FAQ
How does SDN relate to Neo4j-OGM?
Neo4j-OGM 是一个对象图形映射库,Spring Data Neo4j 的早期版本主要使用它作为其后端,用于将节点和关系映射到域对象。当前的 SDN does not need 和 does not support Neo4j-OGM.SDN 专门使用 Spring Data 的映射上下文来扫描类和构建元模型。
Neo4j-OGM is an Object Graph Mapping library, which is mainly used by previous versions of Spring Data Neo4j as its backend for the heavy lifting of mapping nodes and relationships into domain object. The current SDN does not need and does not support Neo4j-OGM. SDN uses Spring Data’s mapping context exclusively for scanning classes and building the meta model.
虽然这样将 SDN 固定在了 Spring 生态系统中,但是它有几个优势,其中包括更小的 CPU 和内存使用量方面的占用空间,特别是 Spring 的映射上下文中所有功能。
While this pins SDN to the Spring ecosystem, it has several advantages, among them the smaller footprint regarding CPU and memory usage and especially, all the features of Spring’s mapping context.
Why should I use SDN in favor of SDN+OGM
SDN 有 SDN+OGM 中不存在的几个功能,尤其是
SDN has several features not present in SDN+OGM, notably
-
Full support for Springs reactive story, including reactive transaction
-
Full support for Query By Example
-
Full support for fully immutable entities
-
Support for all modifiers and variations of derived finder methods, including spatial queries
Does SDN support embedded Neo4j?
嵌入式 Neo4j 具有多个方面:
Embedded Neo4j has multiple facets to it:
Does SDN interact directly with an embedded instance?
否。嵌入式数据库通常由 org.neo4j.graphdb.GraphDatabaseService 的实例表示,并且没有现成的 Bolt 连接器。
No.
An embedded database is usually represented by an instance of org.neo4j.graphdb.GraphDatabaseService and has no Bolt connector out of the box.
然而,SDN 可以与 Neo4j 的测试框架很好地配合使用,该测试框架专门旨在作为真实数据库的直接替代品。通过 the Spring Boot starter for the driver 实现了对 Neo4j 3.5、4.x 和 5.x 测试框架的支持。查看对应的模块 org.neo4j.driver:neo4j-java-driver-test-harness-spring-boot-autoconfigure。
SDN can however work very much with Neo4j’s test harness, the test harness is specially meant to be a drop-in replacement for the real database.
Support for Neo4j 3.5, 4.x and 5.x test harness is implemented via the Spring Boot starter for the driver.
Have a look at the corresponding module org.neo4j.driver:neo4j-java-driver-test-harness-spring-boot-autoconfigure.
Which Neo4j Java Driver can be used and how?
SDN 依赖于 Neo4j Java 驱动程序。每个 SDN 版本都使用在发布时与最新 Neo4j 兼容的 Neo4j Java 驱动程序版本。虽然 Neo4j Java 驱动程序的修补程序版本通常可以直接代换,但是,SDN 确保即使是较低版本也可以互换,因为它会在需要时检查是否存在方法或接口更改。
SDN relies on the Neo4j Java Driver. Each SDN release uses a Neo4j Java Driver version compatible with the latest Neo4j available at the time of its release. While patch versions of the Neo4j Java Driver are usually drop-in replacements, SDN makes sure that even minor versions are interchangeable as it checks for the presence or absence of methods or interface changes if necessary.
因此,你可以将任何 4.x Neo4j Java 驱动程序与任何 SDN 6.x 版本一起使用,并将任何 5.x Neo4j 驱动程序与任何 SDN 7.x 版本一起使用。
Therefore, you are able to use any 4.x Neo4j Java Driver with any SDN 6.x version, and any 5.x Neo4j Driver with any SDN 7.x version.
With Spring Boot
现在,Spring boot 部署是基于 Spring Data 的应用程序最可能的部署。请使用 Spring Boots 依赖关系管理来更改驱动程序版本,如下所示:
These days, a Spring boot deployment is the most likely deployment of a Spring Data based applications. Please use Spring Boots dependency management to change the driver version like this:
<properties>
<neo4j-java-driver.version>5.4.0</neo4j-java-driver.version>
</properties>或
Or
neo4j-java-driver.version = 5.4.0Without Spring Boot
如果没有 Spring Boot,你只需手动声明依赖关系。对于 Maven,我们建议使用 <dependencyManagement /> 部分,如下所示:
Without Spring Boot, you would just manually declare the dependency. For Maven, we recommend using the <dependencyManagement />
section like this:
<dependencyManagement>
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>5.4.0</version>
</dependency>
</dependencyManagement>
Neo4j 4 supports multiple databases - How can I use them?
您可以静态配置数据库名称或运行您自己的数据库名称提供程序。请记住,SDN 不会为您创建数据库。您可以借助 migrations tool 或当然也可以直接使用简单脚本来执行此操作。
You can either statically configure the database name or run your own database name provider. Bear in mind that SDN will not create the databases for you. You can do this with the help of a migrations tool or of course with a simple script upfront.
Statically configured
在你的 Spring Boot 配置中配置要使用的数据库名称,如下所示(对于基于 YML 或环境的配置,当然也适用相同的属性,只要应用 Spring Boot 的约定即可):
Configure the database name to use in your Spring Boot configuration like this (the same property applies of course for YML or environment based configuration, with Spring Boot’s conventions applied):
spring.data.neo4j.database = yourDatabase有了此配置,SDN 存储库的所有实例(响应式的和命令式的)以及 ReactiveNeo4jTemplate 和 Neo4jTemplate 生成的所有查询都将在数据库 yourDatabase 中执行。
With that configuration in place, all queries generated by all instances of SDN repositories (both reactive and imperative) and by the ReactiveNeo4jTemplate respectively Neo4jTemplate will be executed against the database yourDatabase.
Dynamically configured
根据你的 Spring 应用程序类型提供类型为 Neo4jDatabaseNameProvider 或 ReactiveDatabaseSelectionProvider 的 bean。
Provide a bean with the type Neo4jDatabaseNameProvider or ReactiveDatabaseSelectionProvider depending on the type of your Spring application.
例如,该 bean 可以使用 Spring 的安全上下文来检索租户。下面是使用 Spring Security 保护的命令式应用程序的工作示例:
That bean could use for example Spring’s security context to retrieve a tenant. Here is a working example for an imperative application secured with Spring Security:
import org.neo4j.springframework.data.core.DatabaseSelection;
import org.neo4j.springframework.data.core.DatabaseSelectionProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.core.Authentication;
import org.springframework.security.core.context.SecurityContext;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.security.core.userdetails.User;
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/Neo4jConfig.java[]|
小心不要将从一个数据库检索的实体与另一个数据库混淆。数据库名称对每个新事务都是必需的,因此在调用过程中更改数据库名称时,您最终获取的实体可能比预期少或多。或更糟糕的是,您不可避免地会将错误的实体存储在错误的数据库中。 |
|
Be careful that you don’t mix up entities retrieved from one database with another database. The database name is requested for each new transaction, so you might end up with less or more entities than expected when changing the database name in between calls. Or worse, you could inevitably store the wrong entities in the wrong database. |
The Spring Boot Neo4j health indicator targets the default database, how can I change that?
Spring Boot 同时提供命令式和响应式 Neo4j health indicators.。两种变体都能够检测应用程序上下文中 org.neo4j.driver.Driver 的多重 bean,并为每个实例提供对整体运行状况的贡献。不过,Neo4j 驱动程序连接到服务器,而不是该服务器内的特定数据库。Spring Boot 能够在没有 Spring Data Neo4j 的情况下配置驱动程序,并且由于有关使用哪个数据库的信息与 Spring Data Neo4j 绑定,因此内置运行状况指示器无法获取此信息。
Spring Boot comes with both imperative and reactive Neo4j health indicators.
Both variants are able to detect multiple beans of org.neo4j.driver.Driver inside the application context and provide
a contribution to the overall health for each instance.
The Neo4j driver however does connect to a server and not to a specific database inside that server.
Spring Boot is able to configure the driver without Spring Data Neo4j and as the information which database is to be used
is tied to Spring Data Neo4j, this information is not available to the built-in health indicator.
这在许多部署场景中很可能不是问题。但是,如果已配置的数据库用户没有至少对默认数据库的访问权限,则运行状况检查将失败。
This is most likely not a problem in many deployment scenarios. However, if configured database user does not have at least access rights to the default database, the health checks will fail.
可以通过了解数据库选择的自定义 Neo4j 运行状况贡献者来缓解此问题。
This can be mitigated by custom Neo4j health contributors that are aware of the database selection.
Imperative variant
import java.util.Optional;
import org.neo4j.driver.Driver;
import org.neo4j.driver.Result;
import org.neo4j.driver.SessionConfig;
import org.neo4j.driver.summary.DatabaseInfo;
import org.neo4j.driver.summary.ResultSummary;
import org.neo4j.driver.summary.ServerInfo;
import org.springframework.boot.actuate.health.AbstractHealthIndicator;
import org.springframework.boot.actuate.health.Health;
import org.springframework.data.neo4j.core.DatabaseSelection;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.util.StringUtils;
public class DatabaseSelectionAwareNeo4jHealthIndicator extends AbstractHealthIndicator {
private final Driver driver;
private final DatabaseSelectionProvider databaseSelectionProvider;
public DatabaseSelectionAwareNeo4jHealthIndicator(
Driver driver, DatabaseSelectionProvider databaseSelectionProvider
) {
this.driver = driver;
this.databaseSelectionProvider = databaseSelectionProvider;
}
@Override
protected void doHealthCheck(Health.Builder builder) {
try {
SessionConfig sessionConfig = Optional
.ofNullable(databaseSelectionProvider.getDatabaseSelection())
.filter(databaseSelection -> databaseSelection != DatabaseSelection.undecided())
.map(DatabaseSelection::getValue)
.map(v -> SessionConfig.builder().withDatabase(v).build())
.orElseGet(SessionConfig::defaultConfig);
class Tuple {
String edition;
ResultSummary resultSummary;
Tuple(String edition, ResultSummary resultSummary) {
this.edition = edition;
this.resultSummary = resultSummary;
}
}
String query =
"CALL dbms.components() YIELD name, edition WHERE name = 'Neo4j Kernel' RETURN edition";
Tuple health = driver.session(sessionConfig)
.writeTransaction(tx -> {
Result result = tx.run(query);
String edition = result.single().get("edition").asString();
return new Tuple(edition, result.consume());
});
addHealthDetails(builder, health.edition, health.resultSummary);
} catch (Exception ex) {
builder.down().withException(ex);
}
}
static void addHealthDetails(Health.Builder builder, String edition, ResultSummary resultSummary) {
ServerInfo serverInfo = resultSummary.server();
builder.up()
.withDetail(
"server", serverInfo.version() + "@" + serverInfo.address())
.withDetail("edition", edition);
DatabaseInfo databaseInfo = resultSummary.database();
if (StringUtils.hasText(databaseInfo.name())) {
builder.withDetail("database", databaseInfo.name());
}
}
}该方法使用可用数据库选择来运行 Boot 运行的同一查询以检查连接是否正常。使用以下配置来应用它:
This uses the available database selection to run the same query that Boot runs to check whether a connection is healthy or not. Use the following configuration to apply it:
import java.util.Map;
import org.neo4j.driver.Driver;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.boot.actuate.health.CompositeHealthContributor;
import org.springframework.boot.actuate.health.HealthContributor;
import org.springframework.boot.actuate.health.HealthContributorRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
@Configuration(proxyBeanMethods = false)
public class Neo4jHealthConfig {
@Bean (1)
DatabaseSelectionAwareNeo4jHealthIndicator databaseSelectionAwareNeo4jHealthIndicator(
Driver driver, DatabaseSelectionProvider databaseSelectionProvider
) {
return new DatabaseSelectionAwareNeo4jHealthIndicator(driver, databaseSelectionProvider);
}
@Bean (2)
HealthContributor neo4jHealthIndicator(
Map<String, DatabaseSelectionAwareNeo4jHealthIndicator> customNeo4jHealthIndicators) {
return CompositeHealthContributor.fromMap(customNeo4jHealthIndicators);
}
@Bean (3)
InitializingBean healthContributorRegistryCleaner(
HealthContributorRegistry healthContributorRegistry,
Map<String, DatabaseSelectionAwareNeo4jHealthIndicator> customNeo4jHealthIndicators
) {
return () -> customNeo4jHealthIndicators.keySet()
.stream()
.map(HealthContributorNameFactory.INSTANCE)
.forEach(healthContributorRegistry::unregisterContributor);
}
}| 1 | If you have multiple drivers and database selection providers, you would need to create one indicator per combination |
| 2 | This makes sure that all of those indicators are grouped under Neo4j, replacing the default Neo4j health indicator |
| 3 | This prevents the individual contributors showing up in the health endpoint directly |
Reactive variant
响应变体基本上是相同的,它使用响应类型和相应的响应基础设施类:
The reactive variant is basically the same, using reactive types and the corresponding reactive infrastructure classes:
import reactor.core.publisher.Mono;
import reactor.util.function.Tuple2;
import org.neo4j.driver.Driver;
import org.neo4j.driver.SessionConfig;
import org.neo4j.driver.reactivestreams.RxResult;
import org.neo4j.driver.reactivestreams.RxSession;
import org.neo4j.driver.summary.DatabaseInfo;
import org.neo4j.driver.summary.ResultSummary;
import org.neo4j.driver.summary.ServerInfo;
import org.reactivestreams.Publisher;
import org.springframework.boot.actuate.health.AbstractReactiveHealthIndicator;
import org.springframework.boot.actuate.health.Health;
import org.springframework.data.neo4j.core.DatabaseSelection;
import org.springframework.data.neo4j.core.ReactiveDatabaseSelectionProvider;
import org.springframework.util.StringUtils;
public final class DatabaseSelectionAwareNeo4jReactiveHealthIndicator
extends AbstractReactiveHealthIndicator {
private final Driver driver;
private final ReactiveDatabaseSelectionProvider databaseSelectionProvider;
public DatabaseSelectionAwareNeo4jReactiveHealthIndicator(
Driver driver,
ReactiveDatabaseSelectionProvider databaseSelectionProvider
) {
this.driver = driver;
this.databaseSelectionProvider = databaseSelectionProvider;
}
@Override
protected Mono<Health> doHealthCheck(Health.Builder builder) {
String query =
"CALL dbms.components() YIELD name, edition WHERE name = 'Neo4j Kernel' RETURN edition";
return databaseSelectionProvider.getDatabaseSelection()
.map(databaseSelection -> databaseSelection == DatabaseSelection.undecided() ?
SessionConfig.defaultConfig() :
SessionConfig.builder().withDatabase(databaseSelection.getValue()).build()
)
.flatMap(sessionConfig ->
Mono.usingWhen(
Mono.fromSupplier(() -> driver.rxSession(sessionConfig)),
s -> {
Publisher<Tuple2<String, ResultSummary>> f = s.readTransaction(tx -> {
RxResult result = tx.run(query);
return Mono.from(result.records())
.map((record) -> record.get("edition").asString())
.zipWhen((edition) -> Mono.from(result.consume()));
});
return Mono.fromDirect(f);
},
RxSession::close
)
).map((result) -> {
addHealthDetails(builder, result.getT1(), result.getT2());
return builder.build();
});
}
static void addHealthDetails(Health.Builder builder, String edition, ResultSummary resultSummary) {
ServerInfo serverInfo = resultSummary.server();
builder.up()
.withDetail(
"server", serverInfo.version() + "@" + serverInfo.address())
.withDetail("edition", edition);
DatabaseInfo databaseInfo = resultSummary.database();
if (StringUtils.hasText(databaseInfo.name())) {
builder.withDetail("database", databaseInfo.name());
}
}
}当然,还有响应配置变体。它需要两个不同的注册表清理程序,因为 Spring Boot 也将封装现有的响应指示器以便与非响应执行器端点一起使用。
And of course, the reactive variant of the configuration. It needs two different registry cleaners, as Spring Boot will wrap existing reactive indicators to be used with the non-reactive actuator endpoint, too.
import java.util.Map;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.boot.actuate.health.CompositeReactiveHealthContributor;
import org.springframework.boot.actuate.health.HealthContributorNameFactory;
import org.springframework.boot.actuate.health.HealthContributorRegistry;
import org.springframework.boot.actuate.health.ReactiveHealthContributor;
import org.springframework.boot.actuate.health.ReactiveHealthContributorRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration(proxyBeanMethods = false)
public class Neo4jHealthConfig {
@Bean
ReactiveHealthContributor neo4jHealthIndicator(
Map<String, DatabaseSelectionAwareNeo4jReactiveHealthIndicator> customNeo4jHealthIndicators) {
return CompositeReactiveHealthContributor.fromMap(customNeo4jHealthIndicators);
}
@Bean
InitializingBean healthContributorRegistryCleaner(HealthContributorRegistry healthContributorRegistry,
Map<String, DatabaseSelectionAwareNeo4jReactiveHealthIndicator> customNeo4jHealthIndicators) {
return () -> customNeo4jHealthIndicators.keySet()
.stream()
.map(HealthContributorNameFactory.INSTANCE)
.forEach(healthContributorRegistry::unregisterContributor);
}
@Bean
InitializingBean reactiveHealthContributorRegistryCleaner(
ReactiveHealthContributorRegistry healthContributorRegistry,
Map<String, DatabaseSelectionAwareNeo4jReactiveHealthIndicator> customNeo4jHealthIndicators) {
return () -> customNeo4jHealthIndicators.keySet()
.stream()
.map(HealthContributorNameFactory.INSTANCE)
.forEach(healthContributorRegistry::unregisterContributor);
}
}Neo4j 4.4+ supports impersonation of different users - How can I use them?
用户模拟在大型多租户设置中特别有用,其中一个物理连接(或技术)用户可以模拟多个租户。根据您的设置,这将显著减少所需的物理驱动程序实例数。
User impersonation is especially interesting in big multi-tenant settings, in which one physically connected (or technical) user can impersonate many tenants. Depending on your setup this will drastically reduce the number of physical driver instances needed.
此功能要求服务器端有 Neo4j Enterprise 4.4+,客户端有 4.4+ 驱动程序(org.neo4j.driver:neo4j-java-driver:4.4.0 或更高版本)。
The feature requires Neo4j Enterprise 4.4+ on the server side and a 4.4+ driver on the client side (org.neo4j.driver:neo4j-java-driver:4.4.0 or higher).
对于命令式和响应版本,您分别需要提供 UserSelectionProvider 或`ReactiveUserSelectionProvider`。需要将相同实例分别传递给 Neo4Client 和 Neo4jTransactionManager 或它们的响应变体。
For both imperative and reactive versions you need to provide a UserSelectionProvider respectively a ReactiveUserSelectionProvider.
The same instance needs to be passed along to the Neo4Client and Neo4jTransactionManager respectively their reactive variants.
在 [Bootless 命令式,bootless-imperative-configuration] 和 [响应,bootless-reactive-configuration] 配置中,您只需要提供该类型的 bean:
In bootless-imperative-configuration and bootless-reactive-configuration configurations you just need to provide a bean of the type in question:
import org.springframework.data.neo4j.core.UserSelection;
import org.springframework.data.neo4j.core.UserSelectionProvider;
public class CustomConfig {
@Bean
public UserSelectionProvider getUserSelectionProvider() {
return () -> UserSelection.impersonate("someUser");
}
}在典型的 Spring Boot 场景中,此功能需要更多工作,因为 Boot 也支持没有该功能的 SDN 版本。因此,鉴于 [faq.impersonation.userselectionbean] 中的 bean,您需要完全自定义客户端和事务管理器:
In a typical Spring Boot scenario this feature requires a bit more work, as Boot supports also SDN versions without that feature. So given the bean in [faq.impersonation.userselectionbean] you would need fully customize the client and transaction manager:
import org.neo4j.driver.Driver;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.data.neo4j.core.Neo4jClient;
import org.springframework.data.neo4j.core.UserSelectionProvider;
import org.springframework.data.neo4j.core.transaction.Neo4jTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
public class CustomConfig {
@Bean
public Neo4jClient neo4jClient(
Driver driver,
DatabaseSelectionProvider databaseSelectionProvider,
UserSelectionProvider userSelectionProvider
) {
return Neo4jClient.with(driver)
.withDatabaseSelectionProvider(databaseSelectionProvider)
.withUserSelectionProvider(userSelectionProvider)
.build();
}
@Bean
public PlatformTransactionManager transactionManager(
Driver driver,
DatabaseSelectionProvider databaseSelectionProvider,
UserSelectionProvider userSelectionProvider
) {
return Neo4jTransactionManager
.with(driver)
.withDatabaseSelectionProvider(databaseSelectionProvider)
.withUserSelectionProvider(userSelectionProvider)
.build();
}
}Using a Neo4j cluster instance from Spring Data Neo4j
以下问题适用于 Neo4j AuraDB 以及 Neo4j 本地群集实例。
The following questions apply to Neo4j AuraDB as well as to Neo4j on-premise cluster instances.
Do I need specific configuration so that transactions work seamless with a Neo4j Causal Cluster?
不,您不需要。SDN 在内部使用 Neo4j 因果群集书签,而无需您进行任何配置。同一线程或相同响应流中的事务将能够按照您的预期读取它们之前更改的值。
No, you don’t. SDN uses Neo4j Causal Cluster bookmarks internally without any configuration on your side required. Transactions in the same thread or the same reactive stream following each other will be able to read their previously changed values as you would expect.
Is it important to use read-only transactions for Neo4j cluster?
是的。Neo4j 群集架构是一种因果群集架构,它区分主服务器和辅助服务器。主服务器要么是单实例,要么是核心实例。它们都可以响应读写操作。写操作从核心实例传播到读取副本或更广泛地说是群集内的关注者。这些关注者是辅助服务器。辅助服务器不响应写操作。
Yes, it is. The Neo4j cluster architecture is a causal clustering architecture, and it distinguishes between primary and secondary servers. Primary server either are single instances or core instances. Both of them can answer to read and write operations. Write operations are propagated from the core instances to read replicas or more generally, followers, inside the cluster. Those followers are secondary servers. Secondary servers don’t answer to write operations.
在标准部署方案中,群集中将有一些核心实例和许多读取副本。因此,将操作或查询标记为只读非常重要,以便以这种方式扩展群集,使领导者永远不会过度,并且尽可能将查询传播到读取副本。
In a standard deployment scenario you’ll have some core instances and many read replicas inside a cluster. Therefore, it is important to mark operations or queries as read-only to scale your cluster in such a way that leaders are never overwhelmed and queries are propagated as much as possible to read replicas.
Spring Data Neo4j 和底层 Java 驱动程序都不会执行 Cypher 解析,并且这两个构建块在默认情况下都会假定写操作。此决策是为了开箱即用地支持所有操作。如果堆栈中的某个内容在默认情况下假定只读,则堆栈最终可能会将写查询发送到读取副本,并在执行它们时失败。
Neither Spring Data Neo4j nor the underlying Java driver do Cypher parsing and both building blocks assume write operations by default. This decision has been made to support all operations out of the box. If something in the stack would assume read-only by default, the stack might end up sending write queries to read replicas and fail on executing them.
|
默认情况下,所有 |
|
All |
下面介绍了一些选项:
Some options are described below:
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.transaction.annotation.Transactional;
@Transactional(readOnly = true)
interface PersonRepository extends Neo4jRepository<Person, Long> {
}import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
import org.springframework.transaction.annotation.Transactional;
interface PersonRepository extends Neo4jRepository<Person, Long> {
@Transactional(readOnly = true)
Person findOneByName(String name); (1)
@Transactional(readOnly = true)
@Query("""
CALL apoc.search.nodeAll('{Person: "name",Movie: ["title","tagline"]}','contains','her')
YIELD node AS n RETURN n""")
Person findByCustomQuery(); (2)
}| 1 | Why isn’t this read-only be default? While it would work for the derived finder above (which we actually know to be read-only),
we often have seen cases in which user add a custom @Query and implement it via a MERGE construct,
which of course is a write operation. |
| 2 | Custom procedures can do all kinds of things, there’s no way at the moment to check for read-only vs write here for us. |
import java.util.Optional;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.transaction.annotation.Transactional;
interface PersonRepository extends Neo4jRepository<Person, Long> {
}
interface MovieRepository extends Neo4jRepository<Movie, Long> {
List<Movie> findByLikedByPersonName(String name);
}
public class PersonService {
private final PersonRepository personRepository;
private final MovieRepository movieRepository;
public PersonService(PersonRepository personRepository,
MovieRepository movieRepository) {
this.personRepository = personRepository;
this.movieRepository = movieRepository;
}
@Transactional(readOnly = true)
public Optional<PersonDetails> getPerson(Long id) { (1)
return this.repository.findById(id)
.map(person -> {
var movies = this.movieRepository
.findByLikedByPersonName(person.getName());
return new PersonDetails(person, movies);
});
}
}| 1 | Here, several calls to multiple repositories are wrapped in one single, read-only transaction. |
TransactionTemplate inside private service methods and / or with the Neo4j clientimport java.util.Collection;
import org.neo4j.driver.types.Node;
import org.springframework.data.neo4j.core.Neo4jClient;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.support.TransactionTemplate;
public class PersonService {
private final TransactionTemplate readOnlyTx;
private final Neo4jClient neo4jClient;
public PersonService(PlatformTransactionManager transactionManager, Neo4jClient neo4jClient) {
this.readOnlyTx = new TransactionTemplate(transactionManager, (1)
new TransactionDefinition() {
@Override public boolean isReadOnly() {
return true;
}
}
);
this.neo4jClient = neo4jClient;
}
void internalOperation() { (2)
Collection<Node> nodes = this.readOnlyTx.execute(state -> {
return neo4jClient.query("MATCH (n) RETURN n").fetchAs(Node.class) (3)
.mappedBy((types, record) -> record.get(0).asNode())
.all();
});
}
}| 1 | Create an instance of the TransactionTemplate with the characteristics you need.
Of course, this can be a global bean, too. |
| 2 | Reason number one for using the transaction template: Declarative transactions don’t work
in package private or private methods and also not in inner method calls (imagine another method
in this service calling internalOperation) due to their nature being implemented with Aspects
and proxies. |
| 3 | The Neo4jClient is a fixed utility provided by SDN. It cannot be annotated, but it integrates with Spring.
So it gives you everything you would do with the pure driver and without automatic mapping and with
transactions. It also obeys declarative transactions. |
Can I retrieve the latest Bookmarks or seed the transaction manager?
正如在 Bookmark Management中简要提到的,无需对书签进行任何配置。但是,检索 SDN 事务系统从数据库接收到的最新书签可能很有用。您可以添加一个 `BookmarkCapture`之类的 `@Bean`来执行此操作:
As mentioned briefly in Bookmark Management, there is no need to configure anything with regard to bookmarks.
It may however be useful to retrieve the latest bookmark the SDN transaction system received from a database.
You can add a @Bean like BookmarkCapture to do this:
import java.util.Set;
import org.neo4j.driver.Bookmark;
import org.springframework.context.ApplicationListener;
public final class BookmarkCapture
implements ApplicationListener<Neo4jBookmarksUpdatedEvent> {
@Override
public void onApplicationEvent(Neo4jBookmarksUpdatedEvent event) {
// We make sure that this event is called only once,
// the thread safe application of those bookmarks is up to your system.
Set<Bookmark> latestBookmarks = event.getBookmarks();
}
}对于播种事务系统,需要一个如下所示的自定义事务管理器:
For seeding the transaction system, a customized transaction manager like the following is required:
import java.util.Set;
import java.util.function.Supplier;
import org.neo4j.driver.Bookmark;
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.data.neo4j.core.transaction.Neo4jBookmarkManager;
import org.springframework.data.neo4j.core.transaction.Neo4jTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class BookmarkSeedingConfig {
@Bean
public PlatformTransactionManager transactionManager(
Driver driver, DatabaseSelectionProvider databaseNameProvider) { (1)
Supplier<Set<Bookmark>> bookmarkSupplier = () -> { (2)
Bookmark a = null;
Bookmark b = null;
return Set.of(a, b);
};
Neo4jBookmarkManager bookmarkManager =
Neo4jBookmarkManager.create(bookmarkSupplier); (3)
return new Neo4jTransactionManager(
driver, databaseNameProvider, bookmarkManager); (4)
}
}| 1 | Let Spring inject those |
| 2 | This supplier can be anything that holds the latest bookmarks you want to bring into the system |
| 3 | Create the bookmark manager with it |
| 4 | Pass it on to the customized transaction manager |
除非您的应用程序需要访问或提供这些数据,否则没有 no 这些需求。如果有疑问,不要执行任何操作。
There is no need to do any of these things above, unless your application has the need to access or provide this data. If in doubt, don’t do either.
Can I disable bookmark management?
我们提供了一个 Noop 书签管理器,可以有效地禁用书签管理。
We provide a Noop bookmark manager that effectively disables bookmark management.
自行承担使用此书签管理器的风险,它实际上会通过删除所有书签且从不提供书签来禁用任何书签管理。在集群中,您遭受过时读取的风险很高。在单实例中,它很可能不会产生任何影响。
Use this bookmark manager at your own risk, it will effectively disable any bookmark management by dropping all bookmarks and never supplying any. In a cluster you will be at a high risk of experiencing stale reads. In a single instance it will most likely not make any difference.
+在群集中,这可能是一种明智的方法,仅当您可以耐受过时读取并且不会有覆盖旧数据的危险时才使用。
+ In a cluster this can be a sensible approach only and if only you can tolerate stale reads and are not in danger of overwriting old data.
以下配置将创建书签管理器的“noop”变体,该变体将从相关类中获取。
The following configuration creates a "noop" variant of the bookmark manager that will be picked up from relevant classes.
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.transaction.Neo4jBookmarkManager;
@Configuration
public class BookmarksDisabledConfig {
@Bean
public Neo4jBookmarkManager neo4jBookmarkManager() {
return Neo4jBookmarkManager.noop();
}
}您可以单独配置 Neo4jTransactionManager/Neo4jClient 和 ReactiveNeo4jTransactionManager/ReactiveNeo4jClient 对,但我们建议仅在为特定的数据库选择需求配置它们时才这样做。
You can configure the pairs of Neo4jTransactionManager/Neo4jClient and ReactiveNeo4jTransactionManager/ReactiveNeo4jClient individually, but we recommend in doing so only when you already configuring them for specific database selection needs.
Do I need to use Neo4j specific annotations?
否。可以自由使用以下等效的 Spring Data 注解:
No. You are free to use the following, equivalent Spring Data annotations:
| SDN specific annotation | Spring Data common annotation | Purpose | Difference |
|---|---|---|---|
|
|
Marks the annotated attribute as the unique id. |
Specific annotation has no additional features. |
|
|
Marks the class as persistent entity. |
|
How do I use externally generated ids?
我们提供了 org.springframework.data.neo4j.core.schema.IdGenerator 接口。以任何方式实现它,并按如下方式配置实现:
We provide the interface org.springframework.data.neo4j.core.schema.IdGenerator.
Implement it in any way you want and configure your implementation like this:
@Node
public class ThingWithGeneratedId {
@Id @GeneratedValue(TestSequenceGenerator.class)
private String theId;
}如果将类名传递给 @GeneratedValue,则此类必须具有无参数的默认构造函数。但是,也可以使用字符串:
If you pass in the name of a class to @GeneratedValue, this class must have a no-args default constructor.
You can however use a string as well:
@Node
public class ThingWithIdGeneratedByBean {
@Id @GeneratedValue(generatorRef = "idGeneratingBean")
private String theId;
}通过此方法,idGeneratingBean 指向 Spring 上下文中的 Bean。这对于序列生成可能很有用。
With that, idGeneratingBean refers to a bean in the Spring context.
This might be useful for sequence generating.
|
对于 id,非 final 字段不需要 setter。 |
|
Setters are not required on non-final fields for the id. |
Do I have to create repositories for each domain class?
否。查看 SDN building blocks,然后找到 Neo4jTemplate`或 `ReactiveNeo4jTemplate。
No.
Have a look at the SDN building blocks and find the Neo4jTemplate or the ReactiveNeo4jTemplate.
这些模板知道您的域,并提供检索、编写和计数实体所需的所有基本 CRUD 方法。
Those templates know your domain and provide all necessary basic CRUD methods for retrieving, writing and counting entities.
这是我们经典的 imperative 模板电影示例:
This is our canonical movie example with the imperative template:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/spring_boot/TemplateExampleTest.java[]
@DataNeo4jTest
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/spring_boot/TemplateExampleTest.java[]下面是 reactive 版本,为简洁起见,省略了设置:
And here is the reactive version, omitting the setup for brevity:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/spring_boot/ReactiveTemplateExampleTest.java[]
@DataNeo4jTest
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/spring_boot/ReactiveTemplateExampleTest.java[]请注意,两个示例都使用了 Spring Boot 中的 @DataNeo4jTest。
Please note that both examples use @DataNeo4jTest from Spring Boot.
How do I use custom queries with repository methods returning Page<T> or Slice<T>?
虽然不必提供除派生查找器方法上的 Pageable(返回 Page<T> 或 Slice<T>)以外的任何内容作为参数,但必须准备自定义查询来处理可分页性。[带有 page 和 slice 示例的自定义查询] 提供了所需内容的概览。
While you don’t have to provide anything else apart a Pageable as a parameter on derived finder methods
that return a Page<T> or a Slice<T>, you must prepare your custom query to handle the pageable.
[custom-queries-with-page-and-slice-examples] gives you an overview about what’s needed.
import org.springframework.data.domain.Pageable;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
public interface MyPersonRepository extends Neo4jRepository<Person, Long> {
Page<Person> findByName(String name, Pageable pageable); (1)
@Query(""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n "
+ "ORDER BY n.name ASC SKIP $skip LIMIT $limit"
)
Slice<Person> findSliceByName(String name, Pageable pageable); (2)
@Query(
value = ""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n "
+ "ORDER BY n.name ASC SKIP $skip LIMIT $limit",
countQuery = ""
+ "MATCH (n:Person) WHERE n.name = $name RETURN count(n)"
)
Page<Person> findPageByName(String name, Pageable pageable); (3)
}| 1 | A derived finder method that creates a query for you.
It handles the Pageable for you.
You should use a sorted pageable. |
| 2 | This method uses @Query to define a custom query. It returns a Slice<Person>.
A slice does not know about the total number of pages, so the custom query
doesn’t need a dedicated count query. SDN will notify you that it estimates the next slice.
The Cypher template must spot both $skip and $limit Cypher parameter.
If you omit them, SDN will issue a warning. The will probably not match your expectations.
Also, the Pageable should be unsorted and you should provide a stable order.
We won’t use the sorting information from the pageable. |
| 3 | This method returns a page. A page knows about the exact number of total pages. Therefore, you must specify an additional count query. All other restrictions from the second method apply. |
Can I map named paths?
一系列连接的节点和关系在 Neo4j 中称为“路径”。Cypher 允许使用标识符命名路径,例如:
A series of connected nodes and relationships is called a "path" in Neo4j. Cypher allows paths to be named using an identifier, as exemplified by:
p = (a)-[*3..5]->(b)或者,如臭名昭著的 Movie 图表中包含的路径(在这种情况下,是两个演员之间的最短路径之一):
or as in the infamous Movie graph, that includes the following path (in that case, one of the shortest path between two actors):
MATCH p=shortestPath((bacon:Person {name:"Kevin Bacon"})-[*]-(meg:Person {name:"Meg Ryan"}))
RETURN p它看起来像这样:
Which looks like this:
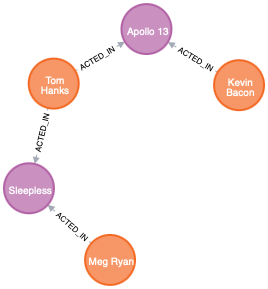
我们找到了 3 个标记为 Vertex 的节点和 2 个标记为 Movie 的节点。两者都可以使用自定义查询进行映射。假设 Vertex 和 Movie 都具有节点实体,并且 Actor 处理关系:
We find 3 nodes labeled Vertex and 2 nodes labeled Movie. Both can be mapped with a custom query.
Assume there’s a node entity for both Vertex and Movie as well as Actor taking care of the relationship:
@Node
public final class Person {
@Id @GeneratedValue
private final Long id;
private final String name;
private Integer born;
@Relationship("REVIEWED")
private List<Movie> reviewed = new ArrayList<>();
}
@RelationshipProperties
public final class Actor {
@RelationshipId
private final Long id;
@TargetNode
private final Person person;
private final List<String> roles;
}
@Node
public final class Movie {
@Id
private final String title;
@Property("tagline")
private final String description;
@Relationship(value = "ACTED_IN", direction = Direction.INCOMING)
private final List<Actor> actors;
}当对 Vertex 类型的域类使用如 [bacon-distance] 中所示的查询时:
When using a query as shown in [bacon-distance] for a domain class of type Vertex like this
interface PeopleRepository extends Neo4jRepository<Person, Long> {
@Query(""
+ "MATCH p=shortestPath((bacon:Person {name: $person1})-[*]-(meg:Person {name: $person2}))\n"
+ "RETURN p"
)
List<Person> findAllOnShortestPathBetween(@Param("person1") String person1, @Param("person2") String person2);
}它将检索路径中的所有人员并进行映射。如果路径上存在类似 REVIEWED 的关系类型,而且它们也存在于该域中,则这些关系类型将根据路径进行相应填充。
it will retrieve all people from the path and map them.
If there are relationship types on the path like REVIEWED that are also present on the domain, these
will be filled accordingly from the path.
当您使用基于路径查询的数据节点保存数据时,请特别小心。如果未加载所有关系,数据将丢失。
Take special care when you use nodes hydrated from a path based query to save data. If not all relationships are hydrated, data will be lost.
反过来也行。同一查询可用于 Movie 实体。然后它将仅填充电影。以下清单显示了如何执行此操作,以及如何使用路径上未找到的附加数据丰富查询。该数据用于正确填充缺失的关系(在这种情况下,为所有演员)
The other way round works as well. The same query can be used with the Movie entity.
It then will only populate movies.
The following listing shows how todo this as well as how the query can be enriched with additional data
not found on the path. That data is used to correctly populate the missing relationships (in that case, all the actors)
interface MovieRepository extends Neo4jRepository<Movie, String> {
@Query(""
+ "MATCH p=shortestPath(\n"
+ "(bacon:Person {name: $person1})-[*]-(meg:Person {name: $person2}))\n"
+ "WITH p, [n IN nodes(p) WHERE n:Movie] AS x\n"
+ "UNWIND x AS m\n"
+ "MATCH (m) <-[r:DIRECTED]-(d:Person)\n"
+ "RETURN p, collect(r), collect(d)"
)
List<Movie> findAllOnShortestPathBetween(@Param("person1") String person1, @Param("person2") String person2);
}查询返回路径以及收集到的所有关系和相关节点,以便 Movie 实体完全 hydrated。
The query returns the path plus all relationships and related nodes collected so that the movie entities are fully hydrated.
路径映射适用于单路径,也适用于多条路径记录(由 allShortestPath 函数返回)。
The path mapping works for single paths as well for multiple records of paths (which are returned by the allShortestPath function.)
|
命名的路径可以有效地填充和返回不仅仅是根节点,请参阅 appendix/custom-queries.adoc#custom-query.paths。 |
|
Named paths can be used efficiently to populate and return more than just a root node, see appendix/custom-queries.adoc#custom-query.paths. |
Is @Query the only way to use custom queries?
不,@Query 不是 执行自定义查询的唯一方法。当你的自定义查询完全填充你的域时,注解用起来很方便。请记住 SDN 假设你的映射域模型是真实。这意味着如果你通过仅部分填充模型的 @Query 使用自定义查询,那么你就有可能用同一个对象回写数据,最终会导致抹除或覆盖你不在查询中考虑的数据。
No, @Query is not the only way to run custom queries.
The annotation is comfortable in situations in which your custom query fills your domain completely.
Please remember that SDN assumes your mapped domain model to be the truth.
That means if you use a custom query via @Query that only fills a model partially, you are in danger of using the same
object to write the data back which will eventually erase or overwrite data you didn’t consider in your query.
因此,请在所有结果形状与你的 domainmodel 相似的情况下或你确定不会将部分映射模型用于写命令的情况下,使用带有 @Query 的仓库和声明式方法。
So, please use repositories and declarative methods with @Query in all cases where the result is shaped like your domain
model or you are sure you don’t use a partially mapped model for write commands.
有什么替代方案?
What are the alternatives?
-
Projections might be already enough to shape your view on the graph: They can be used to define the depth of fetching properties and related entities in an explicit way: By modelling them.
-
If your goal is to make only the conditions of your queries dynamic, then have a look at the
QuerydslPredicateExecutorbut especially our own variant of it, theCypherdslConditionExecutor. Both mixins allow adding conditions to the full queries we create for you. Thus, you will have the domain fully populated together with custom conditions. Of course, your conditions must work with what we generate. Find the names of the root node, the related nodes and more here. -
Use the Cypher-DSL via the
CypherdslStatementExecutoror theReactiveCypherdslStatementExecutor. The Cypher-DSL is predestined to create dynamic queries. In the end, it’s what SDN uses under the hood anyway. The corresponding mixins work both with the domain type of repository itself and with projections (something that the mixins for adding conditions don’t).
如果您认为可以使用带投影的部分动态查询或完全动态查询来解决您的问题,请立即返回 about Spring Data Neo4j Mixins章节。
If you think that you can solve your problem with a partially dynamic query or a full dynamic query together with a projection, please jump back now to the chapter about Spring Data Neo4j Mixins.
否则,请阅读这两篇文章: custom repository fragments中我们提供的 levels of abstractions。
Otherwise, please read up on two things: custom repository fragments the levels of abstractions we offer in SDN.
为什么现在讨论自定义仓库片段?
Why speaking about custom repository fragments now?
-
You might have more complex situation in which more than one dynamic query is required, but the queries still belong conceptually in a repository and not in the service layer
-
Your custom queries return a graph shaped result that fits not quite to your domain model and therefore the custom query should be accompanied by a custom mapping as well
-
You have the need for interacting with the driver, i.e. for bulk loads that should not go through object mapping.
假设以下仓库_声明_,它基本上聚合了一个基本仓库加上 3 个片段:
Assume the following repository declaration that basically aggregates one base repository plus 3 fragments:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/repositories/custom_queries/MovieRepository.java[]该存储库包含 Movies,如 the getting started section所示。
The repository contains Movies as shown in the getting started section.
仓库从中扩展的其他接口(DomainResults、NonDomainResults 和 LowlevelInteractions)是解决以上所有问题片段。
The additional interface from which the repository extends (DomainResults, NonDomainResults and LowlevelInteractions)
are the fragments that addresses all the concerns above.
Using complex, dynamic custom queries but still returning domain types
片段 DomainResults 声明了一个附加方法 findMoviesAlongShortestPath:
The fragment DomainResults declares one additional method findMoviesAlongShortestPath:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/repositories/custom_queries/MovieRepository.java[]此方法用 @Transactional(readOnly = true) 进行注解,以指示读者可以回答它。它不能由 SDN 推导出来,但需要一个自定义查询。此自定义查询由该接口的一个实现提供。实现具有相同名称,后缀为 Impl:
This method is annotated with @Transactional(readOnly = true) to indicate that readers can answer it.
It cannot be derived by SDN but would need a custom query.
This custom query is provided by the one implementation of that interface.
The implementation has the same name with the suffix Impl:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/repositories/custom_queries/MovieRepository.java[]| 1 | The Neo4jTemplate is injected by the runtime through the constructor of DomainResultsImpl. No need for @Autowired. |
| 2 | The Cypher-DSL is used to build a complex statement (pretty much the same as shown in faq.path-mapping.) The statement can be passed directly to the template. |
模板也针对基于字符串的查询进行重载,因此你也可以将查询写为字符串。这里重要的要点是:
The template has overloads for String-based queries as well, so you could write down the query as String as well. The important takeaway here is:
-
The template "knows" your domain objects and maps them accordingly
-
@Queryis not the only option to define custom queries -
They can be generated in various ways
-
The
@Transactionalannotation is respected
Using custom queries and custom mappings
很多时候,自定义查询表示自定义结果。所有这些结果都应映射为 @Node 吗?当然不!很多时候,这些对象表示读命令,并不意味着用作写命令。SDN 不能或不想映射 Cypher 中所有可能的东西也不是不可能的。但它确实提供了几个挂钩,可用于运行你自己的映射:在 Neo4jClient 上。使用 SDN Neo4jClient 比驱动程序的优点:
Often times a custom query indicates custom results.
Should all of those results be mapped as @Node? Of course not! Many times those objects represents read commands
and are not meant to be used as write commands.
It is also not unlikely that SDN cannot or want not map everything that is possible with Cypher.
It does however offer several hooks to run your own mapping: On the Neo4jClient.
The benefit of using the SDN Neo4jClient over the driver:
-
The
Neo4jClientis integrated with Springs transaction management -
It has a fluent API for binding parameters
-
It has a fluent API exposing both the records and the Neo4j type system so that you can access everything in your result to execute the mapping
声明片段与之前完全一样:
Declaring the fragment is exactly the same as before:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/repositories/custom_queries/MovieRepository.java[]| 1 | This is a made up non-domain result. A real world query result would probably look more complex. |
| 2 | The method this fragment adds. Again, the method is annotated with Spring’s @Transactional |
如果没有该片段的实现,启动就会失败,所以这里提供实现:
Without an implementation for that fragment, startup would fail, so here it is:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/repositories/custom_queries/MovieRepository.java[]| 1 | Here we use the Neo4jClient, as provided by the infrastructure. |
| 2 | The client takes only in Strings, but the Cypher-DSL can still be used when rendering into a String |
| 3 | Bind one single value to a named parameter. There’s also an overload to bind a whole map of parameters |
| 4 | This is the type of the result you want |
| 5 | And finally, the mappedBy method, exposing one Record for each entry in the result plus the drivers type system if needed.
This is the API in which you hook in for your custom mappings |
整个查询在 Spring 事务上下文中运行,在本例中,是只读事务。
The whole query runs in the context of a Spring transaction, in this case, a read-only one.
Low level interactions
有时候,你可能希望从仓库中进行批量加载或删除整个子图,或以非常具体的方式与 Neo4j Java 驱动程序进行交互。这也完全有可能。以下示例显示了如何操作:
Sometimes you might want to do bulk loadings from a repository or delete whole subgraphs or interact in very specific ways with the Neo4j Java-Driver. This is possible as well. The following example shows how:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/repositories/custom_queries/MovieRepository.java[]| 1 | Work with the driver directly. As with all the examples: There is no need for @Autowired magic. All the fragments
are actually testable on their own. |
| 2 | The use case is made up. Here we use a driver managed transaction deleting the whole graph and return the number of deleted nodes and relationships |
当然,此交互不会在 Spring 事务中运行,因为驱动程序不知道 Spring。
This interaction does of course not run in a Spring transaction, as the driver does not know about Spring.
综合起来,此测试将成功:
Putting it all together, this test succeeds:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$documentation/repositories/custom_queries/CustomQueriesIT.java[]最后一句话:所有三个接口和实现都由 Spring Data Neo4j 自动选取。无需进一步配置。此外,还可以仅通过一个附加片段(定义所有三个方法的接口)和一个实现来创建相同的整体仓库。然后,实现将具有所有三个注入的抽象(模板、客户端和驱动程序)。
As a final word: All three interfaces and implementations are picked up by Spring Data Neo4j automatically. There is no need for further configuration. Also, the same overall repository could have been created with only one additional fragment (the interface defining all three methods) and one implementation. The implementation would than have had all three abstractions injected (template, client and driver).
所有内容当然也适用于 reactive 存储库。它们将使用 ReactiveNeo4jTemplate 和 ReactiveNeo4jClient,以及由驱动程序提供的 reactive 会话。
All of this applies of course to reactive repositories as well.
They would work with the ReactiveNeo4jTemplate and ReactiveNeo4jClient and the reactive session provided by the driver.
如果你有所有存储库的重复方法,你可以替换默认存储库实现。
If you have recurring methods for all repositories, you could swap out the default repository implementation.
How do I use custom Spring Data Neo4j base repositories?
与共享 Spring Data Commons 文档在 Customize the Base Repository中针对 Spring Data JPA 展示的方式基本相同。只是在我们的案例中,您将从以下内容进行扩展:
Basically the same ways as the shared Spring Data Commons documentation shows for Spring Data JPA in Customize the Base Repository. Only that in our case you would extend from
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$integration/imperative/CustomBaseRepositoryIT.java[]| 1 | This signature is required by the base class. Take the Neo4jOperations (the actual specification of the Neo4jTemplate)
and the entity information and store them on an attribute if needed. |
在这个示例中,我们禁止使用 findAll 方法。你可以添加接受获取深度的方法,并基于该深度运行自定义查询。可在 [domain-results] 看到一种实现方式。
In this example we forbid the use of the findAll method.
You could add methods taking in a fetch depth and run custom queries based on that depth.
One way to do this is shown in [domain-results].
要为所有声明的存储库启用此基本存储库,请使用以下内容启用 Neo4j 存储库:@EnableNeo4jRepositories(repositoryBaseClass = MyRepositoryImpl.class)。
To enable this base repository for all declared repositories enable Neo4j repositories with: @EnableNeo4jRepositories(repositoryBaseClass = MyRepositoryImpl.class).
How do I audit entities?
所有 Spring Data 注解都受支持。这些注解是
All Spring Data annotations are supported. Those are
-
org.springframework.data.annotation.CreatedBy -
org.springframework.data.annotation.CreatedDate -
org.springframework.data.annotation.LastModifiedBy -
org.springframework.data.annotation.LastModifiedDate
Auditing 为您提供了如何在 Spring Data Commons 的更大上下文中使用审核的一般视图。以下清单显示了 Spring Data Neo4j 提供的每个配置选项:
Auditing gives you a general view how to use auditing in the bigger context of Spring Data Commons. The following listing presents every configuration option provided by Spring Data Neo4j:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$integration/imperative/AuditingIT.java[]| 1 | Set to true if you want the modification data to be written during creating as well |
| 2 | Use this attribute to specify the name of the bean that provides the auditor (i.e. a user name) |
| 3 | Use this attribute to specify the name of a bean that provides the current date. In this case a fixed date is used as the above configuration is part of our tests |
reactive 版本基本相同,不同之处在于审计员感知 bean 的类型是 ReactiveAuditorAware,因此检索审计员是 reactive 流的一部分。
The reactive version is basically the same apart from the fact the auditor aware bean is of type ReactiveAuditorAware,
so that the retrieval of an auditor is part of the reactive flow.
除了这些审计机制之外,你还可以向上下文中添加尽可能多实现 BeforeBindCallback<T> 或 ReactiveBeforeBindCallback<T> 的 bean。Spring Data Neo4j 会选择这些 bean,并在实体持久化之前按顺序(如果它们实现了 Ordered 或用 @Order 进行了注释)调用它们。
In addition to those auditing mechanism you can add as many beans implementing BeforeBindCallback<T> or ReactiveBeforeBindCallback<T>
to the context. These beans will be picked up by Spring Data Neo4j and called in order (in case they implement Ordered or
are annotated with @Order) just before an entity is persisted.
它们可以修改实体或返回一个完全新的实体。以下示例向上下文中添加了一个回调,它会在实体被持久化之前更改一个属性:
They can modify the entity or return a completely new one. The following example adds one callback to the context that changes one attribute before the entity is persisted:
Unresolved include directive in modules/ROOT/pages/faq.adoc - include::example$integration/imperative/CallbacksIT.java[]不需要其他配置。
No additional configuration is required.
How do I use "Find by example"?
“按示例查找”是 SDN 中的一项新功能。你可以实例化实体或使用现有实体。使用此实例,你可以创建一个 org.springframework.data.domain.Example。如果你的存储库扩展 org.springframework.data.neo4j.repository.Neo4jRepository 或 org.springframework.data.neo4j.repository.ReactiveNeo4jRepository,你可以立即使用可用的接受示例的 findBy 方法,如 find-by-example-example 中所示。
"Find by example" is a new feature in SDN.
You instantiate an entity or use an existing one.
With this instance you create an org.springframework.data.domain.Example.
If your repository extends org.springframework.data.neo4j.repository.Neo4jRepository or org.springframework.data.neo4j.repository.ReactiveNeo4jRepository, you can immediately use the available findBy methods taking in an example, like shown in find-by-example-example.
Example<MovieEntity> movieExample = Example.of(new MovieEntity("The Matrix", null));
Flux<MovieEntity> movies = this.movieRepository.findAll(movieExample);
movieExample = Example.of(
new MovieEntity("Matrix", null),
ExampleMatcher
.matchingAny()
.withMatcher(
"title",
ExampleMatcher.GenericPropertyMatcher.of(ExampleMatcher.StringMatcher.CONTAINING)
)
);
movies = this.movieRepository.findAll(movieExample);你还可以否定单个属性。这将添加一个适当的 NOT 操作,从而将 = 变换为 <>。所有标量数据类型和所有字符串操作符都受支持:
You can also negate individual properties. This will add an appropriate NOT operation, thus turning an = into a <>.
All scalar datatypes and all string operators are supported:
Example<MovieEntity> movieExample = Example.of(
new MovieEntity("Matrix", null),
ExampleMatcher
.matchingAny()
.withMatcher(
"title",
ExampleMatcher.GenericPropertyMatcher.of(ExampleMatcher.StringMatcher.CONTAINING)
)
.withTransformer("title", Neo4jPropertyValueTransformers.notMatching())
);
Flux<MovieEntity> allMoviesThatNotContainMatrix = this.movieRepository.findAll(movieExample);Do I need Spring Boot to use Spring Data Neo4j?
不需要。自动通过 Spring Boot 配置许多 Spring 方面虽然消除了很多手动苦力并且是设置新 Spring 项目的推荐方法,但你不需要这样做。
No, you don’t. While the automatic configuration of many Spring aspects through Spring Boot takes away a lot of manual cruft and is the recommended approach for setting up new Spring projects, you don’t need to have to use this.
上面描述的解决方案需要以下依赖项:
The following dependency is required for the solutions described above:
<dependency>
<groupId>{neo4jGroupId}</groupId>
<artifactId>{artifactId}</artifactId>
<version>{version}</version>
</dependency>Gradle 设置的坐标相同。
The coordinates for a Gradle setup are the same.
若要选择一个不同的数据库 - 无论是静态的还是动态的,都可以添加一个 DatabaseSelectionProvider 类型的 Bean,如 Neo4j 4 supports multiple databases - How can I use them? 中所述。对于 reactive 场景,我们提供了 ReactiveDatabaseSelectionProvider。
To select a different database - either statically or dynamically - you can add a Bean of type DatabaseSelectionProvider as explained in Neo4j 4 supports multiple databases - How can I use them?.
For a reactive scenario, we provide ReactiveDatabaseSelectionProvider.
Using Spring Data Neo4j inside a Spring context without Spring Boot
我们提供了两个抽象配置类来支持你引入必要的 bean:org.springframework.data.neo4j.config.AbstractNeo4jConfig 用于命令式数据库访问和 org.springframework.data.neo4j.config.AbstractReactiveNeo4jConfig 用于 reactive 版本。它们旨在分别与 @EnableNeo4jRepositories 和 @EnableReactiveNeo4jRepositories 一起使用。请参阅 [bootless-imperative-configuration] 和 [bootless-reactive-configuration] 来查看示例用法。这两个类都要求你覆盖 driver(),你在其中应创建驱动程序。
We provide two abstract configuration classes to support you in bringing in the necessary beans:
org.springframework.data.neo4j.config.AbstractNeo4jConfig for imperative database access and
org.springframework.data.neo4j.config.AbstractReactiveNeo4jConfig for the reactive version.
They are meant to be used with @EnableNeo4jRepositories and @EnableReactiveNeo4jRepositories respectively.
See [bootless-imperative-configuration] and [bootless-reactive-configuration] for an example usage.
Both classes require you to override driver() in which you are supposed to create the driver.
若要获取 Neo4j client的命令式版本、模板和对命令式存储库的支持,请使用类似这里所示的内容:
To get the imperative version of the Neo4j client, the template and support for imperative repositories, use something similar as shown here:
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import org.springframework.data.neo4j.config.AbstractNeo4jConfig;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.data.neo4j.repository.config.EnableNeo4jRepositories;
@Configuration
@EnableNeo4jRepositories
@EnableTransactionManagement
class MyConfiguration extends AbstractNeo4jConfig {
@Override @Bean
public Driver driver() { (1)
return GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"));
}
@Override
protected Collection<String> getMappingBasePackages() {
return Collections.singletonList(Person.class.getPackage().getName());
}
@Override @Bean (2)
protected DatabaseSelectionProvider databaseSelectionProvider() {
return DatabaseSelectionProvider.createStaticDatabaseSelectionProvider("yourDatabase");
}
}| 1 | The driver bean is required. |
| 2 | This statically selects a database named yourDatabase and is optional. |
以下列表提供了 reactive Neo4j 客户端和模板,启用 reactive 事务管理和发现 Neo4j 相关存储库:
The following listing provides the reactive Neo4j client and template, enables reactive transaction management and discovers Neo4j related repositories:
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.config.AbstractReactiveNeo4jConfig;
import org.springframework.data.neo4j.repository.config.EnableReactiveNeo4jRepositories;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@Configuration
@EnableReactiveNeo4jRepositories
@EnableTransactionManagement
class MyConfiguration extends AbstractReactiveNeo4jConfig {
@Bean
@Override
public Driver driver() {
return GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"));
}
@Override
protected Collection<String> getMappingBasePackages() {
return Collections.singletonList(Person.class.getPackage().getName());
}
}Using Spring Data Neo4j in a CDI 2.0 environment
为了方便起见,我们提供了带有 Neo4jCdiExtension 的 CDI 扩展。在兼容的 CDI 2.0 容器中运行时,它会通过 Java’s service loader SPI 自动注册并加载。
For your convenience we provide a CDI extension with Neo4jCdiExtension.
When run in a compatible CDI 2.0 container, it will be automatically be registered and loaded through Java’s service loader SPI.
您只需要将一个带注解的类型引入您的应用程序,该类型生成 Neo4j Java 驱动程序:
The only thing you have to bring into your application is an annotated type that produces the Neo4j Java Driver:
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
public class Neo4jConfig {
@Produces @ApplicationScoped
public Driver driver() { (1)
return GraphDatabase
.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"));
}
public void close(@Disposes Driver driver) {
driver.close();
}
@Produces @Singleton
public DatabaseSelectionProvider getDatabaseSelectionProvider() { (2)
return DatabaseSelectionProvider.createStaticDatabaseSelectionProvider("yourDatabase");
}
}| 1 | Same as with plain Spring in [bootless-imperative-configuration], but annotated with the corresponding CDI infrastructure. |
| 2 | This is optional. However, if you run a custom database selection provider, you must not qualify this bean. |
如果您在 SE 容器(例如 Weld 提供的那个)中运行,您可以像这样启用扩展:
If you are running in a SE Container - like the one Weld provides for example, you can enable the extension like that:
import javax.enterprise.inject.se.SeContainer;
import javax.enterprise.inject.se.SeContainerInitializer;
import org.springframework.data.neo4j.config.Neo4jCdiExtension;
public class SomeClass {
void someMethod() {
try (SeContainer container = SeContainerInitializer.newInstance()
.disableDiscovery()
.addExtensions(Neo4jCdiExtension.class)
.addBeanClasses(YourDriverFactory.class)
.addPackages(Package.getPackage("your.domain.package"))
.initialize()
) {
SomeRepository someRepository = container.select(SomeRepository.class).get();
}
}
}