Chatgpt 简明教程
ChatGPT – Machine Learning
是什么基础模型强化了 ChatGPT 的强大能力?
What is the foundation model that empowers ChatGPT’s remarkable capabilities?
ChatGPT 的功能建立在机器学习的基础之上,并得到了其类型监督、无监督和强化学习的关键支持。在本章中,我们将看到机器学习如何为 ChatGPT 的能力做出贡献。
ChatGPT’s functionality is built on the foundations of machine learning with key contributions from its types-supervised, unsupervised, and reinforcement learning. In this chapter, we will see how machine learning contributes to ChatGPT’s capabilities.
What is Machine Learning?
机器学习是一个动态的人工智能 (AI) 领域,借助此领域,计算机系统可以通过算法或模型从原始数据中提取模式。这些算法使计算机能够自主地从经验中学习,并在没有明确编程的情况下进行预测或决策。
Machine learning is that dynamic field of Artificial Intelligence (AI) with the help of which computer system extract patterns from raw data through algorithms or models. These algorithms enable computers to learn from experience autonomously and make predictions or decisions without being explicitly programmed.
现在,让我们了解机器学习的类型及其在塑造 ChatGPT 能力方面的贡献。
Now, let’s understand the types of machine learning and their contribution in shaping ChatGPT’s capabilities.
Supervised Learning
监督式学习是机器学习的一种类型,其中算法或模型使用标记数据集进行训练。在此方法中,算法提供了输入输出对,其中每个输入都与相应的输出或标记相关联。监督式学习的目标是使模型学习输入和输出之间的映射或关系,以便它可以对新的、未见数据进行准确的预测或分类。
Supervised learning is a category of machine learning where an algorithm or model is trained using a labeled dataset. In this approach, the algorithm is provided with input-output pairs, where each input is associated with a corresponding output or label. The goal of supervised learning is for the model to learn the mapping or relationship between inputs and outputs so that it can make accurate predictions or classifications on new, unseen data.
ChatGPT 使用监督式学习来最初训练其语言模型。在此第 1 阶段中,使用包含输入和输出示例对的标记数据对语言模型进行训练。在 ChatGPT 的上下文中,输入包含部分文本,而相应的输出是对该文本的延续或响应。
ChatGPT uses supervised learning to initially train its language model. During this first phase, the language model is trained using labeled data containing pairs of input and output examples. In the context of ChatGPT, the input comprises a portion of text, and the corresponding output is the continuation or response to that text.
这些注释数据有助于模型学习不同单词、短语及其上下文相关性之间的关联。ChatGPT 通过接触各种示例,利用这些信息基于给定的输入预测最可能的下一个单词或单词序列。这就是监督式学习如何成为 ChatGPT 理解和生成类人文本的能力的基础。
This annotated data helps the model learn the associations between different words, phrases, and their contextual relevance. ChatGPT, through exposure to diverse examples, utilizes this information to predict the most likely next word or sequence of words based on the given input. That’s how supervised learning becomes the foundation for ChatGPT’s ability to understand and generate human-like text.
Unsupervised Learning
无监督式学习是一种机器学习方法,其中算法或模型自动地分析数据并从中获取见解,而无需标记示例的指导。简单来说,此方法的目标是找到未标记数据中的固有模式、结构或关系。
Unsupervised learning is a machine learning approach where algorithms or models analyze and derive insights from the data autonomously, without the guidance of labeled examples. In simple words, the goal of this approach is to find the inherent patterns, structures, or relationships within unlabeled data.
监督式学习为 ChatGPT 提供了坚实的基础,但 ChatGPT 的真正魔力在于创造性地生成连贯且上下文相关的答案或响应的能力。这是无监督式学习发挥作用的地方。
Supervised learning provides a solid foundation for ChatGPT, but the true magic of ChatGPT lies in the ability to creatively generate coherent and contextually relevant answers or responses. This is where the role of unsupervised learning comes into effect.
借助对各种互联网文本的大量预训练,ChatGPT 对事实、推理能力和语言模式有了深刻的理解。这就是无监督式学习如何释放 ChatGPT 的创造力并使其能够对各种用户输入生成有意义的响应。
With the help of extensive pre-training on a diverse range of internet text, ChatGPT develops a deep understanding of facts, reasoning abilities, and language patterns. That’s how unsupervised learning unleashes ChatGPT’s creativity and enables it to generate meaningful responses to a wide array of user inputs.
Reinforcement Learning
与监督式学习相比,强化学习 (RL) 是一种机器学习范例,其中代理通过与环境交互来学习做出决策。代理在环境中执行动作,以奖励或惩罚的形式接收反馈,并使用此反馈随着时间的推移改进其决策制定策略。
Compared to supervised learning, reinforcement learning (RL) is a type of machine learning paradigm where an agent learns to make decisions by interacting with an environment. The agent takes actions in the environment, receives feedback in the form of rewards or punishments, and uses this feedback to improve its decision-making strategy over time.
强化学习充当导航指南,引导 ChatGPT 进行动态且不断发展的对话。在最初的监督学习和无监督学习阶段之后,该模型会经历强化学习以根据用户反馈微调其响应。
Reinforcement learning acts as a navigational compass that guides ChatGPT through dynamic and evolving conversations. After the initial supervised and unsupervised learning phases, the model undergoes reinforcement learning to fine-tune its responses based on user feedback.
大型语言模型 (LLM) 就像超级智能工具,可以从大量文本中获取知识。现在,想象一下通过使用称为强化学习的技术使这些工具变得更智能。这就像教他们将他们的知识转化为有用的行动。这种智力组合是 Reinforcement Learning with Human Feedback (RLHF) 背后的魔力,这些语言模型甚至可以更好地理解我们并对我们做出回应。
Large language models (LLMs) are like super-smart tools that derive knowledge from vast amounts of text. Now, imagine making these tools even smarter by using a technique called reinforcement learning. It’s like teaching them to turn their knowledge into useful actions. This intellectual combination is the magic behind something called Reinforcement Learning with Human Feedback (RLHF), making these language models even better at understanding and responding to us.
Reinforcement Learning with Human Feedback (RLHF)
在 2017 年,OpenAI 发表了一篇名为 Deep reinforcement learning from human preferences 的研究论文,首次提出了用人类反馈进行强化学习 (RLHF)。有时我们需要在使用强化学习的情况下操作,但是手头的任务很难解释。在这种情况下,人类反馈变得很重要,并可能产生巨大的影响。
In 2017, OpenAI published a research paper titled Deep reinforcement learning from human preferences in which it unveiled Reinforcement Learning with Human Feedback (RLHF) for the first time. Sometimes we need to operate in situations where we use reinforcement learning, but the task at hand is tough to explain. In such scenarios human feedback becomes important and can make a huge impact.
RLHF 通过涉及少量的人类反馈来完善代理的学习过程来工作。让我们借助此图表了解其整体训练过程,它基本上是一个三步反馈循环 −
RLHF works by involving small increments of human feedback to refine the agent’s learning process. Let’s understand its overall training process, which is basically a three-step feedback cycle, with the help of this diagram −
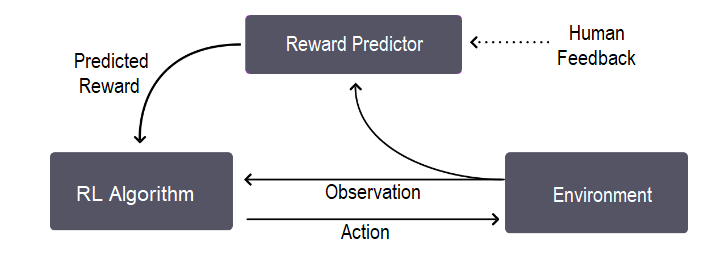
正如我们从图片中看到的那样,反馈循环介于代理对目标的理解、人类反馈和强化学习训练之间。
As we can see in the image, the feedback cycle is between the agent’s understanding of the goal, human feedback, and the reinforcement learning training.
RLHF 最初用于机器人技术等领域,事实证明它可以提供更可控的用户体验。这就是为什么 OpenAI、Meta、Google、Amazon Web Services、IBM、DeepMind、Anthropic 等主要公司已将 RLHF 添加到其大型语言模型 (LLM) 中。事实上,RLHF 已成为最流行的 LLM- ChatGPT 中的关键组成部分。
RLHF, initially used in areas like robotics, proves itself to provide a more controlled user experience. That’s why major companies like OpenAI, Meta, Google, Amazon Web Services, IBM, DeepMind, Anthropic, and more have added RLHF to their Large Language Models (LLMs). In fact, RLHF has become a key building block of the most popular LLM-ChatGPT.
ChatGPT and RLHF
在本节中,我们将解释 ChatGPT 如何使用 RLHF 来适应人类反馈。
In this section, we will explain how ChatGPT used RLHF to align to the human feedback.
OpenAI 在一个称为 RLHF 的循环中利用人类反馈进行强化学习,以训练其 InstructGPT 模型。在此之前,OpenAI API 由 GPT-3 语言模型驱动,该模型往往会产生可能不真实和有害的输出,因为它们不 aligned 与其用户。
OpenAI utilized reinforcement learning with human feedback in a loop, known as RLHF, to train their InstructGPT models. Prior to this, the OpenAI API was driven by GPT-3 language model which tends to produce outputs that may be untruthful and toxic because they are not aligned with their users.
另一方面, InstructGPT 模型比 GPT-3 模型好得多,因为它们 −
On the other hand, InstructGPT models are much better than GPT-3 model because they −
-
Make up facts less often and
-
Show small decrease in generation of toxic outputs.
Steps to Fine-tune ChatGPT with RLHF
对于 ChatGPT,OpenAI 采用了类似于 InstructGPT 模型的方法,在数据收集的设置上略有不同。
For ChatGPT, OpenAI adopted a similar approach to InstructGPT models, with a minor difference in the setup for data collection.
Step 1: The SFT (Supervised Fine-Tuning) Model
第一步主要涉及到数据收集,用以训练一种监督策略模型,称为 SFT 模型。对于数据收集,选择了一组提示,然后请一组人类标签人员展示所需的输出。
The first step mainly involves data collection to train a supervised policy model, known as the SFT model. For data collection, a set of prompts is chosen, and a group of human labelers is then asked to demonstrate the desired output.
现在,不是对原始 GPT-3 模型进行微调,像 ChatGPT 这样的多功能聊天机器人的开发者决定使用 GPT-3.5 系列中的预训练模型。换而言之,开发者选择了在“代码模型”之上进行微调,而不是纯基于文本的模型。
Now, instead of fine-tuning the original GPT-3 model, the developers of a versatile chatbot like ChatGPT decided to use a pretrained model from the GPT-3.5 series. In other words, the developers opted to fine-tune on top of a "code model" instead of purely text-based model.
在此步骤中,源自于 SFT 模型的一个重要问题是它很容易出现偏差,导致输出缺乏用户关注。
A major issue with the SFT model derived from this step is its tendency to experience misalignment, leading to an output that lacks user attentiveness.
Step 2: The Reward Model (RM)
此步骤的主要目标是从数据直接获取目标函数。此目标函数为 SFT 模型的输出分配了分数,按比例反映它们对人类的吸引力。
The primary objective of this step is to acquire an objective function directly from the data. This objective function assigns scores to the SFT model outputs, reflecting their desirability for humans in proportion.
我们来看看它如何工作-
Let’s see how it works −
-
First, a list of prompts and SFT model outputs are sampled.
-
A labeler then ranks these outputs from best to worst. The dataset now becomes 10 times bigger than the baseline dataset used in the first step for SFT model.
-
The new data set is now used to train our reward model (RM).
Step 3: Fine-tuning the SFT Policy Using PPO (Proximal Policy Optimization)
在此步骤中,应用了一种名为近端策略优化 (PPO) 的特定强化学习算法,对 SFT 模型进行微调,使其优化 RM。此步骤的输出是名为 PPO 模型的一个微调模型。我们了解一下它是如何工作的-
In this step, a specific algorithm of reinforcement learning called Proximal Policy Optimization (PPO) is applied to fine tune the SFT model allowing it to optimize the RM. The output of this step is a fine tune model called the PPO model. Let’s understand how it works −
-
First, a new prompt is selected from the dataset.
-
Now, the PPO model is initialized to fine-tune the SFT model.
-
This policy now generates an output and then the RM calculates a reward from that output.
-
This reward is then used to update the policy using PPO.
Conclusion
在本章中,我们解释了机器学习如何提升 ChatGPT 的非凡能力。我们还了解到机器学习范例(监督式学习、无监督式学习和强化学习)如何塑造 ChatGPT 的能力。
In this chapter, we explained how machine learning empowers ChatGPT’s remarkable capabilities. We also understood how the machine learning paradigms (Supervised, Unsupervised, and Reinforcement learning) contribute to shaping ChatGPT’s capabilities.
在人类反馈强化学习 (RLHF) 的帮助下,我们探索了人类反馈的重要性及其对像 ChatGPT 这样的通用聊天机器人的性能的巨大影响。
With the help of RLHF (Reinforcement Learning with Human Feedback), we explored the importance of human feedback and its huge impact on the performance of general-purpose chatbots like ChatGPT.