Python Data Persistence 简明教程
Python Data Persistence - Introduction
Overview of Python - Data Persistence
在使用任何软件应用程序的过程中,用户都会提供一些要处理的数据。数据可能是使用标准输入设备(键盘)或其他设备(如磁盘文件、扫描仪、照相机、网线、WiFi 连接等)输入的。
During the course of using any software application, user provides some data to be processed. The data may be input, using a standard input device (keyboard) or other devices such as disk file, scanner, camera, network cable, WiFi connection, etc.
接收到的数据存储在计算机的主存储器(RAM)中,采用各种数据结构(如变量和对象)的形式,直到应用程序正在运行。此后,来自 RAM 的内存内容将被擦除。
Data so received, is stored in computer’s main memory (RAM) in the form of various data structures such as, variables and objects until the application is running. Thereafter, memory contents from RAM are erased.
然而,通常情况下,人们希望变量和/或对象的值以某种方式存储,以便可以在需要时检索该值,而不是再次输入相同的数据。
However, more often than not, it is desired that the values of variables and/or objects be stored in such a manner, that it can be retrieved whenever required, instead of again inputting the same data.
“持久性”一词意为“在其成因被移除之后仍在持续存在的效应”。数据持久性一词表示它在应用程序结束后仍然存在。因此,存储在非易失性存储介质(如磁盘文件)中的数据是一种持久性数据存储。
The word ‘persistence’ means "the continuance of an effect after its cause is removed". The term data persistence means it continues to exist even after the application has ended. Thus, data stored in a non-volatile storage medium such as, a disk file is a persistent data storage.
在本教程中,我们将探讨各种内置和第三方 Python 模块,以将数据存储和检索到/从各种格式,如文本文件、CSV、JSON 和 XML 文件以及关系数据库和非关系数据库。
In this tutorial, we will explore various built-in and third party Python modules to store and retrieve data to/from various formats such as text file, CSV, JSON and XML files as well as relational and non-relational databases.
使用 Python 的内置文件对象,可以将字符串数据写入磁盘文件并从中读取数据。Python 的标准库提供了模块,以存储和检索序列化数据,这些数据位于各种数据结构中,如 JSON 和 XML。
Using Python’s built-in File object, it is possible to write string data to a disk file and read from it. Python’s standard library, provides modules to store and retrieve serialized data in various data structures such as JSON and XML.
Python 的 DB-API 提供了一种与关系数据库交互的标准方法。其他第三方 Python 软件包提供了与 NOSQL 数据库(如 MongoDB 和 Cassandra)的接口功能。
Python’s DB-API provides a standard way of interacting with relational databases. Other third party Python packages, present interfacing functionality with NOSQL databases such as MongoDB and Cassandra.
本教程还介绍 ZODB 数据库,这是 Python 对象的持久性 API。Microsoft Excel 格式是一种非常流行的数据文件格式。在本教程中,我们将学习如何通过 Python 处理 .xlsx 文件。
This tutorial also introduces, ZODB database which is a persistence API for Python objects. Microsoft Excel format is a very popular data file format. In this tutorial, we will learn how to handle .xlsx file through Python.
Python Data Persistence - File API
Python 使用内置 input() 和 print() 函数来执行标准输入/输出操作。input() 函数从标准输入流设备(即键盘)读取字节。
Python uses built-in input() and print() functions to perform standard input/output operations. The input() function reads bytes from a standard input stream device, i.e. keyboard.
另一方面, print() 函数将数据发送到标准输出流设备(即显示器)。Python 程序通过 sys 模块中定义的标准流对象 stdin 和 stdout 与这些 IO 设备进行交互。
The print() function on the other hand, sends the data towards standard output stream device i.e. the display monitor. Python program interacts with these IO devices through standard stream objects stdin and stdout defined in sys module.
input() 函数实际上是 sys.stdin 对象的 readline() 方法的包装函数。接收所有来自输入流中的击键操作,直至按下「回车」键。
The input() function is actually a wrapper around readline() method of sys.stdin object. All keystrokes from the input stream are received till ‘Enter’ key is pressed.
>>> import sys
>>> x=sys.stdin.readline()
Welcome to TutorialsPoint
>>> x
'Welcome to TutorialsPoint\n'请注意, readline() 函数留下一个临时的「\n」字符。这里还有一个 read() 函数,它将从标准输入流中读取数据,直到该过程被 Ctrl+D 字符终止。
Note that, readline() function leave a trailing ‘\n’ character. There is also a read() method which reads data from standard input stream till it is terminated by Ctrl+D character.
>>> x=sys.stdin.read()
Hello
Welcome to TutorialsPoint
>>> x
'Hello\nWelcome to TutorialsPoint\n'类似地, print() 是一个编写 stdout 对象的 write() 方法的简便函数。
Similarly, print() is a convenience function emulating write() method of stdout object.
>>> x='Welcome to TutorialsPoint\n'
>>> sys.stdout.write(x)
Welcome to TutorialsPoint
26如同 stdin 和 stdout 预定义的流对象,Python 程序可以从磁盘文件或网络套接字读取数据并向其发送数据。它们也是流。任何具有 read() 方法的对象都是输入流。具有 write() 方法的任何对象都是输出流。通过获取对流对象的引用,借助内置的 open() 函数,可以与流建立通信。
Just as stdin and stdout predefined stream objects, a Python program can read data from and send data to a disk file or a network socket. They are also streams. Any object that has read() method is an input stream. Any object that has write() method is an output stream. The communication with the stream is established by obtaining reference to the stream object with built-in open() function.
open() function
这个内置函数使用以下参数:
This built-in function uses following arguments −
f=open(name, mode, buffering)name 参数是磁盘文件或字节字符串的名称,mode 是可选项,指定要执行的操作类型(读取、写入、追加等)的单字符字符串,buffering 参数为 0、1 或 -1,表示缓冲为关闭、开启或系统默认。
The name parameter, is name of disk file or byte string, mode is optional one-character string to specify the type of operation to be performed (read, write, append etc.) and buffering parameter is either 0, 1 or -1 indicating buffering is off, on or system default.
文件打开模式中根据下表进行枚举。默认模式为‘r’
File opening mode is enumerated as per table below. Default mode is ‘r’
Sr.No |
Parameters & Description |
1 |
R Open for reading (default) |
2 |
W Open for writing, truncating the file first |
3 |
X Create a new file and open it for writing |
4 |
A Open for writing, appending to the end of the file if it exists |
5 |
B Binary mode |
6 |
T Text mode (default) |
7 |
+ Open a disk file for updating (reading and writing) |
要将数据保存到文件,必须使用“w”模式打开它。
In order to save data to file it must be opened with ‘w’ mode.
f=open('test.txt','w')此文件对象充当输出流,并有权访问 write() 方法。write() 方法将字符串发送到该对象,并存储在它的底层文件中。
This file object acts as an output stream, and has access to write() method. The write() method sends a string to this object, and is stored in the file underlying it.
string="Hello TutorialsPoint\n"
f.write(string)关闭流非常重要,以确保缓冲区中剩余的任何数据都完全传输到它。
It is important to close the stream, to ensure that any data remaining in buffer is completely transferred to it.
file.close()尝试使用任何测试编辑器(如记事本)打开“test.txt”,以确认文件创建成功。
Try and open ‘test.txt’ using any test editor (such as notepad) to confirm successful creation of file.
要以编程方式读取“test.txt”的内容,必须以“r”模式打开它。
To read contents of ‘test.txt’ programmatically, it must be opened in ‘r’ mode.
f=open('test.txt','r')此对象表现为输入流。Python 可使用 read() 方法从流中获取数据。
This object behaves as an input stream. Python can fetch data from the stream using read() method.
string=f.read()
print (string)文件内容在 Python 控制台中显示。文件对象还支持 readline() 方法,该方法能够读取字符串直到遇到 EOF 字符。
Contents of the file are displayed on Python console. The File object also supports readline() method which is able to read string till it encounters EOF character.
然而,如果以“w”模式打开相同的文件在其中存储附加文本,则前面的内容将被删除。每当以写权限打开文件时,将视其为一个新文件。要向现有文件添加数据,可使用“a”作为追加模式。
However, if same file is opened in ‘w’ mode to store additional text in it, earlier contents are erased. Whenever, a file is opened with write permission, it is treated as if it is a new file. To add data to an existing file, use ‘a’ for append mode.
f=open('test.txt','a')
f.write('Python Tutorials\n')该文件现在具有前置字符串和新增加的字符串。该文件对象还支持 ` writelines() ` 方法,用于将列表对象中的每个字符串写入到该文件中。
The file now, has earlier as well as newly added string. The file object also supports writelines() method to write each string in a list object to the file.
f=open('test.txt','a')
lines=['Java Tutorials\n', 'DBMS tutorials\n', 'Mobile development tutorials\n']
f.writelines(lines)
f.close()Example
` readlines() ` 方法返回字符串列表,其中每个字符串表示该文件中的一个行。也可以逐行读取该文件,直到达到文件结尾。
The readlines() method returns a list of strings, each representing a line in the file. It is also possible to read the file line by line until end of file is reached.
f=open('test.txt','r')
while True:
line=f.readline()
if line=='' : break
print (line, end='')
f.close()Binary mode
默认情况下,在文件对象上执行的读/写操作针对文本字符串数据执行。如果我们想处理其他不同类型(例如媒体(mp3)、可执行文件(exe)、图片(jpg)等)的文件,则需要在读/写模式中添加“b”前缀。
By default, read/write operation on a file object are performed on text string data. If we want to handle files of different other types such as media (mp3), executables (exe), pictures (jpg) etc., we need to add ‘b’ prefix to read/write mode.
下面的语句将把一个字符串转换为字节并写入到一个文件中。
Following statement will convert a string to bytes and write in a file.
f=open('test.bin', 'wb')
data=b"Hello World"
f.write(data)
f.close()还可以使用 encode() 函数将文本字符串转换为字节。
Conversion of text string to bytes is also possible using encode() function.
data="Hello World".encode('utf-8')我们需要使用 ` ‘rb’ ` 模式才能读取二进制文件。read() 方法的返回值在打印之前首先解码。
We need to use ‘rb’ mode to read binary file. Returned value of read() method is first decoded before printing.
f=open('test.bin', 'rb')
data=f.read()
print (data.decode(encoding='utf-8'))为了在二进制文件中写入整数数据,应该通过 ` to_bytes() ` 方法将整数对象转换为字节。
In order to write integer data in a binary file, the integer object should be converted to bytes by to_bytes() method.
n=25
n.to_bytes(8,'big')
f=open('test.bin', 'wb')
data=n.to_bytes(8,'big')
f.write(data)为了从二进制文件回读,需通过 from_bytes() 函数将 read() 函数的输出转换为整数。
To read back from a binary file, convert output of read() function to integer by from_bytes() function.
f=open('test.bin', 'rb')
data=f.read()
n=int.from_bytes(data, 'big')
print (n)对于浮点数据,我们需要使用 Python 的标准库中的 struct 模块。
For floating point data, we need to use struct module from Python’s standard library.
import struct
x=23.50
data=struct.pack('f',x)
f=open('test.bin', 'wb')
f.write(data)从 read() 函数解包字符串,以便从二进制文件检索浮点数数据。
Unpacking the string from read() function, to retrieve the float data from binary file.
f=open('test.bin', 'rb')
data=f.read()
x=struct.unpack('f', data)
print (x)Simultaneous read/write
当某一文件打开进行写入(使用“w”或“a”)时,无法从该文件中读取,反之亦然。执行此操作将引发 UnSupportedOperation 错误。我们需要在执行其他操作之前关闭该文件。
When a file is opened for writing (with ‘w’ or ‘a’), it is not possible, to read from it and vice versa. Doing so throws UnSupportedOperation error. We need to close the file before doing other operation.
为了同时执行这两个操作,我们必须在模式参数中添加 ‘’ 字符。因此,“w”或“r+”模式允许在不关闭文件的情况下使用 write() 和 read() 方法。File 对象还支持 seek() 函数,用于将流倒回到任何所需的字节位置。
In order to perform both operations simultaneously, we have to add ‘’ character in the mode parameter. Hence, ‘w’ or ‘r+’ mode enables using write() as well as read() methods without closing a file. The File object also supports seek() function to rewind the stream to any desired byte position.
f=open('test.txt','w+')
f.write('Hello world')
f.seek(0,0)
data=f.read()
print (data)
f.close()下表总结了可用于类文件对象的全部方法。
Following table summarizes all the methods available to a file like object.
Sr.No |
Method & Description |
1 |
close() Closes the file. A closed file cannot be read or written any more. |
2 |
flush() Flush the internal buffer. |
3 |
fileno() Returns the integer file descriptor. |
4 |
next() Returns the next line from the file each time it is being called. Use next() iterator in Python 3. |
5 |
read([size]) Reads at most size bytes from the file (less if the read hits EOF before obtaining size bytes). |
6 |
readline([size]) Reads one entire line from the file. A trailing newline character is kept in the string. |
7 |
readlines([sizehint]) Reads until EOF using readline() and returns a list containing the lines. |
8 |
seek(offset[, whence]) Sets the file’s current position. 0-begin 1-current 2-end. |
9 |
seek(offset[, whence]) Sets the file’s current position. 0-begin 1-current 2-end. |
10 |
tell() Returns the file’s current position |
11 |
truncate([size]) Truncates the file’s size. |
12 |
write(str) Writes a string to the file. There is no return value. |
File Handling with os Module
除了 open() 函数返回的文件对象,还可以使用 Python 内置库的 os 模块执行文件 IO 操作,该模块提供了实用的操作系统相关函数。这些函数对文件执行低级别的读/写操作。
In addition to File object returned by open() function, file IO operations can also be performed using Python’s built-in library has os module that provides useful operating system dependent functions. These functions perform low level read/write operations on file.
os 模块中的 open() 函数类似于内置 open()。但是,它不返回文件对象,而是返回文件描述符,它是一个与打开的文件相对应的唯一整数。文件描述符的值 0、1 和 2 分别表示标准输入、标准输出和标准错误流。其他文件将从 2 开始获得递增的文件描述符。
The open() function from os module is similar to the built-in open(). However, it doesn’t return a file object but a file descriptor, a unique integer corresponding to file opened. File descriptor’s values 0, 1 and 2 represent stdin, stdout, and stderr streams. Other files will be given incremental file descriptor from 2 onwards.
与 open() 内置函数的情况类似, os.open() 函数也需要指定文件访问模式。下表列出 os 模块中定义的各种模式。
As in case of open() built-in function, os.open() function also needs to specify file access mode. Following table lists various modes as defined in os module.
Sr.No. |
Os Module & Description |
1 |
os.O_RDONLY Open for reading only |
2 |
os.O_WRONLY Open for writing only |
3 |
os.O_RDWR Open for reading and writing |
4 |
os.O_NONBLOCK Do not block on open |
5 |
os.O_APPEND Append on each write |
6 |
os.O_CREAT Create file if it does not exist |
7 |
os.O_TRUNC Truncate size to 0 |
8 |
os.O_EXCL Error if create and file exists |
若要打开一个新文件以写入数据,请通过插入管道 (|) 运算符指定 O_WRONLY 和 O_CREAT 模式。os.open() 函数返回文件描述符。
To open a new file for writing data in it, specify O_WRONLY as well as O_CREAT modes by inserting pipe (|) operator. The os.open() function returns a file descriptor.
f=os.open("test.dat", os.O_WRONLY|os.O_CREAT)请注意,数据是以字节字符串的形式写入磁盘文件的。因此,通过使用 encode() 函数将普通字符串转换成字节字符串,如同之前一样。
Note that, data is written to disk file in the form of byte string. Hence, a normal string is converted to byte string by using encode() function as earlier.
data="Hello World".encode('utf-8')os 模块中的 write() 函数接受此字节字符串和文件描述符。
The write() function in os module accepts this byte string and file descriptor.
os.write(f,data)别忘了使用 close() 函数关闭文件。
Don’t forget to close the file using close() function.
os.close(f)要使用 os.read() 函数读取文件的内容,请使用以下语句:
To read contents of a file using os.read() function, use following statements:
f=os.open("test.dat", os.O_RDONLY)
data=os.read(f,20)
print (data.decode('utf-8'))请注意,os.read() 函数需要文件描述符和要读取的字节数(字节字符串的长度)。
Note that, the os.read() function needs file descriptor and number of bytes to be read (length of byte string).
如果要同时打开一个文件进行读/写操作,请使用 O_RDWR 模式。下表显示了 os 模块中与文件操作相关的重要函数。
If you want to open a file for simultaneous read/write operations, use O_RDWR mode. Following table shows important file operation related functions in os module.
Sr.No |
Functions & Description |
1 |
os.close(fd) Close the file descriptor. |
2 |
os.open(file, flags[, mode]) Open the file and set various flags according to flags and possibly its mode according to mode. |
3 |
os.read(fd, n) Read at most n bytes from file descriptor fd. Return a string containing the bytes read. If the end of the file referred to by fd has been reached, an empty string is returned. |
4 |
os.write(fd, str) Write the string str to file descriptor fd. Return the number of bytes actually written. |
Python Data Persistence - Object Serialization
Python 的 open() 内置函数返回的 Python 内置文件对象有一个重要的缺点。当使用“w”模式打开它时,write() 方法只接受字符串对象。
Python’s built-in file object returned by Python’s built-in open() function has one important shortcoming. When opened with 'w' mode, the write() method accepts only the string object.
这意味着,如果您有以任何非字符串形式表示的数据,无论是内置类(数字、字典、列表或元组)的对象还是其他用户定义的类,都不能直接写入文件。在写入之前,您需要将其转换为其字符串表示形式。
That means, if you have data represented in any non-string form, the object of either in built-in classes (numbers, dictionary, lists or tuples) or other user-defined classes, it cannot be written to file directly. Before writing, you need to convert it in its string representation.
numbers=[10,20,30,40]
file=open('numbers.txt','w')
file.write(str(numbers))
file.close()对于二进制文件, write() 方法的参数必须是字节对象。例如,整数列表由 bytearray() 函数转换为字节,然后写入文件。
For a binary file, argument to write() method must be a byte object. For example, the list of integers is converted to bytes by bytearray() function and then written to file.
numbers=[10,20,30,40]
data=bytearray(numbers)
file.write(data)
file.close()要从文件中读取相应数据类型的数据,需要进行反向转换。
To read back data from the file in the respective data type, reverse conversion needs to be done.
file=open('numbers.txt','rb')
data=file.read()
print (list(data))这种将对象转换为字符串或字节格式(反之亦然)的手动转换非常麻烦和繁琐。有可能将 Python 对象的状态直接以字节流形式存储到文件或内存流中,并将其检索到其原始状态。这个过程称为序列化和反序列化。
This type of manual conversion, of an object to string or byte format (and vice versa) is very cumbersome and tedious. It is possible to store the state of a Python object in the form of byte stream directly to a file, or memory stream and retrieve to its original state. This process is called serialization and de-serialization.
Python 的内置库包含用于序列化和反序列化过程的各种模块。
Python’s built in library contains various modules for serialization and deserialization process.
Sr.No. |
Name & Description |
1 |
pickle Python specific serialization library |
2 |
marshal Library used internally for serialization |
3 |
shelve Pythonic object persistence |
4 |
dbm library offering interface to Unix database |
5 |
csv library for storage and retrieval of Python data to CSV format |
6 |
json Library for serialization to universal JSON format |
Python Data Persistence - Pickle Module
Python 中序列化和反序列化的术语分别为 pickle 和 unpickle。Python 库中的 pickle 模块使用非常特定的 Python 数据格式。因此,非 Python 应用程序可能无法正确反序列化 pickle 数据。还建议不要从未经身份验证的源中反序列化数据。
Python’s terminology for serialization and deserialization is pickling and unpickling respectively. The pickle module in Python library, uses very Python specific data format. Hence, non-Python applications may not be able to deserialize pickled data properly. It is also advised not to unpickle data from un-authenticated source.
序列化的(pickle)数据可以存储在字节字符串或二进制文件中。此模块定义了 dumps() 和 loads() 函数,使用字节字符串对数据进行 pickle 和 unpickle 处理。对于基于文件的进程,该模块具有 dump() 和 load() 函数。
The serialized (pickled) data can be stored in a byte string or a binary file. This module defines dumps() and loads() functions to pickle and unpickle data using byte string. For file based process, the module has dump() and load() function.
Python 的 pickle 协议是用于构建和解构 Python 对象到/从二进制数据中的约定。目前,pickle 模块定义了如下列出的 5 个不同的协议−
Python’s pickle protocols are the conventions used in constructing and deconstructing Python objects to/from binary data. Currently, pickle module defines 5 different protocols as listed below −
Sr.No. |
Names & Description |
1 |
Protocol version 0 Original “human-readable” protocol backwards compatible with earlier versions. |
2 |
Protocol version 1 Old binary format also compatible with earlier versions of Python. |
3 |
Protocol version 2 Introduced in Python 2.3 provides efficient pickling of new-style classes. |
4 |
Protocol version 3 Added in Python 3.0. recommended when compatibility with other Python 3 versions is required. |
5 |
Protocol version 4 was added in Python 3.4. It adds support for very large objects |
Example
pickle 模块包含返回腌制数据的字符串表示形式的 dumps() 函数。
The pickle module consists of dumps() function that returns a string representation of pickled data.
from pickle import dump
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
dctstring=dumps(dct)
print (dctstring)Output
b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\x04\x00\x00\x00Raviq\x02X\x03\x00\x00\x00ageq\x03K\x17X\x06\x00\x00\x00Genderq\x04X\x01\x00\x00\x00Mq\x05X\x05\x00\x00\x00marksq\x06KKu.Example
使用 loads() 函数,可以解腌制该字符串并获取原始字典对象。
Use loads() function, to unpickle the string and obtain original dictionary object.
from pickle import load
dct=loads(dctstring)
print (dct)Output
{'name': 'Ravi', 'age': 23, 'Gender': 'M', 'marks': 75}还可以使用 dump() 函数将腌制对象持久存储在磁盘文件中,并使用 load() 函数检索。
Pickled objects can also be persistently stored in a disk file, using dump() function and retrieved using load() function.
import pickle
f=open("data.txt","wb")
dct={"name":"Ravi", "age":23, "Gender":"M","marks":75}
pickle.dump(dct,f)
f.close()
#to read
import pickle
f=open("data.txt","rb")
d=pickle.load(f)
print (d)
f.close()pickle 模块还提供了面向对象 API,用于以 Pickler 和 Unpickler 类形式表示的序列化机制。
The pickle module also provides, object oriented API for serialization mechanism in the form of Pickler and Unpickler classes.
如上所述,就像 Python 中的内置对象一样,用户定义类中的对象也可以持久序列化在磁盘文件中。在下列程序中,我们定义了一个 User 类,姓名和移动号码作为其实例属性。除 init () 构造函数外,该类还重写了 str () 方法,返回其对象的字符串表示形式。
As mentioned above, just as built-in objects in Python, objects of user defined classes can also be persistently serialized in disk file. In following program, we define a User class with name and mobile number as its instance attributes. In addition to the init() constructor, the class overrides str() method that returns a string representation of its object.
class User:
def __init__(self,name, mob):
self.name=name
self.mobile=mob
def __str__(self):
return ('Name: {} mobile: {} '. format(self.name, self.mobile))要在文件中腌制上述类的对象,我们使用 pickler 类及其 dump() 方法。
To pickle object of above class in a file we use pickler class and its dump()method.
from pickle import Pickler
user1=User('Rajani', 'raj@gmail.com', '1234567890')
file=open('userdata','wb')
Pickler(file).dump(user1)
Pickler(file).dump(user2)
file.close()相反,Unpickler 类有一个 load() 方法,可以如下检索已序列化的对象 −
Conversely, Unpickler class has load() method to retrieve serialized object as follows −
from pickle import Unpickler
file=open('usersdata','rb')
user1=Unpickler(file).load()
print (user1)Python Data Persistence - Marshal Module
Python 标准库中 marshal 模块的对象序列化特性类似于 pickle 模块。然而,此模块不用于一般用途的数据。另一方面,Python 本身使用它用于 Python 的内部对象序列化,以支持对 Python 模块(.pyc 文件)的编译版本进行读/写操作。
Object serialization features of marshal module in Python’s standard library are similar to pickle module. However, this module is not used for general purpose data. On the other hand, it is used by Python itself for Python’s internal object serialization to support read/write operations on compiled versions of Python modules (.pyc files).
marshal 模块使用的数据格式在 Python 版本之间不兼容。因此,一个版本的已编译 Python 脚本(.pyc 文件)很可能会在另一个版本上执行。
The data format used by marshal module is not compatible across Python versions. Therefore, a compiled Python script (.pyc file) of one version most probably won’t execute on another.
就像 pickle 模块一样,marshal 模块还定义了 load() 和 dump() 函数,用于从/到文件中读取和写入编组对象。
Just as pickle module, marshal module also defined load() and dump() functions for reading and writing marshalled objects from / to file.
dump()
此函数将受支持 Python 对象的字节表示形式写入文件。该文件本身是一个具有写权限的二进制文件。
This function writes byte representation of supported Python object to a file. The file itself be a binary file with write permission
load()
此函数从二进制文件读取字节数据并将其转换为 Python 对象。
This function reads the byte data from a binary file and converts it to Python object.
以下示例演示了使用 dump() 和 load() 函数来处理 Python 的代码对象,这些代码对象用于存储预编译的 Python 模块。
Following example demonstrates use of dump() and load() functions to handle code objects of Python, which are used to store precompiled Python modules.
此代码使用内置的 compile() 函数根据嵌入 Python 指令的源字符串构建代码对象。
The code uses built-in compile() function to build a code object out of a source string which embeds Python instructions.
compile(source, file, mode)file 参数应该是从中读取代码的文件。如果没有从文件读取,则传递任意字符串。
The file parameter should be the file from which the code was read. If it wasn’t read from a file pass any arbitrary string.
如果源包含语句序列,则 mode 参数为 'exec',如果有一个表达式,则为 'eval',如果包含一个交互式语句,则为 'single'。
The mode parameter is ‘exec’ if the source contains sequence of statements, ‘eval’ if there is a single expression or ‘single’ if it contains a single interactive statement.
然后使用 dump() 函数将编译代码对象存储在 .pyc 文件中。
The compile code object is then stored in a .pyc file using dump() function.
import marshal
script = """
a=10
b=20
print ('addition=',a+b)
"""
code = compile(script, "script", "exec")
f=open("a.pyc","wb")
marshal.dump(code, f)
f.close()要反序列化,使用 load() 函数从 .pyc 文件中获取对象。由于它返回一个代码对象,因此可以使用 exec()(另一个内置函数)运行它。
To deserialize, the object from .pyc file use load() function. Since, it returns a code object, it can be run using exec(), another built-in function.
import marshal
f=open("a.pyc","rb")
data=marshal.load(f)
exec (data)Python Data Persistence - Shelve Module
Python 标准库中的 shelve 模块提供了简单但有效的对象持久性机制。此模块中定义的 shelf 对象是类似于字典的对象,它持久性地存储在磁盘文件中。这会创建一个类似于 UNIX 类系统上的 dbm 数据库的文件。
The shelve module in Python’s standard library provides simple yet effective object persistence mechanism. The shelf object defined in this module is dictionary-like object which is persistently stored in a disk file. This creates a file similar to dbm database on UNIX like systems.
shelf 字典有一些限制。仅字符串数据类型可以作为此特殊字典对象中的键,而任何可 pickle 的 Python 对象都可以作为值。
The shelf dictionary has certain restrictions. Only string data type can be used as key in this special dictionary object, whereas any picklable Python object can be used as value.
shelf 模块定义了以下三种类:
The shelve module defines three classes as follows −
Sr.No |
Shelve Module & Description |
1 |
Shelf This is the base class for shelf implementations. It is initialized with dict-like object. |
2 |
BsdDbShelf This is a subclass of Shelf class. The dict object passed to its constructor must support first(), next(), previous(), last() and set_location() methods. |
3 |
DbfilenameShelf This is also a subclass of Shelf but accepts a filename as parameter to its constructor rather than dict object. |
shelve 模块中定义的 open() 函数返回 DbfilenameShelf 对象。
The open() function defined in shelve module which return a DbfilenameShelf object.
open(filename, flag='c', protocol=None, writeback=False)filename 参数被分配到创建的数据库。flag 参数的默认值为 "c",用于读/写访问。其他标记为 "w"(仅写)、"r"(仅读)和 "n"(新建,读/写)。
The filename parameter is assigned to the database created. Default value for flag parameter is ‘c’ for read/write access. Other flags are ‘w’ (write only) ‘r’ (read only) and ‘n’ (new with read/write).
序列化本身受 pickle 协议控制,默认为 none。最后一个参数 writeback 参数默认为 false。如果设置为 true,会缓存访问的条目。每次访问都会调用 sync() 和 close() 操作,因此进程可能会很慢。
The serialization itself is governed by pickle protocol, default is none. Last parameter writeback parameter by default is false. If set to true, the accessed entries are cached. Every access calls sync() and close() operations, hence process may be slow.
以下代码创建一个数据库并在其中存储字典条目。
Following code creates a database and stores dictionary entries in it.
import shelve
s=shelve.open("test")
s['name']="Ajay"
s['age']=23
s['marks']=75
s.close()这会在当前目录中创建 test.dir 文件并将键值数据存储在哈希形式中。Shelf 对象提供以下方法:
This will create test.dir file in current directory and store key-value data in hashed form. The Shelf object has following methods available −
Sr.No. |
Methods & Description |
1 |
close() synchronise and close persistent dict object. |
2 |
sync() Write back all entries in the cache if shelf was opened with writeback set to True. |
3 |
get() returns value associated with key |
4 |
items() list of tuples – each tuple is key value pair |
5 |
keys() list of shelf keys |
6 |
pop() remove specified key and return the corresponding value. |
7 |
update() Update shelf from another dict/iterable |
8 |
values() list of shelf values |
若要访问内容中特定键的值 −
To access value of a particular key in shelf −
s=shelve.open('test')
print (s['age']) #this will print 23
s['age']=25
print (s.get('age')) #this will print 25
s.pop('marks') #this will remove corresponding k-v pair内置词典对象中,items()、keys() 和 values() 方法返回视图对象。
As in a built-in dictionary object, the items(), keys() and values() methods return view objects.
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('marks', 75)]
print (list(s.keys()))
['name', 'age', 'marks']
print (list(s.values()))
['Ajay', 25, 75]若要将其他字典与内容的项目合并,请使用 update() 方法。
To merge items of another dictionary with shelf use update() method.
d={'salary':10000, 'designation':'manager'}
s.update(d)
print (list(s.items()))
[('name', 'Ajay'), ('age', 25), ('salary', 10000), ('designation', 'manager')]Python Data Persistence - dbm Package
dbm 包提供类似词典的界面,即 DBM 样式数据库。 DBM stands for DataBase Manager 。UNIX(以及类似 UNIX 的)操作系统使用这种形式。dbbm 库是由 Ken Thompson 编写的一个简单的数据库引擎。这些数据库使用二进制编码的字符串对象作为键和值。
The dbm package presents a dictionary like interface DBM style databases. DBM stands for DataBase Manager. This is used by UNIX (and UNIX like) operating system. The dbbm library is a simple database engine written by Ken Thompson. These databases use binary encoded string objects as key, as well as value.
数据库通过在一个固定大小的存储区中使用一个键(一个主键)储存数据,并使用哈希技术让用户能够使用键快速检索数据。
The database stores data by use of a single key (a primary key) in fixed-size buckets and uses hashing techniques to enable fast retrieval of the data by key.
dbm 包包含以下模块 −
The dbm package contains following modules −
-
dbm.gnu module is an interface to the DBM library version as implemented by the GNU project.
-
dbm.ndbm module provides an interface to UNIX nbdm implementation.
-
dbm.dumb is used as a fallback option in the event, other dbm implementations are not found. This requires no external dependencies but is slower than others.
>>> dbm.whichdb('mydbm.db')
'dbm.dumb'
>>> import dbm
>>> db=dbm.open('mydbm.db','n')
>>> db['name']=Raj Deshmane'
>>> db['address']='Kirtinagar Pune'
>>> db['PIN']='431101'
>>> db.close()open() 函数允许使用这些标志进行模式化 −
The open() function allows mode these flags −
Sr.No. |
Value & Meaning |
1 |
'r' Open existing database for reading only (default) |
2 |
'w' Open existing database for reading and writing |
3 |
'c' Open database for reading and writing, creating it if it doesn’t exist |
4 |
'n' Always create a new, empty database, open for reading and writing |
dbm 对象是类似词典的对象,就像内容对象。因此,所有词典操作均可执行。dbm 对象可以调用 get()、pop()、append() 和 update() 方法。以下代码使用“r”标志打开“mydbm.db”,然后迭代键值对集合。
The dbm object is a dictionary like object, just as shelf object. Hence, all dictionary operations can be performed. The dbm object can invoke get(), pop(), append() and update() methods. Following code opens 'mydbm.db' with 'r' flag and iterates over collection of key-value pairs.
>>> db=dbm.open('mydbm.db','r')
>>> for k,v in db.items():
print (k,v)
b'name' : b'Raj Deshmane'
b'address' : b'Kirtinagar Pune'
b'PIN' : b'431101'Python Data Persistence - CSV Module
CSV stands for comma separated values 。此文件格式是一种常用的数据格式,用于将数据导出/导入到/从数据库中的电子表格和数据表。csv 模块是 PEP 305 的结果,被纳入了 Python 标准库中。它提供类和方法,根据 PEP 305 的建议对 CSV 文件执行读/写操作。
CSV stands for comma separated values. This file format is a commonly used data format while exporting/importing data to/from spreadsheets and data tables in databases. The csv module was incorporated in Python’s standard library as a result of PEP 305. It presents classes and methods to perform read/write operations on CSV file as per recommendations of PEP 305.
CSV 是 Microsoft Excel 电子表格软件首选的导出数据格式。但是,csv 模块还可以处理其他方言表示的数据。
CSV is a preferred export data format by Microsoft’s Excel spreadsheet software. However, csv module can handle data represented by other dialects also.
CSV API 接口由以下 writer 和 reader 类组成:
The CSV API interface consists of following writer and reader classes −
writer()
csv 模块中的此函数返回一个 writer 对象,该对象将数据转换为分隔字符串,并将其存储在文件对象中。该函数需要具有写权限的文件对象作为参数。在文件中写入的每行都发出一个换行符。为了防止行之间有额外的空格,将换行符参数设置为 ''。
This function in csv module returns a writer object that converts data into a delimited string and stores in a file object. The function needs a file object with write permission as a parameter. Every row written in the file issues a newline character. To prevent additional space between lines, newline parameter is set to ''.
writer 类具有以下方法:
The writer class has following methods −
writerow()
此方法写入一个可迭代对象(列表、元组或字符串)中的项目,并用逗号分隔它们。
This method writes items in an iterable (list, tuple or string), separating them by comma character.
writerows()
此方法采用一个可迭代列表作为参数,并将每个项目写为文件中以逗号分隔的行项目。
This method takes a list of iterables, as parameter and writes each item as a comma separated line of items in the file.
Example
以下示例演示了 writer() 函数的用处。首先以“w”模式打开一个文件。此文件用于获取 writer 对象。然后使用 writerow() 方法将列表中的每个元组写至文件。
Following example shows use of writer() function. First a file is opened in ‘w’ mode. This file is used to obtain writer object. Each tuple in list of tuples is then written to file using writerow() method.
import csv
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
csvfile=open('persons.csv','w', newline='')
obj=csv.writer(csvfile)
for person in persons:
obj.writerow(person)
csvfile.close()Output
这将在当前目录中创建“persons.csv”文件。它将显示以下数据。
This will create ‘persons.csv’ file in current directory. It will show following data.
Lata,22,45
Anil,21,56
John,20,60我们可以使用 writerows() 方法,而不用遍历列表逐个编写每行。
Instead of iterating over the list to write each row individually, we can use writerows() method.
csvfile=open('persons.csv','w', newline='')
persons=[('Lata',22,45),('Anil',21,56),('John',20,60)]
obj=csv.writer(csvfile)
obj.writerows(persons)
obj.close()reader()
此函数返回一个读取对象,它返回 csv file 中行的迭代器。使用常规定位循环,以下示例中的所有文件行都将显示为 −
This function returns a reader object which returns an iterator of lines in the csv file. Using the regular for loop, all lines in the file are displayed in following example −
Example
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
for row in obj:
print (row)Output
['Lata', '22', '45']
['Anil', '21', '56']
['John', '20', '60']reading 对象是一个迭代器。因此,它支持 next() 函数,该函数也可以用于显示 csv 文件中的所有行,而不用显示 for loop 。
The reader object is an iterator. Hence, it supports next() function which can also be used to display all lines in csv file instead of a for loop.
csvfile=open('persons.csv','r', newline='')
obj=csv.reader(csvfile)
while True:
try:
row=next(obj)
print (row)
except StopIteration:
break如前所述,csv 模块使用 Excel 作为其默认方言。csv 模块还定义了一个方言类。方言是用于实现 CSV 协议的一组标准。可用的方言列表可以通过 list_dialects() 函数获取。
As mentioned earlier, csv module uses Excel as its default dialect. The csv module also defines a dialect class. Dialect is set of standards used to implement CSV protocol. The list of dialects available can be obtained by list_dialects() function.
>>> csv.list_dialects()
['excel', 'excel-tab', 'unix']除了可迭代对象外,csv 模块可以将字典对象导出到 CSV 文件,并读取它以填充 Python 字典对象。为此,此模块定义了以下类 −
In addition to iterables, csv module can export a dictionary object to CSV file and read it to populate Python dictionary object. For this purpose, this module defines following classes −
DictWriter()
此函数返回一个 DictWriter 对象。它与 writer 对象类似,但行映射到字典对象。该函数需要一个具有写入权限的文件对象和一个将字典中使用的键用作 fieldnames 参数的列表。这用于将第一个行写至文件作为标题。
This function returns a DictWriter object. It is similar to writer object, but the rows are mapped to dictionary object. The function needs a file object with write permission and a list of keys used in dictionary as fieldnames parameter. This is used to write first line in the file as header.
writeheader()
此方法将字典中的键列表写为第一个行中的以逗号分隔的行。
This method writes list of keys in dictionary as a comma separated line as first line in the file.
在以下示例中,定义了一个字典项目列表。列表中的每个项目都是一个字典。使用 writrows() 方法,它们以逗号分隔的方式写至文件。
In following example, a list of dictionary items is defined. Each item in the list is a dictionary. Using writrows() method, they are written to file in comma separated manner.
persons=[
{'name':'Lata', 'age':22, 'marks':45},
{'name':'Anil', 'age':21, 'marks':56},
{'name':'John', 'age':20, 'marks':60}
]
csvfile=open('persons.csv','w', newline='')
fields=list(persons[0].keys())
obj=csv.DictWriter(csvfile, fieldnames=fields)
obj.writeheader()
obj.writerows(persons)
csvfile.close()persons.csv 文件显示以下内容 −
The persons.csv file shows following contents −
name,age,marks
Lata,22,45
Anil,21,56
John,20,60DictReader()
此函数从基础 CSV 文件返回 DictReader 对象。与 reader 对象一样,它也是一个迭代器,使用它来检索文件内容。
This function returns a DictReader object from the underlying CSV file. As, in case of, reader object, this one is also an iterator, using which contents of the file are retrieved.
csvfile=open('persons.csv','r', newline='')
obj=csv.DictReader(csvfile)该类提供 fieldnames 属性,返回用作文件标题的字典键。
The class provides fieldnames attribute, returning the dictionary keys used as header of file.
print (obj.fieldnames)
['name', 'age', 'marks']使用 DictReader 对象上的循环来获取各个字典对象。
Use loop over the DictReader object to fetch individual dictionary objects.
for row in obj:
print (row)这就产生了以下输出 −
This results in following output −
OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
OrderedDict([('name', 'Anil'), ('age', '21'), ('marks', '56')])
OrderedDict([('name', 'John'), ('age', '20'), ('marks', '60')])要将 OrderedDict 对象转换为普通字典,我们必须先从 collections 模块导入 OrderedDict。
To convert OrderedDict object to normal dictionary, we have to first import OrderedDict from collections module.
from collections import OrderedDict
r=OrderedDict([('name', 'Lata'), ('age', '22'), ('marks', '45')])
dict(r)
{'name': 'Lata', 'age': '22', 'marks': '45'}Python Data Persistence - JSON Module
JSON 的全称是 JavaScript Object Notation 。它是一种轻量级数据交换格式。它是一种独立于语言且跨平台的文本格式,受许多编程语言支持。此格式用于 Web 服务器和客户端之间的交换数据。
JSON stands for JavaScript Object Notation. It is a lightweight data interchange format. It is a language-independent and cross platform text format, supported by many programming languages. This format is used for data exchange between the web server and clients.
JSON 格式类似于 pickle。然而,pickle 序列化是 Python 专用的,而 JSON 格式由许多语言实现,因此已成为通用标准。Python 标准库中的 json 模块的功能和界面类似于 pickle 和 marshal 模块。
JSON format is similar to pickle. However, pickle serialization is Python specific whereas JSON format is implemented by many languages hence has become universal standard. Functionality and interface of json module in Python’s standard library is similar to pickle and marshal modules.
正如同 pickle 模块一样,json 模块还提供了 dumps() 和 loads() 函数,用于将 Python 对象序列化为 JSON 编码字符串, dump() 和 load() 函数将序列化的 Python 对象写入文件/从文件中读取。
Just as in pickle module, the json module also provides dumps() and loads() function for serialization of Python object into JSON encoded string, and dump() and load() functions write and read serialized Python objects to/from file.
-
dumps() − This function converts the object into JSON format.
-
loads() − This function converts a JSON string back to Python object.
下面的示例演示了如何使用这些函数 −
Following example demonstrates basic usage of these functions −
import json
data=['Rakesh',{'marks':(50,60,70)}]
s=json.dumps(data)
json.loads(s)dumps() 函数可以获取可选的 sort_keys 参数。默认情况下,它为 False。如果设为 True,字典键将按 JSON 字符串中的排序顺序显示。
The dumps() function can take optional sort_keys argument. By default, it is False. If set to True, the dictionary keys appear in sorted order in the JSON string.
dumps() 函数有另一个可选参数,称为 indent,它将数字作为取值。它决定 json 字符串格式化表示的每个部分的长度,类似于打印输出。
The dumps() function has another optional parameter called indent which takes a number as value. It decides length of each segment of formatted representation of json string, similar to print output.
json 模块还具有与上述函数对应的面向对象 API。模块中定义了两个类 – JSONEncoder 和 JSONDecoder。
The json module also has object oriented API corresponding to above functions. There are two classes defined in the module – JSONEncoder and JSONDecoder.
JSONEncoder class
这个类的对象就是 Python 数据结构的编码器。如以下表格所示,每个 Python 数据类型都会转换成对应的 JSON 类型 −
Object of this class is encoder for Python data structures. Each Python data type is converted in corresponding JSON type as shown in following table −
Python |
JSON |
Dict |
object |
list, tuple |
array |
Str |
string |
int, float, int- & float-derived Enums |
number |
True |
true |
False |
false |
None |
null |
JSONEncoder 类由 JSONEncoder() 构造函数实例化。编码器类中定义了以下重要方法 −
The JSONEncoder class is instantiated by JSONEncoder() constructor. Following important methods are defined in encoder class −
Sr.No. |
Methods & Description |
1 |
encode() serializes Python object into JSON format |
2 |
iterencode() Encodes the object and returns an iterator yielding encoded form of each item in the object. |
3 |
indent Determines indent level of encoded string |
4 |
sort_keys is either true or false to make keys appear in sorted order or not. |
5 |
Check_circular if True, check for circular reference in container type object |
以下示例对 Python 列表对象进行编码。
Following example encodes Python list object.
e=json.JSONEncoder()
e.encode(data)JSONDecoder class
此类的对象有助于将解码的 JSON 字符串还原为 Python 数据结构。此类中的主要方法是 decode()。以下示例代码从早期步骤中的编码字符串中检索 Python 列表对象。
Object of this class helps in decoded in json string back to Python data structure. Main method in this class is decode(). Following example code retrieves Python list object from encoded string in earlier step.
d=json.JSONDecoder()
d.decode(s)json 模块定义了 load() 和 dump() 函数,用于将 JSON 数据写入到磁盘文件或字节流等文件对象中,并从中读取数据。
The json module defines load() and dump() functions to write JSON data to a file like object – which may be a disk file or a byte stream and read data back from them.
dump()
此函数将 JSON 的 Python 对象数据写入文件。此文件必须使用“w”模式打开。
This function writes JSONed Python object data to a file. The file must be opened with ‘w’ mode.
import json
data=['Rakesh', {'marks': (50, 60, 70)}]
fp=open('json.txt','w')
json.dump(data,fp)
fp.close()此代码将在当前目录中创建“json.txt”。它显示的内容如下:
This code will create ‘json.txt’ in current directory. It shows the contents as follows −
["Rakesh", {"marks": [50, 60, 70]}]load()
此函数从文件中加载 JSON 数据并从中返回 Python 对象。此文件必须使用读取权限(应具有“r”模式)打开。
This function loads JSON data from the file and returns Python object from it. The file must be opened with read permission (should have ‘r’ mode).
Example
fp=open('json.txt','r')
ret=json.load(fp)
print (ret)
fp.close()Output
['Rakesh', {'marks': [50, 60, 70]}]json.tool 模块还有一个命令行界面,用于验证文件中的数据并以漂亮的格式打印 JSON 对象。
The json.tool module also has a command-line interface that validates data in file and prints JSON object in a pretty formatted manner.
C:\python37>python -m json.tool json.txt
[
"Rakesh",
{
"marks": [
50,
60,
70
]
}
]Python Data Persistence - XML Parsers
XML 是 eXtensible Markup Language 的首字母缩写。它是一种便携式、开放源码且跨平台的语言,非常类似于 HTML 或 SGML,并且得到万维网联盟的推荐。
XML is acronym for eXtensible Markup Language. It is a portable, open source and cross platform language very much like HTML or SGML and recommended by the World Wide Web Consortium.
它是一种众所周知的用于大量应用程序(例如 Web 服务、办公工具和 Service Oriented Architectures (SOA))的数据交换格式。XML 格式机器可读且人类可读。
It is a well-known data interchange format, used by a large number of applications such as web services, office tools, and Service Oriented Architectures (SOA). XML format is both machine readable and human readable.
标准 Python 库的 XML 包包含以下用于处理 XML 的模块:
Standard Python library’s xml package consists of following modules for XML processing −
Sr.No. |
Modules & Description |
1 |
xml.etree.ElementTree the ElementTree API, a simple and lightweight XML processor |
2 |
xml.dom the DOM API definition |
3 |
xml.dom.minidom a minimal DOM implementation |
4 |
xml.sax SAX2 interface implementation |
5 |
xml.parsers.expat the Expat parser binding |
XML 文档中数据以树状分层格式进行排列,从根元素开始。每个元素都是树中的一个单独节点,具有括在 <> 和 </> 标记之间的一个属性。可以将一个或多个子元素分配给每个元素。
Data in the XML document is arranged in a tree-like hierarchical format, starting with root and elements. Each element is a single node in the tree and has an attribute enclosed in <> and </> tags. One or more sub-elements may be assigned to each element.
以下是 XML 文档的一个典型示例:
Following is a typical example of a XML document −
<?xml version = "1.0" encoding = "iso-8859-1"?>
<studentlist>
<student>
<name>Ratna</name>
<subject>Physics</subject>
<marks>85</marks>
</student>
<student>
<name>Kiran</name>
<subject>Maths</subject>
<marks>100</marks>
</student>
<student>
<name>Mohit</name>
<subject>Biology</subject>
<marks>92</marks>
</student>
</studentlist>在使用 ElementTree 模块时,第一步是为树设置根元素。每个元素都具有一个标记和属性,它是一个字典对象。对于根元素,属性是一个空字典。
While using ElementTree module, first step is to set up root element of the tree. Each Element has a tag and attrib which is a dict object. For the root element, an attrib is an empty dictionary.
import xml.etree.ElementTree as xmlobj
root=xmlobj.Element('studentList')现在,我们可以在根元素下添加一个或多个元素。每个元素对象可能具有 SubElements 。每个子元素具有一个属性和文本属性。
Now, we can add one or more elements under root element. Each element object may have SubElements. Each subelement has an attribute and text property.
student=xmlobj.Element('student')
nm=xmlobj.SubElement(student, 'name')
nm.text='name'
subject=xmlobj.SubElement(student, 'subject')
nm.text='Ratna'
subject.text='Physics'
marks=xmlobj.SubElement(student, 'marks')
marks.text='85'使用 append() 方法将此新元素附加到根元素。
This new element is appended to the root using append() method.
root.append(student)使用上述方法追加任意多的元素。最后,将根元素对象写入文件。
Append as many elements as desired using above method. Finally, the root element object is written to a file.
tree = xmlobj.ElementTree(root)
file = open('studentlist.xml','wb')
tree.write(file)
file.close()现在,我们了解如何解析 XML 文件。为此,通过将它的名称作为 ElementTree 构造函数中的文件参数来构造文档树。
Now, we see how to parse the XML file. For that, construct document tree giving its name as file parameter in ElementTree constructor.
tree = xmlobj.ElementTree(file='studentlist.xml')树对象具有 getroot() 方法来获取根元素,而 getchildren() 返回位于它下方的一系列元素。
The tree object has getroot() method to obtain root element and getchildren() returns a list of elements below it.
root = tree.getroot()
children = root.getchildren()通过迭代每个子节点的子元素集合,构造一个对应于每个子元素的字典对象。
A dictionary object corresponding to each sub element is constructed by iterating over sub-element collection of each child node.
for child in children:
student={}
pairs = child.getchildren()
for pair in pairs:
product[pair.tag]=pair.text然后将每个字典附加到列表,返回字典对象的原始列表。
Each dictionary is then appended to a list returning original list of dictionary objects.
SAX 是用于事件驱动 XML 解析的标准接口。使用 SAX 解析 XML 要求通过对 xml.sax.ContentHandler 进行子类化来使用 ContentHandler。您注册针对感兴趣的事件的回调,然后让解析器继续处理文档。
SAX is a standard interface for event-driven XML parsing. Parsing XML with SAX requires ContentHandler by subclassing xml.sax.ContentHandler. You register callbacks for events of interest and then, let the parser proceed through the document.
SAX 在文档较大或存在内存限制的情况下非常有用,因为它在磁盘读取文件时会对其进行解析,因此整个文件永远不会存储在内存中。
SAX is useful when your documents are large or you have memory limitations as it parses the file as it reads it from disk as a result entire file is never stored in the memory.
Document Object Model
(DOM) API 是一个万维网联盟推荐。在这种情况下,将整个文件读入内存并存储在分层(基于树)的形式中,以表示 XML 文档的所有特性。
(DOM) API is a World Wide Web Consortium recommendation. In this case, entire file is read into the memory and stored in a hierarchical (tree-based) form to represent all the features of an XML document.
SAX 速度不如 DOM,对于较大的文件。另一方面,如果 DOM 用于多个小文件,则可能会耗尽资源。SAX 是只读的,而 DOM 允许更改 XML 文件。
SAX, not as fast as DOM, with large files. On the other hand, DOM can kill resources, if used on many small files. SAX is read-only, while DOM allows changes to the XML file.
Python Data Persistence - Plistlib Module
plist 格式主要用于 MAC OS X。这些文件基本上是 XML 文档。它们存储和检索对象的属性。Python 库包含 plist 模块,用于读取和写入“属性列表”文件(它们通常具有 .plist”扩展名)。
The plist format is mainly used by MAC OS X. These files are basically XML documents. They store and retrieve properties of an object. Python library contains plist module, that is used to read and write 'property list' files (they usually have .plist' extension).
plistlib 模块在意义上与其他序列化库比较类似,它也提供 dumps() 和 loads() 函数用于 Python 对象的字符串表示,以及 load() 和 dump() 函数用于磁盘操作。
The plistlib module is more or less similar to other serialization libraries in the sense, it also provides dumps() and loads() functions for string representation of Python objects and load() and dump() functions for disk operation.
以下字典对象维护着属性(键)和相应的价值 −
Following dictionary object maintains property (key) and corresponding value −
proplist = {
"name" : "Ganesh",
"designation":"manager",
"dept":"accts",
"salary" : {"basic":12000, "da":4000, "hra":800}
}为了将这些属性写到磁盘文件中,我们调用 plist 模块中的 dump() 函数。
In order to write these properties in a disk file, we call dump() function in plist module.
import plistlib
fileName=open('salary.plist','wb')
plistlib.dump(proplist, fileName)
fileName.close()相反,为了读回属性值,按如下所示使用 load() 函数 −
Conversely, to read back the property values, use load() function as follows −
fp= open('salary.plist', 'rb')
pl = plistlib.load(fp)
print(pl)Python Data Persistence - Sqlite3 Module
CSV、JSON、XML 等文件的一个主要缺点是,它们对随机访问和事务处理并不十分起作用,因为它们在很大程度上都是非结构化的。因此,对内容进行修改变得非常困难。
One major disadvantage of CSV, JSON, XML, etc., files is that they are not very useful for random access and transaction processing because they are largely unstructured in nature. Hence, it becomes very difficult to modify the contents.
这些平面文件不适合于客户-服务器环境,因为它们缺乏异步处理能力。使用非结构化数据文件会导致数据冗余和不一致。
These flat files are not suitable for client-server environment as they lack asynchronous processing capability. Using unstructured data files leads to data redundancy and inconsistency.
这些问题可以通过使用关系数据库来克服。数据库是一个有组织的数据集合,用于消除冗余和不一致,并维护数据完整性。关系数据库模型非常流行。
These problems can be overcome by using a relational database. A database is an organized collection of data to remove redundancy and inconsistency, and maintain data integrity. The relational database model is vastly popular.
它的基本概念是按实体表(称作关系)排列数据。实体表结构提供了一个属性,其值为每行唯一。这样的属性称为 'primary key' 。
Its basic concept is to arrange data in entity table (called relation). The entity table structure provides one attribute whose value is unique for each row. Such an attribute is called 'primary key'.
当一个表的主键显示在其他表的结构中时,这称为 'Foreign key' ,并且这形成了两个表之间关系的基础。基于此模型,目前有许多流行的关系型数据库管理系统产品 −
When primary key of one table appears in the structure of other tables, it is called 'Foreign key' and this forms the basis of the relationship between the two. Based on this model, there are many popular RDBMS products currently available −
-
GadFly
-
mSQL
-
MySQL
-
PostgreSQL
-
Microsoft SQL Server 2000
-
Informix
-
Interbase
-
Oracle
-
Sybase
-
SQLite
SQLite 是一款轻量级关系数据库,用于各种各样的应用程序。它是一款自包含的、无服务器的、零配置的、事务性的 SQL 数据库引擎。整个数据库是一个独立文件,可以放置在文件系统的任何地方。它是一款开源软件,占用空间非常小,并且无需任何配置。它通常用于嵌入式设备、物联网和移动应用程序。
SQLite is a lightweight relational database used in a wide variety of applications. It is a self-contained, serverless, zero-configuration, transactional SQL database engine. The entire database is a single file, that can be placed anywhere in the file system. It’s an open-source software, with very small footprint, and zero configuration. It is popularly used in embedded devices, IOT and mobile apps.
所有关系数据库都使用 SQL 在表格中处理数据。然而,较早以前,每个此类数据库都使用特定于数据库类型的 Python 模块与 Python 应用程序相连接。
All relational databases use SQL for handling data in tables. However, earlier, each of these databases used to be connected with Python application with the help of Python module specific to the type of database.
因此,它们之间缺乏兼容性。如果用户希望转向不同的数据库产品,这将被证明是困难的。通过提出“Python 增强提案 (PEP 248)”以推荐与称为 DB-API 的关系数据库相一致的接口,解决了这种不兼容性问题。最新的推荐称为 DB-API 2.0 版本。(PEP 249)
Hence, there was a lack of compatibility among them. If a user wanted to change to different database product, it would prove to be difficult. This incompatibility issue was addresses by raising 'Python Enhancement Proposal (PEP 248)' to recommend consistent interface to relational databases known as DB-API. Latest recommendations are called DB-API Version 2.0. (PEP 249)
Python 的标准库包含 sqlite3 模块,这是一个 DB-API 兼容模块,可通过 Python 程序处理 SQLite 数据库。本章解释了 Python 与 SQLite 数据库的连接。
Python’s standard library consists of the sqlite3 module which is a DB-API compliant module for handling the SQLite database through Python program. This chapter explains Python’s connectivity with SQLite database.
如前所述,Python 在 sqlite3 模块的形式中包含了对 SQLite 数据库的内置支持。对于其他数据库,必须使用 pip 实用工具安装相应的 DB-API 兼容 Python 模块。例如,要使用 MySQL 数据库,我们需要安装 PyMySQL 模块。
As mentioned earlier, Python has inbuilt support for SQLite database in the form of sqlite3 module. For other databases, respective DB-API compliant Python module will have to be installed with the help of pip utility. For example, to use MySQL database we need to install PyMySQL module.
pip install pymysql在 DB-API 中推荐以下步骤 −
Following steps are recommended in DB-API −
-
Establish connection with the database using connect() function and obtain connection object.
-
Call cursor() method of connection object to get cursor object.
-
Form a query string made up of a SQL statement to be executed.
-
Execute the desired query by invoking execute() method.
-
Close the connection.
import sqlite3
db=sqlite3.connect('test.db')此处,db 是表示 test.db 的连接对象。请注意,如果数据库尚未存在,它将被创建。连接对象 db 具有以下方法 −
Here, db is the connection object representing test.db. Note, that database will be created if it doesn’t exist already. The connection object db has following methods −
Sr.No. |
Methods & Description |
1 |
cursor(): Returns a Cursor object which uses this Connection. |
2 |
commit(): Explicitly commits any pending transactions to the database. |
3 |
rollback(): This optional method causes a transaction to be rolled back to the starting point. |
4 |
close(): Closes the connection to the database permanently. |
游标作为给定 SQL 查询的句柄,允许检索结果中一行或多行。从连接获取游标对象以使用以下语句执行 SQL 查询 −
A cursor acts as a handle for a given SQL query allowing the retrieval of one or more rows of the result. Cursor object is obtained from the connection to execute SQL queries using the following statement −
cur=db.cursor()游标对象具有以下定义的方法 −
The cursor object has following methods defined −
Sr.No |
Methods & Description |
1 |
execute() Executes the SQL query in a string parameter. |
2 |
executemany() Executes the SQL query using a set of parameters in the list of tuples. |
3 |
fetchone() Fetches the next row from the query result set. |
4 |
fetchall() Fetches all remaining rows from the query result set. |
5 |
callproc() Calls a stored procedure. |
6 |
close() Closes the cursor object. |
以下代码在 test.db 中创建一个表:-
Following code creates a table in test.db:-
import sqlite3
db=sqlite3.connect('test.db')
cur =db.cursor()
cur.execute('''CREATE TABLE student (
StudentID INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT (20) NOT NULL,
age INTEGER,
marks REAL);''')
print ('table created successfully')
db.close()数据库中所需的数据完整性通过连接对象的 commit() 和 rollback() 方法实现。SQL 查询字符串可能包含可能引发异常的错误 SQL 查询,该异常应得到妥善处理。为此,execute() 语句放置在 try 块中。如果成功,则使用 commit() 方法永久保存结果。如果查询失败,则使用 rollback() 方法撤消交易。
Data integrity desired in a database is achieved by commit() and rollback() methods of the connection object. The SQL query string may be having an incorrect SQL query that can raise an exception, which should be properly handled. For that, the execute() statement is placed within the try block If it is successful, the result is persistently saved using the commit() method. If the query fails, the transaction is undone using the rollback() method.
以下代码在 test.db 中的 student 表上执行 INSERT 查询。
Following code executes INSERT query on the student table in test.db.
import sqlite3
db=sqlite3.connect('test.db')
qry="insert into student (name, age, marks) values('Abbas', 20, 80);"
try:
cur=db.cursor()
cur.execute(qry)
db.commit()
print ("record added successfully")
except:
print ("error in query")
db.rollback()
db.close()如果你希望 INSERT 查询中的值子句由用户输入动态提供,请使用 Python DB-API 中推荐的参数替换。?字符用作查询字符串中的占位符,并以元组形式提供 execute() 方法中的值。以下示例使用参数替换方法插入记录。将姓名、年龄和分数作为输入。
If you want data in values clause of INSERT query to by dynamically provided by user input, use parameter substitution as recommended in Python DB-API. The ? character is used as a placeholder in the query string and provides the values in the form of a tuple in the execute() method. The following example inserts a record using the parameter substitution method. Name, age and marks are taken as input.
import sqlite3
db=sqlite3.connect('test.db')
nm=input('enter name')
a=int(input('enter age'))
m=int(input('enter marks'))
qry="insert into student (name, age, marks) values(?,?,?);"
try:
cur=db.cursor()
cur.execute(qry, (nm,a,m))
db.commit()
print ("one record added successfully")
except:
print("error in operation")
db.rollback()
db.close()sqlite3 模块定义了 executemany() 方法,该方法能够一次添加多条记录。要添加的数据应以元组列表提供,每个元组包含一条记录。列表对象是 executemany() 方法的参数,以及查询字符串。但是,某些其他模块不支持 executemany() 方法。
The sqlite3 module defines The executemany() method which is able to add multiple records at once. Data to be added should be given in a list of tuples, with each tuple containing one record. The list object is the parameter of the executemany() method, along with the query string. However, executemany() method is not supported by some of the other modules.
UPDATE 查询通常包含 WHERE 子句指定的逻辑表达式。execute() 方法中的查询字符串应包含 UPDATE 查询语法。若要将名称为“Anil”的“age”值更新为 23,请按如下方式定义字符串:
The UPDATE query usually contains a logical expression specified by WHERE clause The query string in the execute() method should contain an UPDATE query syntax. To update the value of 'age' to 23 for name='Anil', define the string as below:
qry="update student set age=23 where name='Anil';"为了使更新过程更具动态性,我们使用如上所述的参数替换方法。
To make the update process more dynamic, we use the parameter substitution method as described above.
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
a=int(input(‘enter age’))
qry="update student set age=? where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (a, nm))
db.commit()
print("record updated successfully")
except:
print("error in query")
db.rollback()
db.close()类似地,DELETE 操作是通过使用包含 SQL 的 DELETE 查询语法的字符串调用 execute() 方法执行的。顺便提一下, DELETE 查询通常也包含 WHERE 子句。
Similarly, DELETE operation is performed by calling execute() method with a string having SQL’s DELETE query syntax. Incidentally, DELETE query also usually contains a WHERE clause.
import sqlite3
db=sqlite3.connect('test.db')
nm=input(‘enter name’)
qry="DELETE from student where name=?;"
try:
cur=db.cursor()
cur.execute(qry, (nm,))
db.commit()
print("record deleted successfully")
except:
print("error in operation")
db.rollback()
db.close()对数据库表进行的重要操作之一是从中检索记录。SQL 为此提供 SELECT 查询。当将包含 SELECT 查询语法的字符串提供给 execute() 方法时,将返回结果集对象。使用游标对象有两个重要的方法,可以使用它们从结果集中检索一条或多条记录。
One of the important operations on a database table is retrieval of records from it. SQL provides SELECT query for the purpose. When a string containing SELECT query syntax is given to execute() method, a result set object is returned. There are two important methods with a cursor object using which one or many records from the result set can be retrieved.
fetchone()
从结果集中提取下一个可用的记录。这是一个元组,由检索到的记录的每一列的值组成。
Fetches the next available record from the result set. It is a tuple consisting of values of each column of the fetched record.
fetchall()
以元组列表的形式检索所有剩余的记录。每个元组对应一个记录,并包含表的每列的值。
Fetches all remaining records in the form of a list of tuples. Each tuple corresponds to one record and contains values of each column in the table.
以下示例列出了学生表中的所有记录
Following example lists all records in student table
import sqlite3
db=sqlite3.connect('test.db')
37
sql="SELECT * from student;"
cur=db.cursor()
cur.execute(sql)
while True:
record=cur.fetchone()
if record==None:
break
print (record)
db.close()如果您计划使用 MySQL 数据库而不是 SQLite 数据库,则需要按照上述说明安装 PyMySQL 模块。由于 MySQL 数据库安装在服务器上,因此数据库连接过程中的所有步骤都是相同的,connect() 函数需要 URL 和登录凭据。
If you plan to use a MySQL database instead of SQLite database, you need to install PyMySQL module as described above. All the steps in database connectivity process being same, since MySQL database is installed on a server, the connect() function needs the URL and login credentials.
import pymysql
con=pymysql.connect('localhost', 'root', '***')可能与 SQLite 不同的唯一一件事是 MySQL 特定的数据类型。同样,通过安装 pyodbc 模块,任何 ODBC 兼容数据库都可以与 Python 一起使用。
Only thing that may differ with SQLite is MySQL specific data types. Similarly, any ODBC compatible database can be used with Python by installing pyodbc module.
Python Data Persistence - SQLAlchemy
任何关系数据库中的数据都存储在表中。表结构定义了基本数据类型的属性数据类型,这些数据类型通常仅映射到 Python 的内置数据类型。但是,Python 的用户定义对象不能持久地存储到/检索自 SQL 表。
Any relational database holds data in tables. The table structure defines data type of attributes which are basically of primary data types only which are mapped to corresponding built-in data types of Python. However, Python’s user-defined objects can’t be persistently stored and retrieved to/from SQL tables.
这是 SQL 类型与面向对象编程语言(如 Python)之间的差异。SQL 对其他对象(如 dict、元组、列表或任何用户定义的类)没有等效的数据类型。
This is a disparity between SQL types and object oriented programming languages such as Python. SQL doesn’t have equivalent data type for others such as dict, tuple, list, or any user defined class.
如果你必须将对象存储在关系数据库中,则必须先将其实例属性解构为 SQL 数据类型,然后再执行 INSERT 查询。另一方面,从 SQL 表中检索到的数据为原始类型。必须使用所需类型的 Python 对象,才能在 Python 脚本中使用。这是对象关系映射工具发挥作用的地方。
If you have to store an object in a relational database, it’s instance attributes should be deconstructed into SQL data types first, before executing INSERT query. On the other hand, data retrieved from a SQL table is in primary types. A Python object of desired type will have to be constructed by using for use in Python script. This is where Object Relational Mappers are useful.
Object Relation Mapper (ORM)
Object Relation Mapper (ORM) 是类与 SQL 表之间的接口。Python 类映射到数据库中的某个表中,这样对象和 SQL 类型之间的转换将自动执行。
An Object Relation Mapper (ORM) is an interface between a class and a SQL table. A Python class is mapped to a certain table in database, so that conversion between object and SQL types is automatically performed.
用 Python 代码编写的 Students 类映射到数据库中的 Students 表中。因此,所有 CRUD 操作都是通过调用类的各个方法来完成的。这样消除了在 Python 脚本中执行硬编码 SQL 查询的需要。
The Students class written in Python code is mapped to Students table in the database. As a result, all CRUD operations are done by calling respective methods of the class. This eliminates need to execute hard coded SQL queries in Python script.
因此,ORM 库充当对原始 SQL 查询的抽象层,有助于快速应用程序开发。 SQLAlchemy 是 Python 的流行对象关系映射器。对模型对象状态的任何操作都将与其在数据库表中的相关行同步。
ORM library thus acts as an abstraction layer over the raw SQL queries and can be of help in rapid application development. SQLAlchemy is a popular object relational mapper for Python. Any manipulation of state of model object is synchronized with its related row in the database table.
SQLALchemy 库包含 ORM API 和 SQL 表达式语言( SQLAlchemy Core )。表达式语言直接执行关系数据库的基本构造。
SQLALchemy library includes ORM API and SQL Expression Language (SQLAlchemy Core). Expression language executes primitive constructs of the relational database directly.
ORM 是构建在 SQL 表达式语言之上的高级抽象化使用模式。可以说,ORM 是表达语言的应用。在该主题中,我们将讨论 SQLAlchemy ORM API 并使用 SQLite 数据库。
ORM is a high level and abstracted pattern of usage constructed on top of the SQL Expression Language. It can be said that ORM is an applied usage of the Expression Language. We shall discuss SQLAlchemy ORM API and use SQLite database in this topic.
SQLAlchemy 通过使用方言系统使用它们各自的 DBAPI 实现与各种类型的数据库通信。所有方言都要求安装适当的 DBAPI 驱动程序。以下类型的数据库方言包括:
SQLAlchemy communicates with various types of databases through their respective DBAPI implementations using a dialect system. All dialects require that an appropriate DBAPI driver is installed. Dialects for following type of databases are included −
-
Firebird
-
Microsoft SQL Server
-
MySQL
-
Oracle
-
PostgreSQL
-
SQLite
-
Sybase

安装 SQLAlchemy 非常简单,使用 pip 程序包管理器。
Installation of SQLAlchemy is easy and straightforward, using pip utility.
pip install sqlalchemy要检查 SQLalchemy 是否正确安装及其版本,请在 Python 提示符下输入以下命令:
To check if SQLalchemy is properly installed and its version, enter following on Python prompt −
>>> import sqlalchemy
>>>sqlalchemy.__version__
'1.3.11'与数据库的交互通过作为 create_engine() 函数返回值获取的引擎对象来完成。
Interactions with database are done through Engine object obtained as a return value of create_engine() function.
engine =create_engine('sqlite:///mydb.sqlite')SQLite 允许创建内存中的数据库。内存中数据库的 SQLAlchemy 引擎创建如下:
SQLite allows creation of in-memory database. SQLAlchemy engine for in-memory database is created as follows −
from sqlalchemy import create_engine
engine=create_engine('sqlite:///:memory:')如果你打算使用 MySQL 数据库,请使用其 DB-API 模块 – pymysql 和相关方言驱动程序。
If you intend to use MySQL database instead, use its DB-API module – pymysql and respective dialect driver.
engine = create_engine('mysql+pymydsql://root@localhost/mydb')create_engine 有一个可选的 echo 参数。如果设置为 true,引擎生成的 SQL 查询将在终端上显示。
The create_engine has an optional echo argument. If set to true, the SQL queries generated by engine will be echoed on the terminal.
SQLAlchemy 包含 declarative base 类。它作为模型类和映射表的目录。
SQLAlchemy contains declarative base class. It acts as a catalog of model classes and mapped tables.
from sqlalchemy.ext.declarative import declarative_base
base=declarative_base()下一步是定义模型类。它必须派生自基本对象 – 如上所述的 declarative_base 类。
Next step is to define a model class. It must be derived from base – object of declarative_base class as above.
将 *tablename* 属性设置为要创建的表在数据库中的名称。其他属性对应于字段。每个属性都是 SQLAlchemy 中的一个 Column 对象,并且其数据类型来自以下列表之一:
Set *tablename* property to name of the table you want to be created in the database. Other attributes correspond to the fields. Each one is a Column object in SQLAlchemy and its data type is from one of the list below −
-
BigInteger
-
Boolean
-
Date
-
DateTime
-
Float
-
Integer
-
Numeric
-
SmallInteger
-
String
-
Text
-
Time
以下代码是一个名为 Student 的模型类,它映射到 Students 表。
Following code is the model class named as Student that is mapped to Students table.
#myclasses.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Numeric
base=declarative_base()
class Student(base):
__tablename__='Students'
StudentID=Column(Integer, primary_key=True)
name=Column(String)
age=Column(Integer)
marks=Column(Numeric)要创建一个具有对应结构的 Students 表,请执行为基本类定义的 create_all() 方法。
To create a Students table that has a corresponding structure, execute create_all() method defined for base class.
base.metadata.create_all(engine)我们现在必须声明一个 Student 类的对象。所有数据库事务(比如添加、删除或从数据库中检索数据等)都由 Session 对象处理。
We now have to declare an object of our Student class. All database transactions such as add, delete or retrieve data from database, etc., are handled by a Session object.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()存储在 Student 对象中的数据通过会话的 add() 方法在底层表中物理添加。
Data stored in Student object is physically added in underlying table by session’s add() method.
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()以下是向 students 表中添加记录的整个代码。在执行该代码时,将在控制台上显示相应的 SQL 语句日志。
Here, is the entire code for adding record in students table. As it is executed, corresponding SQL statement log is displayed on console.
from sqlalchemy import Column, Integer, String
from sqlalchemy import create_engine
from myclasses import Student, base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
s1 = Student(name='Juhi', age=25, marks=200)
sessionobj.add(s1)
sessionobj.commit()Console output
CREATE TABLE "Students" (
"StudentID" INTEGER NOT NULL,
name VARCHAR,
age INTEGER,
marks NUMERIC,
PRIMARY KEY ("StudentID")
)
INFO sqlalchemy.engine.base.Engine ()
INFO sqlalchemy.engine.base.Engine COMMIT
INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
INFO sqlalchemy.engine.base.Engine INSERT INTO "Students" (name, age, marks) VALUES (?, ?, ?)
INFO sqlalchemy.engine.base.Engine ('Juhi', 25, 200.0)
INFO sqlalchemy.engine.base.Engine COMMITsession 对象还提供 add_all() 方法,以在单个事务中插入多个对象。
The session object also provides add_all() method to insert more than one objects in a single transaction.
sessionobj.add_all([s2,s3,s4,s5])
sessionobj.commit()既然已在表中添加了记录,我们想要像 SELECT 查询一样从中提取记录。会话对象有 query() 方法来执行该任务。在我们的 Student 模型上,query() 方法会返回查询对象。
Now that, records are added in the table, we would like to fetch from it just as SELECT query does. The session object has query() method to perform the task. Query object is returned by query() method on our Student model.
qry=seesionobj.query(Student)使用此 Query 对象的 get() 方法提取与给定主键对应的对象。
Use the get() method of this Query object fetches object corresponding to given primary key.
S1=qry.get(1)在执行此语句时,它在控制台上回显的相应 SQL 语句如下所示:
While this statement is executed, its corresponding SQL statement echoed on the console will be as follows −
BEGIN (implicit)
SELECT "Students"."StudentID" AS "Students_StudentID", "Students".name AS
"Students_name", "Students".age AS "Students_age",
"Students".marks AS "Students_marks"
FROM "Students"
WHERE "Products"."Students" = ?
sqlalchemy.engine.base.Engine (1,)query.all() 方法返回所有对象的列表,该列表可以使用循环来遍历。
The query.all() method returns a list of all objects which can be traversed using a loop.
from sqlalchemy import Column, Integer, String, Numeric
from sqlalchemy import create_engine
from myclasses import Student,base
engine = create_engine('sqlite:///college.db', echo=True)
base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
sessionobj = Session()
qry=sessionobj.query(Students)
rows=qry.all()
for row in rows:
print (row)更新映射表中的记录非常容易。您所要做的就是使用 get() 方法提取记录,为所需的属性分配一个新值,然后使用会话对象提交更改。在下面,我们将 Juhi 学生的分数更改为 100。
Updating a record in the mapped table is very easy. All you have to do is fetch a record using get() method, assign a new value to desired attribute and then commit the changes using session object. Below we change marks of Juhi student to 100.
S1=qry.get(1)
S1.marks=100
sessionobj.commit()删除记录同样容易,只需从会话中删除所需的对象即可。
Deleting a record is just as easy, by deleting desired object from the session.
S1=qry.get(1)
Sessionobj.delete(S1)
sessionobj.commit()Python Data Persistence - PyMongo module
MongoDB 是一个面向 NoSQL 数据库的文档。它是一个在服务端公共许可证下分发的跨平台数据库。它使用类似 JSON 的文档作为架构。
MongoDB is a document oriented NoSQL database. It is a cross platform database distributed under server side public license. It uses JSON like documents as schema.
为了提供存储海量数据的能力,超过一个物理服务器(称为分片)相互连接,从而实现横向可扩展性。MongoDB 数据库由文档组成。
In order to provide capability to store huge data, more than one physical servers (called shards) are interconnected, so that a horizontal scalability is achieved. MongoDB database consists of documents.

文档类似于关系数据库中的表中的行。但是,它没有特定的模式。文档是键值对的集合——类似于字典。但是,每个文档中的键值对的数量可能有所不同。就像关系数据库中的表具有主键一样,MongoDB 数据库中的文档具有一个称为 "_id" 的特殊键。
A document is analogous to a row in a table of relational database. However, it doesn’t have a particular schema. Document is a collection of key-value pairs - similar to dictionary. However, number of k-v pairs in each document may vary. Just as a table in relational database has a primary key, document in MongoDB database has a special key called "_id".
在了解如何将 MongoDB 数据库与 Python 一起使用之前,让我们简要了解如何安装和启动 MongoDB。MongoDB 提供社区版和商业版。社区版本可以从 www.mongodb.com/download-center/community 下载。
Before we see how MongoDB database is used with Python, let us briefly understand how to install and start MongoDB. Community and commercial version of MongoDB is available. Community version can be downloaded from www.mongodb.com/download-center/community.
假设 MongoDB 安装在 c:\mongodb 中,则可以使用以下命令调用服务器。
Assuming that MongoDB is installed in c:\mongodb, the server can be invoked using following command.
c:\mongodb\bin>mongodMongoDB 服务器默认在端口号 22017 上处于活动状态。数据库默认存储在 data/bin 文件夹中,尽管可以通过 –dbpath 选项更改位置。
The MongoDB server is active at port number 22017 by default. Databases are stored in data/bin folder by default, although the location can be changed by –dbpath option.
MongoDB 有一组自己的命令,可在 MongoDB shell 中使用。要调用 shell,请使用 Mongo 命令。
MongoDB has its own set of commands to be used in a MongoDB shell. To invoke shell, use Mongo command.
x:\mongodb\bin>mongo类似于 MySQL 或 SQLite shell 提示符的 shell 提示符在可以使用原生 NoSQL 命令之前出现。但是,我们有兴趣将 MongoDB 数据库连接到 Python。
A shell prompt similar to MySQL or SQLite shell prompt, appears before which native NoSQL commands can be executed. However, we are interested in connecting MongoDB database to Python.
PyMongo 模块是由 MongoDB Inc 本身开发的,用于提供 Python 编程接口。使用众所周知的 pip 实用程序来安装 PyMongo。
PyMongo module has been developed by MongoDB Inc itself to provide Python programming interface. Use well known pip utility to install PyMongo.
pip3 install pymongo假设 MongoDB 服务器已启动并正在运行(使用 mongod 命令),并正在监听端口 22017,我们首先需要声明一个 MongoClient 对象。它控制 Python 会话和数据库之间的所有事务。
Assuming that MongoDB server is up and running (with mongod command) and is listening at port 22017, we first need to declare a MongoClient object. It controls all transactions between Python session and the database.
from pymongo import MongoClient
client=MongoClient()使用此客户端对象与 MongoDB 服务器建立连接。
Use this client object to establish connection with MongoDB server.
client = MongoClient('localhost', 27017)使用以下命令创建新数据库。
A new database is created with following command.
db=client.newdbMongoDB 数据库可以有许多集合,类似于关系数据库中的表。集合对象由 Create_collection() 函数创建。
MongoDB database can have many collections, similar to tables in a relational database. A Collection object is created by Create_collection() function.
db.create_collection('students')现在,我们可以按如下方式在集合中添加一个或多个文档:-
Now, we can add one or more documents in the collection as follows −
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
db.create_collection("students")
student=db['students']
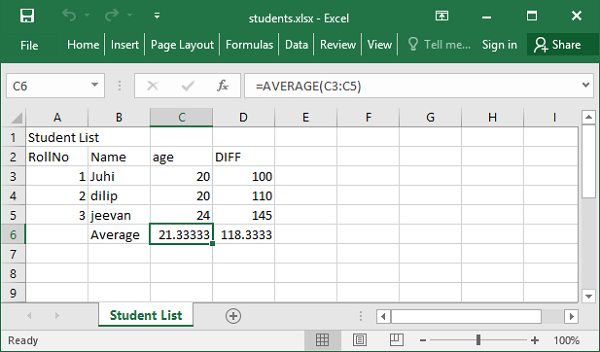
studentlist=[{'studentID':1,'Name':'Juhi','age':20, 'marks'=100},
{'studentID':2,'Name':'dilip','age':20, 'marks'=110},
{'studentID':3,'Name':'jeevan','age':24, 'marks'=145}]
student.insert_many(studentlist)
client.close()要检索文档(类似于 SELECT 查询),我们应当使用 find() 方法。它返回光标,它有助于获取所有文档。
To retrieve the documents (similar to SELECT query), we should use find() method. It returns a cursor with the help of which all documents can be obtained.
students=db['students']
docs=students.find()
for doc in docs:
print (doc['Name'], doc['age'], doc['marks'] )要在集合中查找特定文档而不是所有文档,我们需要对 find() 方法应用过滤器来查找。过滤器使用逻辑运算符。MongoDB 有一套自己的逻辑运算符,如下所示 −
To find a particular document instead of all of them in a collection, we need to apply filter to find() method. The filter uses logical operators. MongoDB has its own set of logical operators as below −
Sr.No |
MongoDB operator & Traditional logical operator |
1 |
$eq equal to (==) |
2 |
$gt greater than (>) |
3 |
$gte greater than or equal to (>=) |
4 |
$in if equal to any value in array |
5 |
$lt less than (<) |
6 |
$lte less than or equal to (⇐) |
7 |
$ne not equal to (!=) |
8 |
$nin if not equal to any value in array |
例如,我们有兴趣获取大于 21 岁的学生列表。在 find() 方法的过滤器中使用 $gt 运算符,如下所示 −
For example, we are interested in obtaining list of students older than 21 years. Using $gt operator in the filter for find() method as follows −
students=db['students']
docs=students.find({'age':{'$gt':21}})
for doc in docs:
print (doc.get('Name'), doc.get('age'), doc.get('marks'))PyMongo 模块提供 update_one() 和 update_many() 方法,以修改一个文档或多个满足特定过滤器表达式的文档。
PyMongo module provides update_one() and update_many() methods for modifying one document or more than one documents satisfying a specific filter expression.
让我们更新名为 Juhi 的文档的 marks 属性。
Let us update marks attribute of a document in which name is Juhi.
from pymongo import MongoClient
client=MongoClient()
db=client.newdb
doc=db.students.find_one({'Name': 'Juhi'})
db['students'].update_one({'Name': 'Juhi'},{"$set":{'marks':150}})
client.close()Python Data Persistence - Cassandra Driver
Cassandra 是另一个流行的 NoSQL 数据库。高可伸缩性、一致性和容错性 - 这些是 Cassandra 的一些重要特性。这是一个 Column store 数据库。数据存储在许多商品服务器上。因此,数据具有高可用性。
Cassandra is another popular NoSQL database. High scalability, consistency, and fault-tolerance - these are some of the important features of Cassandra. This is Column store database. The data is stored across many commodity servers. As a result, data highly available.
Cassandra 是 Apache Software foundation 的一个产品。数据以分布式方式存储在多个节点上。每个节点是一个由键空间组成的单一服务器。Cassandra 数据库的基本构建块是 keyspace ,它可以被认为类似于一个数据库。
Cassandra is a product from Apache Software foundation. Data is stored in distributed manner across multiple nodes. Each node is a single server consisting of keyspaces. Fundamental building block of Cassandra database is keyspace which can be considered analogous to a database.
Cassandra 中一个节点中的数据在节点的对等网络中复制到其他节点。这使 Cassandra 成为一个万无一失的数据库。该网络称为数据中心。多个数据中心可以互连形成集群。复制的性质通过在创建键空间时设置复制策略和复制因子来配置。
Data in one node of Cassandra, is replicated in other nodes over a peer-to-peer network of nodes. That makes Cassandra a foolproof database. The network is called a data center. Multiple data centers may be interconnected to form a cluster. Nature of replication is configured by setting Replication strategy and replication factor at the time of the creation of a keyspace.
一个键空间可以有多个列族 - 就像一个数据库可以包含多个表一样。Cassandra 的键空间没有预定义的模式。Cassandra 表中的每一行可能具有名称不同且数量可变的列。
One keyspace may have more than one Column families – just as one database may contain multiple tables. Cassandra’s keyspace doesn’t have a predefined schema. It is possible that each row in a Cassandra table may have columns with different names and in variable numbers.

Cassandra 软件也有两个版本:社区版和企业版。可在 https://cassandra.apache.org/download/ 下载最新版本的 Cassandra 企业版。
Cassandra software is also available in two versions: community and enterprise. The latest enterprise version of Cassandra is available for download at https://cassandra.apache.org/download/.
Cassandra 拥有自己的查询语言,称为 Cassandra Query Language (CQL) 。CQL 查询可以从 CQLASH shell 中执行,类似于 MySQL 或 SQLite shell。CQL 语法看起来类似于标准 SQL。
Cassandra has its own query language called Cassandra Query Language (CQL). CQL queries can be executed from inside a CQLASH shell – similar to MySQL or SQLite shell. The CQL syntax appears similar to standard SQL.
Datastax 社区版还附带了 Develcenter IDE,如下图所示:
The Datastax community edition, also comes with a Develcenter IDE shown in following figure −

用于处理 Cassandra 数据库的 Python 模块称为 Cassandra Driver 。它也是由 Apache 基金会开发的。此模块包含一个 ORM API,以及一个本质上类似于关系数据库的 DB-API 的核心 API。
Python module for working with Cassandra database is called Cassandra Driver. It is also developed by Apache foundation. This module contains an ORM API, as well as a core API similar in nature to DB-API for relational databases.
Cassandra 驱动程序的安装使用 pip utility 轻松完成。
Installation of Cassandra driver is easily done using pip utility.
pip3 install cassandra-driver与 Cassandra 数据库的交互通过 Cluster 对象完成。Cassandra.cluster 模块定义了 Cluster 类。我们首先需要声明 Cluster 对象。
Interaction with Cassandra database, is done through Cluster object. Cassandra.cluster module defines Cluster class. We first need to declare Cluster object.
from cassandra.cluster import Cluster
clstr=Cluster()所有事务(例如插入/更新等)通过使用密钥空间启动会话来执行。
All transactions such as insert/update, etc., are performed by starting a session with a keyspace.
session=clstr.connect()要创建新的密钥空间,请使用会话对象的 execute() 方法。execute() 方法采用一个字符串参数,它必须是查询字符串。CQL 具有 CREATE KEYSPACE 语句,如下所示。完整代码如下:
To create a new keyspace, use execute() method of session object. The execute() method takes a string argument which must be a query string. The CQL has CREATE KEYSPACE statement as follows. The complete code is as below −
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”此处, SimpleStrategy 是 replication strategy 的值, replication factor 设置为 3。如前所述,密钥空间包含一个或多个表。每个表都由其数据类型来表征。Python 数据类型根据下表自动解析为相应的 CQL 数据类型:
Here, SimpleStrategy is a value for replication strategy and replication factor is set to 3. As mentioned earlier, a keyspace contains one or more tables. Each table is characterized by it data type. Python data types are automatically parsed with corresponding CQL data types according to following table −
Python Type |
CQL Type |
None |
NULL |
Bool |
Boolean |
Float |
float, double |
int, long |
int, bigint, varint, smallint, tinyint, counter |
decimal.Decimal |
Decimal |
str, Unicode |
ascii, varchar, text |
buffer, bytearray |
Blob |
Date |
Date |
Datetime |
Timestamp |
Time |
Time |
list, tuple, generator |
List |
set, frozenset |
Set |
dict, OrderedDict |
Map |
uuid.UUID |
timeuuid, uuid |
要创建表,请使用会话对象执行 CQL 查询来创建表。
To create a table, use session object to execute CQL query for creating a table.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)由此创建的密钥空间可以进一步用于插入行。INSERT 查询的 CQL 版本类似于 SQL Insert 语句。以下代码在 students 表中插入一行。
The keyspace so created can be further used to insert rows. The CQL version of INSERT query is similar to SQL Insert statement. Following code inserts a row in students table.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"正如你所期望的,Cassandra 也使用了 SELECT 语句。如果 execute() 方法包含 SELECT 查询字符串,它将返回一个结果集对象,该对象可以使用循环来遍历。
As you would expect, SELECT statement is also used with Cassandra. In case of execute() method containing SELECT query string, it returns a result set object which can be traversed using a loop.
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))Cassandra 的 SELECT 查询支持使用 WHERE 子句对要获取的结果集应用筛选器。识别诸如 <、> == 等传统逻辑运算符。要仅从 students 表中检索年龄大于 20 的名称的那些行,execute() 方法中的查询字符串应如下所示:
Cassandra’s SELECT query supports use of WHERE clause to apply filter on result set to be fetched. Traditional logical operators like <, > == etc. are recognized. To retrieve, only those rows from students table for names with age>20, the query string in execute() method should be as follows −
rows=session.execute("select * from students WHERE age>20 allow filtering;")请注意,使用 ALLOW FILTERING 。此语句的 ALLOW FILTERING 部分允许明确允许(某些)需要筛选的查询。
Note, the use of ALLOW FILTERING. The ALLOW FILTERING part of this statement allows to explicitly allow (some) queries that require filtering.
Cassandra 驱动程序 API 在其 cassendra.query 模块中定义了以下 Statement 类型的类:
Cassandra driver API defines following classes of Statement type in its cassendra.query module.
SimpleStatement
一个包含在查询字符串中的简单、未准备的 CQL 查询。以上所有示例都是 SimpleStatement 的示例。
A simple, unprepared CQL query contained in a query string. All examples above are examples of SimpleStatement.
BatchStatement
将多个查询(例如 INSERT、UPDATE 和 DELETE)放入一个批处理中并一次执行。每行首先转换为 SimpleStatement,然后添加到批处理中。
Multiple queries (such as INSERT, UPDATE, and DELETE) are put in a batch and executed at once. Each row is first converted as a SimpleStatement and then added in a batch.
让我们将要添加到 Students 表中的行放入如下所示的元组列表形式:
Let us put rows to be added in Students table in the form of list of tuples as follows −
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]要使用 BathStatement 添加上述行,请运行以下脚本:
To add above rows using BathStatement, run following script −
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)PreparedStatement
准备好的语句就像 DB-API 中的参数化查询。Cassandra 会保存其查询字符串以供日后使用。Session.prepare() 方法会返回 PreparedStatement 实例。
Prepared statement is like a parameterized query in DB-API. Its query string is saved by Cassandra for later use. The Session.prepare() method returns a PreparedStatement instance.
对于我们的学生表,INSERT 查询的 PreparedStatement 如下所示 −
For our students table, a PreparedStatement for INSERT query is as follows −
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")随后,它只需要发送要绑定的参数值。例如 −
Subsequently, it only needs to send the values of parameters to bind. For example −
qry=stmt.bind([1,'Ram', 23,175])最后,执行上面绑定的语句。
Finally, execute the bound statement above.
session.execute(qry)这样能减少网络流量和 CPU 利用率,因为 Cassandra 不必每次都重新解析查询。
This reduces network traffic and CPU utilization because Cassandra does not have to re-parse the query each time.
Data Persistence - ZODB
ZODB ( Zope object Database ) 是一个用于存储 Python 对象的数据库。它是 ACID 兼容的——在 NOSQL 数据库中找不到此特性。ZODB 也是开源的,像许多 NoSQL 数据库一样,横向可伸缩且无模式。然而,它不分布式,也没有提供简单的复制。它为 Python 对象提供了持久性机制。它属于 Zope 应用程序服务器的一部分,但也可以独立使用。
ZODB (Zope object Database) is database for storing Python objects. It is ACID compliant - feature not found in NOSQL databases. The ZODB is also open source, horizontally scalable and schema-free, like many NoSQL databases. However, it is not distributed and does not offer easy replication. It provides persistence mechanism for Python objects. It is a part of Zope Application server, but can also be independently used.
ZODB 由 Zope Corporation 的 Jim Fulton 创建。它最初只是一个简单的持久对象系统。其当前版本是 5.5.0,是用 Python 完全编写的,使用 Python 内置对象持久性(pickle)的扩展版本。
ZODB was created by Jim Fulton of Zope Corporation. It started as simple Persistent Object System. Its current version is 5.5.0 and is written completely in Python. using an extended version of Python’s built-in object persistence (pickle).
ZODB 的一些主要特性包括:
Some of the main features of ZODB are −
-
transactions
-
history/undo
-
transparently pluggable storage
-
built-in caching
-
multiversion concurrency control (MVCC)
-
scalability across a network
ZODB 是一个 hierarchical 数据库。有一个根对象,在创建数据库时初始化。根对象像 Python 字典一样使用,它可以包含其他对象(这些对象本身也可以像字典)。将一个对象存储在数据库中,只需将其分配给容器中一个新的键即可。
The ZODB is a hierarchical database. There is a root object, initialized when a database is created. The root object is used like a Python dictionary and it can contain other objects (which can be dictionary-like themselves). To store an object in the database, it’s enough to assign it to a new key inside its container.
ZODB 对于数据分层并且可能存在比写入更多的读取的应用程序很有用。ZODB 是 pickle 对象的拓展。这就是为什么它只能通过 Python 脚本处理。
ZODB is useful for applications where data is hierarchical and there are likely to be more reads than writes. ZODB is an extension of pickle object. That’s why it can be processed through Python script only.
要安装 ZODB 的最新版本,我们可以使用 pip 实用程序:
To install latest version of ZODB let use pip utility −
pip install zodb以下依赖项也将被安装:
Following dependencies are also installed −
-
BTrees==4.6.1
-
cffi==1.13.2
-
persistent==4.5.1
-
pycparser==2.19
-
six==1.13.0
-
transaction==2.4.0
ZODB 提供以下存储选项:
ZODB provides following storage options −
FileStorage
这是默认值。所有内容存储在一个大型 Data.fs 文件中,它本质上是一个事务日志。
This is the default. Everything stored in one big Data.fs file, which is essentially a transaction log.
DirectoryStorage
这为每个对象修订版存储一个文件。在这种情况下,它不需要在非正常关闭时重建 Data.fs.index。
This stores one file per object revision. In this case, it does not require the Data.fs.index to be rebuilt on an unclean shutdown.
RelStorage
这将 pickle 存储在关系数据库中。PostgreSQL、MySQL 和 Oracle 均受支持。
This stores pickles in a relational database. PostgreSQL, MySQL and Oracle are supported.
要创建 ZODB 数据库,我们需要一个存储、一个数据库和最终一个连接。
To create ZODB database we need a storage, a database and finally a connection.
第一步是拥有一个存储对象。
First step is to have storage object.
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('mydata.fs')DB 类使用这个存储对象获取数据库对象。
DB class uses this storage object to obtain database object.
db = ZODB.DB(storage)向 DB 构造函数传递 None 创建一个内存数据库。
Pass None to DB constructor to create in-memory database.
Db=ZODB.DB(None)最后,我们与数据库建立连接。
Finally, we establish connection with the database.
conn=db.open()然后,连接对象允许你通过“root()”方法访问数据库的“根”。“根”对象是保存所有持久性对象的字典。
The connection object then gives you access to the ‘root’ of the database with the ‘root()’ method. The ‘root’ object is the dictionary that holds all of your persistent objects.
root = conn.root()例如,我们这样向根对象添加一个学生列表:
For example, we add a list of students to the root object as follows −
root['students'] = ['Mary', 'Maya', 'Meet']更改没有持久性储存到数据库中,直至我们提交交易。
This change is not permanently saved in the database till we commit the transaction.
import transaction
transaction.commit()要储存对象的用户定义类,该类必须继承自持久性父类的 Persistent。
To store object of a user defined class, the class must be inherited from persistent.Persistent parent class.
Advantages of Subclassing
Persistent 类的子类的优点如下:
Subclassing Persistent class has its advantages as follows −
-
The database will automatically track object changes made by setting attributes.
-
Data will be saved in its own database record.
-
You can save data that doesn’t subclass Persistent, but it will be stored in the database record of whatever persistent object references it. Non-persistent objects are owned by their containing persistent object and if multiple persistent objects refer to the same non-persistent subobject, they’ll get their own copies.
这里使用将 Student 类定义为 Persistent 类的子类:
Let use define a student class subclassing Persistent class as under −
import persistent
class student(persistent.Persistent):
def __init__(self, name):
self.name = name
def __repr__(self):
return str(self.name)要添加此类的对象,让我们首先像上面描述的那样设置连接。
To add object of this class, let us first set up the connection as described above.
import ZODB, ZODB.FileStorage
storage = ZODB.FileStorage.FileStorage('studentdata.fs')
db = ZODB.DB(storage)
conn=db.open()
root = conn.root()声明对象,然后将其添加到根,再提交交易
Declare object an add to root and then commit the transaction
s1=student("Akash")
root['s1']=s1
import transaction
transaction.commit()
conn.close()存储在根中的所有对象的列表都可以作为视图对象通过 items() 方法检索,因为根对象类似于内置字典。
List of all objects added to root can be retrieved as a view object with the help of items() method since root object is similar to built in dictionary.
print (root.items())
ItemsView({'s1': Akash})要从根中获取特定对象属性:
To fetch attribute of specific object from root,
print (root['s1'].name)
Akash该对象可以很容易地更新。由于 ZODB API 是纯 Python 包,因此不需要使用任何外部 SQL 类型语言。
The object can be easily updated. Since the ZODB API is a pure Python package, it doesn’t require any external SQL type language to be used.
root['s1'].name='Abhishek'
import transaction
transaction.commit()数据库将立即更新。请注意,事务类还定义了 abort() 函数,该函数类似于 SQL 中的 rollback() 事务控制。
The database will be updated instantly. Note that transaction class also defines abort() function which is similar to rollback() transaction control in SQL.
Data Persistence - Openpyxl Module
Microsoft 的 Excel 是最流行的电子表格应用程序。它已使用超过 25 年。Excel 的更高版本使用 *Office 开放 XML *(OOXML)文件格式。因此,可以通过其他编程环境访问电子表格文件。
Microsoft’s Excel is the most popular spreadsheet application. It has been in use since last more than 25 years. Later versions of Excel use *Office Open XML *(OOXML) file format. Hence, it has been possible to access spreadsheet files through other programming environments.
OOXML 是 ECMA 标准文件格式。Python 的 openpyxl 包提供读取/写入扩展名为 .xlsx 的 Excel 文件的功能。
OOXML is an ECMA standard file format. Python’s openpyxl package provides functionality to read/write Excel files with .xlsx extension.
openpyxl 包使用的类名称与 Microsoft Excel 术语类似。Excel 文档称为工作簿,并以 .xlsx 扩展名保存在文件系统中。工作簿可能有多个工作表。工作表显示一个大网格单元,它们中的每一个都可以存储值或公式。形成网格的行和列已编号。列由字母、A、B、C、…、Z、AA、AB 等标识。行从 1 开始编号。
The openpyxl package uses class nomenclature that is similar to Microsoft Excel terminology. An Excel document is called as workbook and is saved with .xlsx extension in the file system. A workbook may have multiple worksheets. A worksheet presents a large grid of cells, each one of them can store either value or formula. Rows and columns that form the grid are numbered. Columns are identified by alphabets, A, B, C, …., Z, AA, AB, and so on. Rows are numbered starting from 1.
一个典型的 Excel 工作表如下所示 −
A typical Excel worksheet appears as follows −
pip 实用程序足以安装 openpyxl 包。
The pip utility is good enough to install openpyxl package.
pip install openpyxlWorkbook 类表示带有空工作表的一个空工作簿。我们需要激活它,以便向工作表中添加一些数据。
The Workbook class represents an empty workbook with one blank worksheet. We need to activate it so that some data can be added to the worksheet.
from openpyxl import Workbook
wb=Workbook()
sheet1=wb.active
sheet1.title='StudentList'众所周知,工作表中的单元格被命名为 ColumnNameRownumber 格式。相应地,左上角的单元格为 A1。我们将一个字符串分配给这个单元格,如下所示 −
As we know, a cell in worksheet is named as ColumnNameRownumber format. Accordingly, top left cell is A1. We assign a string to this cell as −
sheet1['A1']= 'Student List'或者,使用工作表的 cell() 方法,它使用行号和列号来标识单元格。调用单元格对象的 value 属性以分配一个值。
Alternately, use worksheet’s cell() method which uses row and column number to identify a cell. Call value property to cell object to assign a value.
cell1=sheet1.cell(row=1, column=1)
cell1.value='Student List'在用数据填充工作表后,通过调用工作簿对象的 save() 方法保存工作簿。
After populating worksheet with data, the workbook is saved by calling save() method of workbook object.
wb.save('Student.xlsx')该工作簿文件创建在当前工作目录中。
This workbook file is created in current working directory.
以下 Python 脚本将一个元组列表写入到工作簿文档中。每个元组都存储了学号、年龄和学生的成绩。
Following Python script writes a list of tuples into a workbook document. Each tuple stores roll number, age and marks of student.
from openpyxl import Workbook
wb = Workbook()
sheet1 = wb.active
sheet1.title='Student List'
sheet1.cell(column=1, row=1).value='Student List'
studentlist=[('RollNo','Name', 'age', 'marks'),(1,'Juhi',20,100),
(2,'dilip',20, 110) , (3,'jeevan',24,145)]
for col in range(1,5):
for row in range(1,5):
sheet1.cell(column=col, row=1+row).value=studentlist[row-1][col-1]
wb.save('students.xlsx')工作簿 students.xlsx 保存于当前工作目录中。如果使用 Excel 应用程序打开它,它将如下图所示−
The workbook students.xlsx is saved in current working directory. If opened using Excel application, it appears as below −
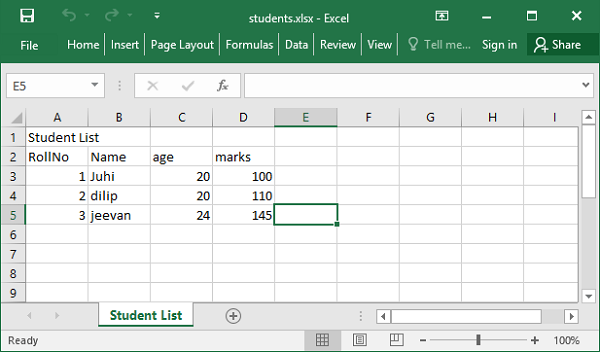
openpyxl 模块提供了 load_workbook() 函数,用于帮助在工作簿文档中读取数据。
The openpyxl module offers load_workbook() function that helps in reading back data in the workbook document.
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')现在,您可以通过行号和列号访问任何单元格的值。
You can now access value of any cell specified by row and column number.
cell1=sheet1.cell(row=1, column=1)
print (cell1.value)
Student ListExample
以下代码通过表格数据填充一个列表。
Following code populates a list with work sheet data.
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
studentlist=[]
for row in range(1,5):
stud=[]
for col in range(1,5):
val=sheet1.cell(column=col, row=1+row).value
stud.append(val)
studentlist.append(tuple(stud))
print (studentlist)Output
[('RollNo', 'Name', 'age', 'marks'), (1, 'Juhi', 20, 100), (2, 'dilip', 20, 110), (3, 'jeevan', 24, 145)]Excel 应用程序的一个非常重要的特性是公式。要向单元格分配公式,请将它分配给一个包含 Excel 公式语法的字符串。将 AVERAGE 函数分配给 c6 单元格,其中包含年龄。
One very important feature of Excel application is the formula. To assign formula to a cell, assign it to a string containing Excel’s formula syntax. Assign AVERAGE function to c6 cell having age.
sheet1['C6']= 'AVERAGE(C3:C5)'Openpyxl 模块具有 Translate_formula() 函数,可以将公式复制到一个范围内。以下程序在 C6 中定义了 AVERAGE 函数,并将其复制到 C7,计算平均成绩。
Openpyxl module has Translate_formula() function to copy the formula across a range. Following program defines AVERAGE function in C6 and copies it to C7 that calculates average of marks.
from openpyxl import load_workbook
wb=load_workbook('students.xlsx')
sheet1 = wb['Student List']
from openpyxl.formula.translate import Translator#copy formula
sheet1['B6']='Average'
sheet1['C6']='=AVERAGE(C3:C5)'
sheet1['D6'] = Translator('=AVERAGE(C3:C5)', origin="C6").translate_formula("D6")
wb.save('students.xlsx')更改后的工作表现在如下所示−
The changed worksheet now appears as follows −