Using Apache Kafka Streams
此指南演示了您的 Quarkus 应用程序如何利用 Apache Kafka Streams API 来基于 Apache Kafka 实现流处理应用程序。
This guide demonstrates how your Quarkus application can utilize the Apache Kafka Streams API to implement stream processing applications based on Apache Kafka.
Prerequisites
Unresolved directive in kafka-streams.adoc - include::{includes}/prerequisites.adoc[]
建议您事先阅读 Kafka quickstart 。
It is recommended, that you have read the Kafka quickstart before.
|
用于 Kafka Streams 的 Quarkus 扩展允许在开发期间通过支持 Quarkus Dev 模式(例如,通过 The Quarkus extension for Kafka Streams allows for very fast turnaround times during development by supporting the Quarkus Dev Mode (e.g. via 建议的开发设置是,备有一些生成器,以在固定间隔(例如每秒)内在经过处理的主题上创建测试消息,并使用 A recommended development set-up is to have some producer which creates test messages on the processed topic(s) in fixed intervals, e.g. every second and observe the streaming application’s output topic(s) using a tool such as 为了获得最佳的开发体验,我们建议将以下配置设置应用到您的 Kafka 代理: For the best development experience, we recommend applying the following configuration settings to your Kafka broker: 还在您的 Quarkus Also specify the following settings in your Quarkus 这些设置组合在一起将确保应用程序在 dev 模式下重新启动后可以非常快速地重新连接到代理。 Together, these settings will ensure that the application can very quickly reconnect to the broker after being restarted in dev mode. |
Architecture
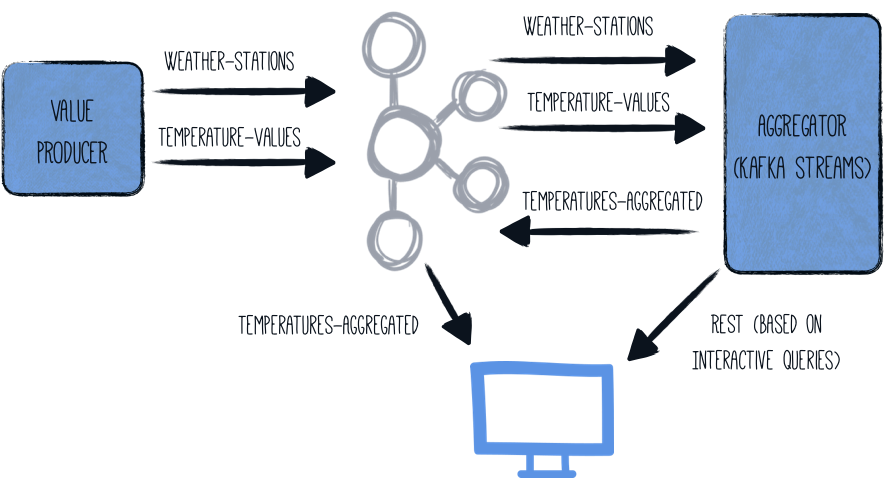
在本指南中,我们将在一个组件(名为 generator)中生成(随机)温度值。这些值与给定的气象站相关联,并写入 Kafka 主题(temperature-values)。另一个主题(weather-stations)仅包含天气台本身的主要数据(id 和名称)。
In this guide, we are going to generate (random) temperature values in one component (named generator).
These values are associated to given weather stations and are written in a Kafka topic (temperature-values).
Another topic (weather-stations) contains just the main data about the weather stations themselves (id and name).
第二个组件(aggregator)从两个 Kafka 主题中读取信息,并在流管道中处理它们:
A second component (aggregator) reads from the two Kafka topics and processes them in a streaming pipeline:
-
the two topics are joined on weather station id
-
per weather station the min, max and average temperature is determined
-
this aggregated data is written out to a third topic (
temperatures-aggregated)
可以通过检查输出主题来检查数据。通过公开一个 Kafka Streams interactive query,也可以通过一个简单的 REST 查询来获得每个气象站的最新结果。
The data can be examined by inspecting the output topic. By exposing a Kafka Streams interactive query, the latest result for each weather station can alternatively be obtained via a simple REST query.
整体架构如下所示:
The overall architecture looks like so:
Solution
我们建议您遵循接下来的部分中的说明,按部就班地创建应用程序。然而,您可以直接跳到完成的示例。
We recommend that you follow the instructions in the next sections and create the application step by step. However, you can go right to the completed example.
克隆 Git 存储库: git clone {quickstarts-clone-url},或下载 {quickstarts-archive-url}[存档]。
Clone the Git repository: git clone {quickstarts-clone-url}, or download an {quickstarts-archive-url}[archive].
解决方案位于 kafka-streams-quickstart directory。
The solution is located in the kafka-streams-quickstart directory.
Creating the Producer Maven Project
首先,我们需要一个带有温度值生产者的新项目。使用以下命令创建一个新项目:
First, we need a new project with the temperature value producer. Create a new project with the following command:
Unresolved directive in kafka-streams.adoc - include::{includes}/devtools/create-app.adoc[]
此命令生成一个 Maven 项目,导入 Reactive Messaging 和 Kafka 连接器扩展。
This command generates a Maven project, importing the Reactive Messaging and Kafka connector extensions.
如果你已经配置了你的 Quarkus 项目,你可以在项目基本目录中运行以下命令,向你的项目添加 messaging-kafka 扩展:
If you already have your Quarkus project configured, you can add the messaging-kafka extension
to your project by running the following command in your project base directory:
Unresolved directive in kafka-streams.adoc - include::{includes}/devtools/extension-add.adoc[]
这会将以下内容添加到构建文件中:
This will add the following to your build file:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-messaging-kafka</artifactId>
</dependency>implementation("io.quarkus:quarkus-messaging-kafka")The Temperature Value Producer
创建一个 producer/src/main/java/org/acme/kafka/streams/producer/generator/ValuesGenerator.java 文件,内容如下:
Create the producer/src/main/java/org/acme/kafka/streams/producer/generator/ValuesGenerator.java file,
with the following content:
package org.acme.kafka.streams.producer.generator;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.time.Duration;
import java.time.Instant;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import io.smallrye.mutiny.Multi;
import io.smallrye.reactive.messaging.kafka.Record;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import org.jboss.logging.Logger;
/**
* A bean producing random temperature data every second.
* The values are written to a Kafka topic (temperature-values).
* Another topic contains the name of weather stations (weather-stations).
* The Kafka configuration is specified in the application configuration.
*/
@ApplicationScoped
public class ValuesGenerator {
private static final Logger LOG = Logger.getLogger(ValuesGenerator.class);
private Random random = new Random();
private List<WeatherStation> stations = List.of(
new WeatherStation(1, "Hamburg", 13),
new WeatherStation(2, "Snowdonia", 5),
new WeatherStation(3, "Boston", 11),
new WeatherStation(4, "Tokio", 16),
new WeatherStation(5, "Cusco", 12),
new WeatherStation(6, "Svalbard", -7),
new WeatherStation(7, "Porthsmouth", 11),
new WeatherStation(8, "Oslo", 7),
new WeatherStation(9, "Marrakesh", 20));
@Outgoing("temperature-values") (1)
public Multi<Record<Integer, String>> generate() {
return Multi.createFrom().ticks().every(Duration.ofMillis(500)) (2)
.onOverflow().drop()
.map(tick -> {
WeatherStation station = stations.get(random.nextInt(stations.size()));
double temperature = BigDecimal.valueOf(random.nextGaussian() * 15 + station.averageTemperature)
.setScale(1, RoundingMode.HALF_UP)
.doubleValue();
LOG.infov("station: {0}, temperature: {1}", station.name, temperature);
return Record.of(station.id, Instant.now() + ";" + temperature);
});
}
@Outgoing("weather-stations") (3)
public Multi<Record<Integer, String>> weatherStations() {
return Multi.createFrom().items(stations.stream()
.map(s -> Record.of(
s.id,
"{ \"id\" : " + s.id +
", \"name\" : \"" + s.name + "\" }"))
);
}
private static class WeatherStation {
int id;
String name;
int averageTemperature;
public WeatherStation(int id, String name, int averageTemperature) {
this.id = id;
this.name = name;
this.averageTemperature = averageTemperature;
}
}
}| 1 | Instruct Reactive Messaging to dispatch the items from the returned Multi to temperature-values. |
| 2 | The method returns a Mutiny stream (Multi) emitting a random temperature value every 0.5 seconds. |
| 3 | Instruct Reactive Messaging to dispatch the items from the returned Multi (static list of weather stations) to weather-stations. |
这两种方法各自返回一个 reactive stream,其项目会分别发送到名为 temperature-values 和 weather-stations 的流中。
The two methods each return a reactive stream whose items are sent to the streams named temperature-values and weather-stations, respectively.
Topic Configuration
这两个通道使用 Quarkus 配置文件 application.properties 映射到 Kafka 主题。为此,将以下内容添加到文件 producer/src/main/resources/application.properties 中:
The two channels are mapped to Kafka topics using the Quarkus configuration file application.properties.
For that, add the following to the file producer/src/main/resources/application.properties:
# Configure the Kafka broker location
kafka.bootstrap.servers=localhost:9092
mp.messaging.outgoing.temperature-values.connector=smallrye-kafka
mp.messaging.outgoing.temperature-values.key.serializer=org.apache.kafka.common.serialization.IntegerSerializer
mp.messaging.outgoing.temperature-values.value.serializer=org.apache.kafka.common.serialization.StringSerializer
mp.messaging.outgoing.weather-stations.connector=smallrye-kafka
mp.messaging.outgoing.weather-stations.key.serializer=org.apache.kafka.common.serialization.IntegerSerializer
mp.messaging.outgoing.weather-stations.value.serializer=org.apache.kafka.common.serialization.StringSerializer这配置了 Kafka 引导服务器、两个主题以及相应的 (de-) 序列化器。有关不同配置选项的更多详细信息,请访问 Kafka 文档中的 Producer configuration 和 Consumer configuration 部分。
This configures the Kafka bootstrap server, the two topics and the corresponding (de-)serializers. More details about the different configuration options are available on the Producer configuration and Consumer configuration section from the Kafka documentation.
Creating the Aggregator Maven Project
在生产者应用程序到位后,就可以实现实际的聚合器应用程序了,它将运行 Kafka Streams 管道。像这样创建另一个项目:
With the producer application in place, it’s time to implement the actual aggregator application, which will run the Kafka Streams pipeline. Create another project like so:
Unresolved directive in kafka-streams.adoc - include::{includes}/devtools/create-app.adoc[]
这使用用于 Kafka 流的 Quarkus 扩展和用于 Quarkus REST(以前是 RESTEasy Reactive)的 Jackson 支持创建了 aggregator 项目。
This creates the aggregator project with the Quarkus extension for Kafka Streams and with the Jackson support for Quarkus REST (formerly RESTEasy Reactive).
如果你已经配置了你的 Quarkus 项目,你可以在项目基本目录中运行以下命令,向你的项目添加 kafka-streams 扩展:
If you already have your Quarkus project configured, you can add the kafka-streams extension
to your project by running the following command in your project base directory:
Unresolved directive in kafka-streams.adoc - include::{includes}/devtools/extension-add.adoc[]
这会将以下内容添加到您的 pom.xml:
This will add the following to your pom.xml:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-kafka-streams</artifactId>
</dependency>implementation("io.quarkus:quarkus-kafka-streams")The Pipeline Implementation
让我们通过创建一些值对象来表示温度测量值、气象站以及跟踪聚合值来开始实现流处理应用程序。
Let’s begin the implementation of the stream processing application by creating a few value objects for representing temperature measurements, weather stations and for keeping track of aggregated values.
首先,使用以下内容创建一个 aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStation.java 文件,表示一个气象站:
First, create the file aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStation.java,
representing a weather station, with the following content:
package org.acme.kafka.streams.aggregator.model;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection (1)
public class WeatherStation {
public int id;
public String name;
}| 1 | The @RegisterForReflection annotation instructs Quarkus to keep the class and its members during the native compilation. More details about the @RegisterForReflection annotation can be found on the native application tips page. |
然后使用以下内容创建一个 aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/TemperatureMeasurement.java 文件,表示给定站点的温度测量值:
Then the file aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/TemperatureMeasurement.java,
representing temperature measurements for a given station:
package org.acme.kafka.streams.aggregator.model;
import java.time.Instant;
public class TemperatureMeasurement {
public int stationId;
public String stationName;
public Instant timestamp;
public double value;
public TemperatureMeasurement(int stationId, String stationName, Instant timestamp,
double value) {
this.stationId = stationId;
this.stationName = stationName;
this.timestamp = timestamp;
this.value = value;
}
}最后是 aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/Aggregation.java,它用于在流式管道中处理事件时跟踪聚合值:
And finally aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/Aggregation.java,
which will be used to keep track of the aggregated values while the events are processed in the streaming pipeline:
package org.acme.kafka.streams.aggregator.model;
import java.math.BigDecimal;
import java.math.RoundingMode;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection
public class Aggregation {
public int stationId;
public String stationName;
public double min = Double.MAX_VALUE;
public double max = Double.MIN_VALUE;
public int count;
public double sum;
public double avg;
public Aggregation updateFrom(TemperatureMeasurement measurement) {
stationId = measurement.stationId;
stationName = measurement.stationName;
count++;
sum += measurement.value;
avg = BigDecimal.valueOf(sum / count)
.setScale(1, RoundingMode.HALF_UP).doubleValue();
min = Math.min(min, measurement.value);
max = Math.max(max, measurement.value);
return this;
}
}接下来,让我们在 aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/TopologyProducer.java 文件中创建实际的流式查询实现。我们需要做的就是声明一个返还 Kafka 流 Topology;Quarkus 扩展将负责配置、启动和停止实际的 Kafka 流引擎的 CDI 生产程序方法。
Next, let’s create the actual streaming query implementation itself in the aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/TopologyProducer.java file.
All we need to do for that is to declare a CDI producer method which returns the Kafka Streams Topology;
the Quarkus extension will take care of configuring, starting and stopping the actual Kafka Streams engine.
package org.acme.kafka.streams.aggregator.streams;
import java.time.Instant;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.inject.Produces;
import org.acme.kafka.streams.aggregator.model.Aggregation;
import org.acme.kafka.streams.aggregator.model.TemperatureMeasurement;
import org.acme.kafka.streams.aggregator.model.WeatherStation;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.GlobalKTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueBytesStoreSupplier;
import org.apache.kafka.streams.state.Stores;
import io.quarkus.kafka.client.serialization.ObjectMapperSerde;
@ApplicationScoped
public class TopologyProducer {
static final String WEATHER_STATIONS_STORE = "weather-stations-store";
private static final String WEATHER_STATIONS_TOPIC = "weather-stations";
private static final String TEMPERATURE_VALUES_TOPIC = "temperature-values";
private static final String TEMPERATURES_AGGREGATED_TOPIC = "temperatures-aggregated";
@Produces
public Topology buildTopology() {
StreamsBuilder builder = new StreamsBuilder();
ObjectMapperSerde<WeatherStation> weatherStationSerde = new ObjectMapperSerde<>(
WeatherStation.class);
ObjectMapperSerde<Aggregation> aggregationSerde = new ObjectMapperSerde<>(Aggregation.class);
KeyValueBytesStoreSupplier storeSupplier = Stores.persistentKeyValueStore(
WEATHER_STATIONS_STORE);
GlobalKTable<Integer, WeatherStation> stations = builder.globalTable( (1)
WEATHER_STATIONS_TOPIC,
Consumed.with(Serdes.Integer(), weatherStationSerde));
builder.stream( (2)
TEMPERATURE_VALUES_TOPIC,
Consumed.with(Serdes.Integer(), Serdes.String())
)
.join( (3)
stations,
(stationId, timestampAndValue) -> stationId,
(timestampAndValue, station) -> {
String[] parts = timestampAndValue.split(";");
return new TemperatureMeasurement(station.id, station.name,
Instant.parse(parts[0]), Double.valueOf(parts[1]));
}
)
.groupByKey() (4)
.aggregate( (5)
Aggregation::new,
(stationId, value, aggregation) -> aggregation.updateFrom(value),
Materialized.<Integer, Aggregation> as(storeSupplier)
.withKeySerde(Serdes.Integer())
.withValueSerde(aggregationSerde)
)
.toStream()
.to( (6)
TEMPERATURES_AGGREGATED_TOPIC,
Produced.with(Serdes.Integer(), aggregationSerde)
);
return builder.build();
}
}| 1 | The weather-stations table is read into a GlobalKTable, representing the current state of each weather station |
| 2 | The temperature-values topic is read into a KStream; whenever a new message arrives to this topic, the pipeline will be processed for this measurement |
| 3 | The message from the temperature-values topic is joined with the corresponding weather station, using the topic’s key (weather station id); the join result contains the data from the measurement and associated weather station message |
| 4 | The values are grouped by message key (the weather station id) |
| 5 | Within each group, all the measurements of that station are aggregated, by keeping track of minimum and maximum values and calculating the average value of all measurements of that station (see the Aggregation type) |
| 6 | The results of the pipeline are written out to the temperatures-aggregated topic |
通过 Quarkus 配置文件 application.properties 配置 Kafka 流扩展。使用以下内容创建文件 aggregator/src/main/resources/application.properties:
The Kafka Streams extension is configured via the Quarkus configuration file application.properties.
Create the file aggregator/src/main/resources/application.properties with the following contents:
quarkus.kafka-streams.bootstrap-servers=localhost:9092
quarkus.kafka-streams.application-server=${hostname}:8080
quarkus.kafka-streams.topics=weather-stations,temperature-values
# pass-through options
kafka-streams.cache.max.bytes.buffering=10240
kafka-streams.commit.interval.ms=1000
kafka-streams.metadata.max.age.ms=500
kafka-streams.auto.offset.reset=earliest
kafka-streams.metrics.recording.level=DEBUG具有 quarkus.kafka-streams 前缀的选项可以在应用程序启动时动态更改,例如,通过环境变量或系统属性。bootstrap-servers 和 application-server 分别映射到 Kafka 流属性 bootstrap.servers 和 application.server。topics 特定于 Quarkus:应用程序会在启动 Kafka 流引擎之前等待所有给定主题存在。这样做是为了在应用程序启动时优雅地等待尚未存在的主题的创建。
The options with the quarkus.kafka-streams prefix can be changed dynamically at application startup,
e.g. via environment variables or system properties.
bootstrap-servers and application-server are mapped to the Kafka Streams properties bootstrap.servers and application.server, respectively.
topics is specific to Quarkus: the application will wait for all the given topics to exist before launching the Kafka Streams engine.
This is to done to gracefully await the creation of topics that don’t yet exist at application startup time.
|
或者,您可以使用 |
|
Alternatively, you can use |
|
一旦您准备好将您的应用程序推广到生产环境中,请考虑更改上述配置值。虽然 Once you are ready to promote your application into production, consider changing the above configuration values. While |
kafka-streams 命名空间中的所有属性会按原样传递到 Kafka 流引擎。更改其值需要重新构建应用程序。
All the properties within the kafka-streams namespace are passed through as-is to the Kafka Streams engine.
Changing their values requires a rebuild of the application.
Building and Running the Applications
我们现在可以构建 producer 和 aggregator 应用程序:
We now can build the producer and aggregator applications:
./mvnw clean package -f producer/pom.xml
./mvnw clean package -f aggregator/pom.xml我们不会使用 Quarkus 开发模式直接在主机机器上运行它们,而是将它们打包到容器映像中,并通过 Docker Compose 启动它们。这样做是为了演示如何将 aggregator 聚合扩展到多个节点。
Instead of running them directly on the host machine using the Quarkus dev mode,
we’re going to package them into container images and launch them via Docker Compose.
This is done in order to demonstrate scaling the aggregator aggregation to multiple nodes later on.
Quarkus 创建的 Dockerfile 默认需要对 aggregator 应用程序进行一项调整,以便运行 Kafka 流管道。为此,请编辑文件 aggregator/src/main/docker/Dockerfile.jvm 并将 FROM fabric8/java-alpine-openjdk8-jre 行替换为 FROM fabric8/java-centos-openjdk8-jdk。
The Dockerfile created by Quarkus by default needs one adjustment for the aggregator application in order to run the Kafka Streams pipeline.
To do so, edit the file aggregator/src/main/docker/Dockerfile.jvm and replace the line FROM fabric8/java-alpine-openjdk8-jre with FROM fabric8/java-centos-openjdk8-jdk.
接下来,创建一个 Docker Compose 文件(docker-compose.yaml)来启动这两个应用程序以及 Apache Kafka 和 ZooKeeper,如下所示:
Next create a Docker Compose file (docker-compose.yaml) for spinning up the two applications as well as Apache Kafka and ZooKeeper like so:
version: '3.5'
services:
zookeeper:
image: quay.io/strimzi/kafka:0.41.0-kafka-3.7.0
command: [
"sh", "-c",
"bin/zookeeper-server-start.sh config/zookeeper.properties"
]
ports:
- "2181:2181"
environment:
LOG_DIR: /tmp/logs
networks:
- kafkastreams-network
kafka:
image: quay.io/strimzi/kafka:0.41.0-kafka-3.7.0
command: [
"sh", "-c",
"bin/kafka-server-start.sh config/server.properties --override listeners=$${KAFKA_LISTENERS} --override advertised.listeners=$${KAFKA_ADVERTISED_LISTENERS} --override zookeeper.connect=$${KAFKA_ZOOKEEPER_CONNECT} --override num.partitions=$${KAFKA_NUM_PARTITIONS}"
]
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
LOG_DIR: "/tmp/logs"
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_NUM_PARTITIONS: 3
networks:
- kafkastreams-network
producer:
image: quarkus-quickstarts/kafka-streams-producer:1.0
build:
context: producer
dockerfile: src/main/docker/Dockerfile.${QUARKUS_MODE:-jvm}
environment:
KAFKA_BOOTSTRAP_SERVERS: kafka:9092
networks:
- kafkastreams-network
aggregator:
image: quarkus-quickstarts/kafka-streams-aggregator:1.0
build:
context: aggregator
dockerfile: src/main/docker/Dockerfile.${QUARKUS_MODE:-jvm}
environment:
QUARKUS_KAFKA_STREAMS_BOOTSTRAP_SERVERS: kafka:9092
networks:
- kafkastreams-network
networks:
kafkastreams-network:
name: ks要启动所有容器、构建 producer 和 aggregator 容器映像,请运行 docker-compose up --build。
To launch all the containers, building the producer and aggregator container images,
run docker-compose up --build.
|
您可以使用 |
|
Instead of |
您应该能看到 producer 应用的日志记录发送到"temperature-values"主题的消息。
You should see log statements from the producer application about messages being sent to the "temperature-values" topic.
现在运行 debezium/tooling 镜像的实例,附着到所有其他容器运行的相同网络。此镜像提供多个有用工具,如 kafkacat 和 httpie:
Now run an instance of the debezium/tooling image, attaching to the same network all the other containers run in. This image provides several useful tools such as kafkacat and httpie:
docker run --tty --rm -i --network ks debezium/tooling:1.1在工具容器内,运行 kafkacat 检查流式处理管道运行结果:
Within the tooling container, run kafkacat to examine the results of the streaming pipeline:
kafkacat -b kafka:9092 -C -o beginning -q -t temperatures-aggregated
{"avg":34.7,"count":4,"max":49.4,"min":16.8,"stationId":9,"stationName":"Marrakesh","sum":138.8}
{"avg":15.7,"count":1,"max":15.7,"min":15.7,"stationId":2,"stationName":"Snowdonia","sum":15.7}
{"avg":12.8,"count":7,"max":25.5,"min":-13.8,"stationId":7,"stationName":"Porthsmouth","sum":89.7}
...您应该能看到新值不断涌现,因为生产者持续发送温度测量值,每个传出主题值显示所代表气象站的最小、最大和平均温度值。
You should see new values arrive as the producer continues to emit temperature measurements, each value on the outbound topic showing the minimum, maximum and average temperature values of the represented weather station.
Interactive Queries
订阅 temperatures-aggregated 主题是响应任何新温度值的好方法。如果您只对给定气象站的最新聚合值感兴趣,那会有点浪费。这正是 Kafka Streams 交互式查询发挥作用的地方:它们让您直接查询管道的底层状态存储以获取与给定键关联的值。通过公开查询状态存储的简单 REST 端点,无需订阅任何 Kafka 主题即可检索最新聚合结果。
Subscribing to the temperatures-aggregated topic is a great way to react to any new temperature values.
It’s a bit wasteful though if you’re just interested in the latest aggregated value for a given weather station.
This is where Kafka Streams interactive queries shine:
they let you directly query the underlying state store of the pipeline for the value associated to a given key.
By exposing a simple REST endpoint which queries the state store,
the latest aggregation result can be retrieved without having to subscribe to any Kafka topic.
让我们从在文件 aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/InteractiveQueries.java 中创建一个新类 InteractiveQueries 开始:
Let’s begin by creating a new class InteractiveQueries in the file aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/InteractiveQueries.java:
向 KafkaStreamsPipeline 类添加一个新方法,该方法获取给定键的当前状态:
one more method to the KafkaStreamsPipeline class which obtains the current state for a given key:
package org.acme.kafka.streams.aggregator.streams;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import org.acme.kafka.streams.aggregator.model.Aggregation;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.errors.InvalidStateStoreException;
import org.apache.kafka.streams.state.QueryableStoreTypes;
import org.apache.kafka.streams.state.ReadOnlyKeyValueStore;
@ApplicationScoped
public class InteractiveQueries {
@Inject
KafkaStreams streams;
public GetWeatherStationDataResult getWeatherStationData(int id) {
Aggregation result = getWeatherStationStore().get(id);
if (result != null) {
return GetWeatherStationDataResult.found(WeatherStationData.from(result)); (1)
}
else {
return GetWeatherStationDataResult.notFound(); (2)
}
}
private ReadOnlyKeyValueStore<Integer, Aggregation> getWeatherStationStore() {
while (true) {
try {
return streams.store(TopologyProducer.WEATHER_STATIONS_STORE, QueryableStoreTypes.keyValueStore());
} catch (InvalidStateStoreException e) {
// ignore, store not ready yet
}
}
}
}| 1 | A value for the given station id was found, so that value will be returned |
| 2 | No value was found, either because a non-existing station was queried or no measurement exists yet for the given station |
还可以在文件 aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/GetWeatherStationDataResult.java 中创建该方法的返回类型:
Also create the method’s return type in the file aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/GetWeatherStationDataResult.java:
package org.acme.kafka.streams.aggregator.streams;
import java.util.Optional;
import java.util.OptionalInt;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
public class GetWeatherStationDataResult {
private static GetWeatherStationDataResult NOT_FOUND =
new GetWeatherStationDataResult(null);
private final WeatherStationData result;
private GetWeatherStationDataResult(WeatherStationData result) {
this.result = result;
}
public static GetWeatherStationDataResult found(WeatherStationData data) {
return new GetWeatherStationDataResult(data);
}
public static GetWeatherStationDataResult notFound() {
return NOT_FOUND;
}
public Optional<WeatherStationData> getResult() {
return Optional.ofNullable(result);
}
}还创建 aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStationData.java,表示某气象站的实际聚合结果:
Also create aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStationData.java,
which represents the actual aggregation result for a weather station:
package org.acme.kafka.streams.aggregator.model;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection
public class WeatherStationData {
public int stationId;
public String stationName;
public double min = Double.MAX_VALUE;
public double max = Double.MIN_VALUE;
public int count;
public double avg;
private WeatherStationData(int stationId, String stationName, double min, double max,
int count, double avg) {
this.stationId = stationId;
this.stationName = stationName;
this.min = min;
this.max = max;
this.count = count;
this.avg = avg;
}
public static WeatherStationData from(Aggregation aggregation) {
return new WeatherStationData(
aggregation.stationId,
aggregation.stationName,
aggregation.min,
aggregation.max,
aggregation.count,
aggregation.avg);
}
}我们现在可以添加一个简单的 REST 端点 (aggregator/src/main/java/org/acme/kafka/streams/aggregator/rest/WeatherStationEndpoint.java),该端点调用 getWeatherStationData() 并向客户端返回数据:
We now can add a simple REST endpoint (aggregator/src/main/java/org/acme/kafka/streams/aggregator/rest/WeatherStationEndpoint.java),
which invokes getWeatherStationData() and returns the data to the client:
package org.acme.kafka.streams.aggregator.rest;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.List;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.core.Response.Status;
import org.acme.kafka.streams.aggregator.streams.GetWeatherStationDataResult;
import org.acme.kafka.streams.aggregator.streams.KafkaStreamsPipeline;
@ApplicationScoped
@Path("/weather-stations")
public class WeatherStationEndpoint {
@Inject
InteractiveQueries interactiveQueries;
@GET
@Path("/data/{id}")
public Response getWeatherStationData(int id) {
GetWeatherStationDataResult result = interactiveQueries.getWeatherStationData(id);
if (result.getResult().isPresent()) { (1)
return Response.ok(result.getResult().get()).build();
}
else {
return Response.status(Status.NOT_FOUND.getStatusCode(),
"No data found for weather station " + id).build();
}
}
}| 1 | Depending on whether a value was obtained, either return that value or a 404 response |
有了此代码,是时候在 Docker Compose 中重新构建应用和 aggregator 服务了:
With this code in place, it’s time to rebuild the application and the aggregator service in Docker Compose:
./mvnw clean package -f aggregator/pom.xml
docker-compose stop aggregator
docker-compose up --build -d这将重新构建 aggregator 容器并重启其服务。完成后,您可以调用该服务的 REST API 以获取现有某个站点温度数据。为此,您可以在之前启动的工具容器中使用 httpie:
This will rebuild the aggregator container and restart its service.
Once that’s done, you can invoke the service’s REST API to obtain the temperature data for one of the existing stations.
To do so, you can use httpie in the tooling container launched before:
http aggregator:8080/weather-stations/data/1
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 85
Content-Type: application/json
Date: Tue, 18 Jun 2019 19:29:16 GMT
{
"avg": 12.9,
"count": 146,
"max": 41.0,
"min": -25.6,
"stationId": 1,
"stationName": "Hamburg"
}Scaling Out
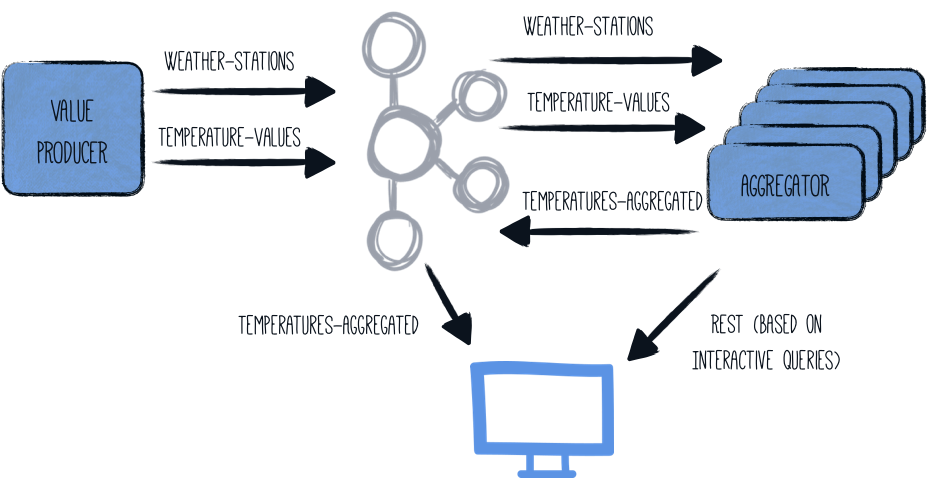
Kafka Streams 应用的一个非常有趣的特性是它们可以扩展,即负载和状态可以在运行相同管道的多个应用实例中分配。然后,每个节点都将包含聚合结果的一个子集,但 Kafka Streams 为您提供了 an API,以获取给定键位于哪个节点的信息。然后,该应用可以直接从另一个实例获取数据,或者只将客户端指向该另一个节点的位置。
A very interesting trait of Kafka Streams applications is that they can be scaled out, i.e. the load and state can be distributed amongst multiple application instances running the same pipeline. Each node will then contain a subset of the aggregation results, but Kafka Streams provides you with an API to obtain the information which node is hosting a given key. The application can then either fetch the data directly from the other instance, or simply point the client to the location of that other node.
启动 aggregator 应用的多个实例将使整体架构看起来像这样:
Launching multiple instances of the aggregator application will make look the overall architecture like so:
InteractiveQueries 类必须针对此分布式架构稍作调整:
The InteractiveQueries class must be adjusted slightly for this distributed architecture:
public GetWeatherStationDataResult getWeatherStationData(int id) {
StreamsMetadata metadata = streams.metadataForKey( (1)
TopologyProducer.WEATHER_STATIONS_STORE,
id,
Serdes.Integer().serializer()
);
if (metadata == null || metadata == StreamsMetadata.NOT_AVAILABLE) {
LOG.warn("Found no metadata for key {}", id);
return GetWeatherStationDataResult.notFound();
}
else if (metadata.host().equals(host)) { (2)
LOG.info("Found data for key {} locally", id);
Aggregation result = getWeatherStationStore().get(id);
if (result != null) {
return GetWeatherStationDataResult.found(WeatherStationData.from(result));
}
else {
return GetWeatherStationDataResult.notFound();
}
}
else { (3)
LOG.info(
"Found data for key {} on remote host {}:{}",
id,
metadata.host(),
metadata.port()
);
return GetWeatherStationDataResult.foundRemotely(metadata.host(), metadata.port());
}
}
public List<PipelineMetadata> getMetaData() { (4)
return streams.allMetadataForStore(TopologyProducer.WEATHER_STATIONS_STORE)
.stream()
.map(m -> new PipelineMetadata(
m.hostInfo().host() + ":" + m.hostInfo().port(),
m.topicPartitions()
.stream()
.map(TopicPartition::toString)
.collect(Collectors.toSet()))
)
.collect(Collectors.toList());
}| 1 | The streams metadata for the given weather station id is obtained |
| 2 | The given key (weather station id) is maintained by the local application node, i.e. it can answer the query itself |
| 3 | The given key is maintained by another application node; in this case the information about that node (host and port) will be returned |
| 4 | The getMetaData() method is added to provide callers with a list of all the nodes in the application cluster. |
GetWeatherStationDataResult 类型必须相应地进行调整:
The GetWeatherStationDataResult type must be adjusted accordingly:
package org.acme.kafka.streams.aggregator.streams;
import java.util.Optional;
import java.util.OptionalInt;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
public class GetWeatherStationDataResult {
private static GetWeatherStationDataResult NOT_FOUND =
new GetWeatherStationDataResult(null, null, null);
private final WeatherStationData result;
private final String host;
private final Integer port;
private GetWeatherStationDataResult(WeatherStationData result, String host,
Integer port) {
this.result = result;
this.host = host;
this.port = port;
}
public static GetWeatherStationDataResult found(WeatherStationData data) {
return new GetWeatherStationDataResult(data, null, null);
}
public static GetWeatherStationDataResult foundRemotely(String host, int port) {
return new GetWeatherStationDataResult(null, host, port);
}
public static GetWeatherStationDataResult notFound() {
return NOT_FOUND;
}
public Optional<WeatherStationData> getResult() {
return Optional.ofNullable(result);
}
public Optional<String> getHost() {
return Optional.ofNullable(host);
}
public OptionalInt getPort() {
return port != null ? OptionalInt.of(port) : OptionalInt.empty();
}
}此外,必须定义 getMetaData() 的返回类型(aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/PipelineMetadata.java):
Also, the return type for getMetaData() must be defined
(aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/PipelineMetadata.java):
package org.acme.kafka.streams.aggregator.streams;
import java.util.Set;
public class PipelineMetadata {
public String host;
public Set<String> partitions;
public PipelineMetadata(String host, Set<String> partitions) {
this.host = host;
this.partitions = partitions;
}
}最后,必须更新 REST 端点类:
Lastly, the REST endpoint class must be updated:
package org.acme.kafka.streams.aggregator.rest;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.List;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.core.Response.Status;
import org.acme.kafka.streams.aggregator.streams.GetWeatherStationDataResult;
import org.acme.kafka.streams.aggregator.streams.KafkaStreamsPipeline;
import org.acme.kafka.streams.aggregator.streams.PipelineMetadata;
@ApplicationScoped
@Path("/weather-stations")
public class WeatherStationEndpoint {
@Inject
InteractiveQueries interactiveQueries;
@GET
@Path("/data/{id}")
@Consumes(MediaType.APPLICATION_JSON)
@Produces(MediaType.APPLICATION_JSON)
public Response getWeatherStationData(int id) {
GetWeatherStationDataResult result = interactiveQueries.getWeatherStationData(id);
if (result.getResult().isPresent()) { (1)
return Response.ok(result.getResult().get()).build();
}
else if (result.getHost().isPresent()) { (2)
URI otherUri = getOtherUri(result.getHost().get(), result.getPort().getAsInt(),
id);
return Response.seeOther(otherUri).build();
}
else { (3)
return Response.status(Status.NOT_FOUND.getStatusCode(),
"No data found for weather station " + id).build();
}
}
@GET
@Path("/meta-data")
@Produces(MediaType.APPLICATION_JSON)
public List<PipelineMetadata> getMetaData() { (4)
return interactiveQueries.getMetaData();
}
private URI getOtherUri(String host, int port, int id) {
try {
return new URI("http://" + host + ":" + port + "/weather-stations/data/" + id);
}
catch (URISyntaxException e) {
throw new RuntimeException(e);
}
}
}| 1 | The data was found locally, so return it |
| 2 | The data is maintained by another node, so reply with a redirect (HTTP status code 303) if the data for the given key is stored on one of the other nodes. |
| 3 | No data was found for the given weather station id |
| 4 | Exposes information about all the hosts forming the application cluster |
现在重新停止 aggregator 服务并重新编译它。然后让我们启动三个实例:
Now stop the aggregator service again and rebuild it.
Then let’s spin up three instances of it:
./mvnw clean package -f aggregator/pom.xml
docker-compose stop aggregator
docker-compose up --build -d --scale aggregator=3在三个实例中的任何一个上调用 REST API 时,请求的气象站 id 聚合可能存储在接收查询的节点上,或者可能存储在另外两个节点中的一个上。
When invoking the REST API on any of the three instances, it might either be that the aggregation for the requested weather station id is stored locally on the node receiving the query, or it could be stored on one of the other two nodes.
由于 Docker Compose 的负载平衡器将以循环方式将请求分发给 aggregator 服务,因此我们将直接调用实际节点。该应用程序通过 REST 公开有关所有主机名的信息:
As the load balancer of Docker Compose will distribute requests to the aggregator service in a round-robin fashion,
we’ll invoke the actual nodes directly.
The application exposes information about all the host names via REST:
http aggregator:8080/weather-stations/meta-data
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 202
Content-Type: application/json
Date: Tue, 18 Jun 2019 20:00:23 GMT
[
{
"host": "2af13fe516a9:8080",
"partitions": [
"temperature-values-2"
]
},
{
"host": "32cc8309611b:8080",
"partitions": [
"temperature-values-1"
]
},
{
"host": "1eb39af8d587:8080",
"partitions": [
"temperature-values-0"
]
}
]从响应中显示的三个主机之一中检索数据(您的实际主机名将有所不同):
Retrieve the data from one of the three hosts shown in the response (your actual host names will differ):
http 2af13fe516a9:8080/weather-stations/data/1如果该节点持有键“1”的数据,您将得到如下的响应:
If that node holds the data for key "1", you’ll get a response like this:
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 74
Content-Type: application/json
Date: Tue, 11 Jun 2019 19:16:31 GMT
{
"avg": 11.9,
"count": 259,
"max": 50.0,
"min": -30.1,
"stationId": 1,
"stationName": "Hamburg"
}否则,该服务将发送重定向:
Otherwise, the service will send a redirect:
HTTP/1.1 303 See Other
Connection: keep-alive
Content-Length: 0
Date: Tue, 18 Jun 2019 20:01:03 GMT
Location: http://1eb39af8d587:8080/weather-stations/data/1通过传递 --follow option ,您还可以让 httpie 自动遵循重定向:
You can also have httpie automatically follow the redirect by passing the --follow option:
http --follow 2af13fe516a9:8080/weather-stations/data/1Running Natively
适用于 Kafka Streams 的 Quarkus 扩展通过 GraalVM 以本机方式启用流处理应用程序的执行,而无需进一步配置。
The Quarkus extension for Kafka Streams enables the execution of stream processing applications natively via GraalVM without further configuration.
若要在本机模式下运行 producer 和 aggregator 应用程序,可以使用 -Dnative 执行 Maven 构建:
To run both the producer and aggregator applications in native mode,
the Maven builds can be executed using -Dnative:
./mvnw clean package -f producer/pom.xml -Dnative -Dnative-image.container-runtime=docker
./mvnw clean package -f aggregator/pom.xml -Dnative -Dnative-image.container-runtime=docker现在创建一个名为 QUARKUS_MODE 的环境变量,并将值设置为“native”:
Now create an environment variable named QUARKUS_MODE and with value set to "native":
export QUARKUS_MODE=nativeDocker Compose 文件使用此变量在构建 producer 和 aggregator 映像时使用正确的 Dockerfile。Kafka Streams 应用程序在 native 模式下可以使用少于 50 MB 的 RSS。为此,将 Xmx 选项添加到 aggregator/src/main/docker/Dockerfile.native 中的程序调用中:
This is used by the Docker Compose file to use the correct Dockerfile when building the producer and aggregator images.
The Kafka Streams application can work with less than 50 MB RSS in native mode.
To do so, add the Xmx option to the program invocation in aggregator/src/main/docker/Dockerfile.native:
CMD ["./application", "-Dquarkus.http.host=0.0.0.0", "-Xmx32m"]现在按照上述说明启动 Docker Compose(别忘了重新构建容器映像)。
Now start Docker Compose as described above (don’t forget to rebuild the container images).
Kafka Streams Health Checks
如果你使用 quarkus-smallrye-health 扩展,quarkus-kafka-streams 将自动添加:
If you are using the quarkus-smallrye-health extension, quarkus-kafka-streams will automatically add:
-
a readiness health check to validate that all topics declared in the
quarkus.kafka-streams.topicsproperty are created, -
a liveness health check based on the Kafka Streams state.
因此,当你访问应用程序的 /q/health 端点时,你将获得有关 Kafka Streams 状态以及可用和/或缺少主题的信息。
So when you access the /q/health endpoint of your application you will have information about the state of the Kafka Streams and the available and/or missing topics.
以下是在状态为 DOWN 时的一个示例:
This is an example of when the status is DOWN:
curl -i http://aggregator:8080/q/health
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 454
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams state health check", 1
"status": "DOWN",
"data": {
"state": "CREATED"
}
},
{
"name": "Kafka Streams topics health check", 2
"status": "DOWN",
"data": {
"available_topics": "weather-stations,temperature-values",
"missing_topics": "hygrometry-values"
}
}
]
}| 1 | Liveness health check. Also available at /q/health/live endpoint. |
| 2 | Readiness health check. Also available at /q/health/ready endpoint. |
因此,正如你所见,只要缺少了其中一个 quarkus.kafka-streams.topics,或者 Kafka Streams state 不是 RUNNING,状态就是 DOWN。
So as you can see, the status is DOWN as soon as one of the quarkus.kafka-streams.topics is missing or the Kafka Streams state is not RUNNING.
如果没有可用主题,available_topics 键将不会出现在 Kafka Streams topics health check 的 data 字段中。同样,如果没有缺少主题,missing_topics 键将不会出现在 Kafka Streams topics health check 的 data 字段中。
If no topics are available, the available_topics key will not be present in the data field of the Kafka Streams topics health check.
As well as if no topics are missing, the missing_topics key will not be present in the data field of the Kafka Streams topics health check.
你当然可以通过在 application.properties 中将 quarkus.kafka-streams.health.enabled 属性设置为 false 来禁用 quarkus-kafka-streams 扩展的运行状况检查。
You can of course disable the health check of the quarkus-kafka-streams extension by setting the quarkus.kafka-streams.health.enabled property to false in your application.properties.
显然,你可以根据各自的端点 /q/health/live 和 /q/health/ready 来创建你的正常运行状况和就绪性探测。
Obviously you can create your liveness and readiness probes based on the respective endpoints /q/health/live and /q/health/ready.
Liveness health check
以下是用例运行状况检查示例:
Here is an example of the liveness check:
curl -i http://aggregator:8080/q/health/live
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 225
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams state health check",
"status": "DOWN",
"data": {
"state": "CREATED"
}
}
]
}state 来自 KafkaStreams.State 枚举。
The state is coming from the KafkaStreams.State enum.
Readiness health check
以下是用例就绪性检查示例:
Here is an example of the readiness check:
curl -i http://aggregator:8080/q/health/ready
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 265
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams topics health check",
"status": "DOWN",
"data": {
"missing_topics": "weather-stations,temperature-values"
}
}
]
}Going Further
本指南展示了如何使用 Quarkus 和 Kafka Streams API 在 JVM 和 native 模式下构建流处理应用程序。为了在生产环境中运行你的 KStreams 应用程序,你还可以为数据管道添加运行状况检查和指标。请参考 Quarkus 指南中的 Micrometer、SmallRye Metrics 和 SmallRye Health,了解更多信息。
This guide has shown how you can build stream processing applications using Quarkus and the Kafka Streams APIs, both in JVM and native modes. For running your KStreams application in production, you could also add health checks and metrics for the data pipeline. Refer to the Quarkus guides on Micrometer, SmallRye Metrics, and SmallRye Health to learn more.