Mongodb 简明教程
MongoDB - Data Modelling
MongoDB 中的数据具有一定的灵活性模式。同一集合中的文档。它们无需具有相同的字段集或结构。集合中的通用字段可包含不同类型的数据。
Data in MongoDB has a flexible schema.documents in the same collection. They do not need to have the same set of fields or structure Common fields in a collection’s documents may hold different types of data.
Data Model Design
MongoDB 提供两种类型的数据模型:嵌入式数据模型和规范化数据模型。根据需求,在准备文档时可以使用任意一种模型。
MongoDB provides two types of data models: — Embedded data model and Normalized data model. Based on the requirement, you can use either of the models while preparing your document.
Embedded Data Model
在这个模型中,可以将所有相关数据(嵌入)到单个文档中,它也称为非规范化数据模型。
In this model, you can have (embed) all the related data in a single document, it is also known as de-normalized data model.
例如,假设我们要在三个不同的文档中获取员工的详细信息,即 Personal_details、Contact 和 Address,可以将这三个文档嵌入到一个文档中,如下所示:
For example, assume we are getting the details of employees in three different documents namely, Personal_details, Contact and, Address, you can embed all the three documents in a single one as shown below −
{
_id: ,
Emp_ID: "10025AE336"
Personal_details:{
First_Name: "Radhika",
Last_Name: "Sharma",
Date_Of_Birth: "1995-09-26"
},
Contact: {
e-mail: "radhika_sharma.123@gmail.com",
phone: "9848022338"
},
Address: {
city: "Hyderabad",
Area: "Madapur",
State: "Telangana"
}
}Normalized Data Model
在此模型中,可以使用引用来引用原始文档中的子文档。例如,可以按规范化模型的方式重新书写上面的文档:
In this model, you can refer the sub documents in the original document, using references. For example, you can re-write the above document in the normalized model as:
Employee:
Employee:
{
_id: <ObjectId101>,
Emp_ID: "10025AE336"
}Personal_details:
Personal_details:
{
_id: <ObjectId102>,
empDocID: " ObjectId101",
First_Name: "Radhika",
Last_Name: "Sharma",
Date_Of_Birth: "1995-09-26"
}Contact:
Contact:
{
_id: <ObjectId103>,
empDocID: " ObjectId101",
e-mail: "radhika_sharma.123@gmail.com",
phone: "9848022338"
}Address:
Address:
{
_id: <ObjectId104>,
empDocID: " ObjectId101",
city: "Hyderabad",
Area: "Madapur",
State: "Telangana"
}Considerations while designing Schema in MongoDB
-
Design your schema according to user requirements.
-
Combine objects into one document if you will use them together. Otherwise separate them (but make sure there should not be need of joins).
-
Duplicate the data (but limited) because disk space is cheap as compare to compute time.
-
Do joins while write, not on read.
-
Optimize your schema for most frequent use cases.
-
Do complex aggregation in the schema.
Example
假设一个客户需要一个数据库设计,用于他的博客/网站,并查看 RDBMS 和 MongoDB 架构设计之间的区别。该网站有以下要求。
Suppose a client needs a database design for his blog/website and see the differences between RDBMS and MongoDB schema design. Website has the following requirements.
-
Every post has the unique title, description and url.
-
Every post can have one or more tags.
-
Every post has the name of its publisher and total number of likes.
-
Every post has comments given by users along with their name, message, data-time and likes.
-
On each post, there can be zero or more comments.
在 RDBMS 架构中,上述要求的设计将至少有三个表。
In RDBMS schema, design for above requirements will have minimum three tables.
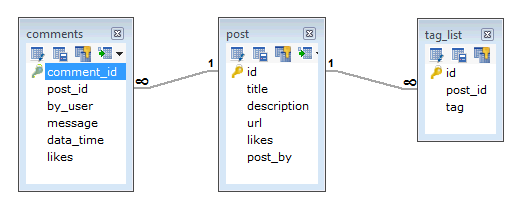
而在 MongoDB 架构中,设计将有一个集合类和以下结构 −
While in MongoDB schema, design will have one collection post and the following structure −
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}因此在显示数据时,在 RDBMS 中你需要连接三个表,而在 MongoDB 中,数据只将从一个集合中显示。
So while showing the data, in RDBMS you need to join three tables and in MongoDB, data will be shown from one collection only.