点不足的结果。
Underfitting is a modelling error that arises when a function does not properly match the data points. That is the outcome of a simple model with inadequate training points.
机器学习研究者可以通过多种方式避免过拟合。这些方式包括:交叉验证、正则化、剪枝、丢弃。
There are a number of ways that researchers in machine learning can avoid overfitting. These include: Cross-validation, Regularization, Pruning, Dropout.
机器学习研究者可以通过多种方式避免欠拟合。这些方式包括:
There are a number of ways that researchers in machine learning can avoid underfitting. These include −
-
Get more training data.
-
Add more parameters or increase size of the parameters.
-
Make the model more complex.
-
Adding more time to training until the cost function is at its lowest.
使用这些方法,你应能使模型变得更好,并修复任何过拟合或欠拟合问题。
With these methods, you should be able to make your models better and fix any problems with overfitting or underfitting.