Selenium 简明教程
Selenium WebDriver - Handling Links
Selenium Webdriver 可用于处理网页上的链接。在 * HTML* 术语中,每个链接(称为超链接)都由称为锚的标记名标识。此外,网页上的每个链接都有一个名为 href 的属性。
Selenium Webdriver can be used to handle links on a web page. In HTML terminology, every link (referred to as hyperlinks) are identified by the tagname called anchor. Also, each link on a webpage has an attribute called href.
Identify of Links in HTML
现在让我们讨论超链接 * anchor tags* 的 Created 标识,如下面的图片所示。右键单击该网页,然后单击 Chrome 浏览器中的检查按钮。之后,整个页面的相应 HTML 代码将可见。要检查页面上的创建链接,请单击如下面突出显示的左上角箭头。
Let us now discuss the identification of anchor tags for hyperlink - Created on a webpage shown in the below image. Right click on the webpage, and then click on the Inspect button in the Chrome browser. After that, the corresponding HTML code for the whole page would be visible. For investigating the Created link on a page, click on the left upward arrow as highlighted below.

一旦我们单击并将箭头指向创建超链接,其 HTML 代码将可见。
Once, we had clicked and pointed the arrow to the Created hyperlink, its HTML code was visible.

可以在 Selenium 中使用链接文本定位符来标识链接。将标识与链接文本匹配值匹配的第一个元素。
A link can be identified using the link text locator in Selenium. The first element with the matching value of the link text is identified.
Handle Links with Link Text Locator
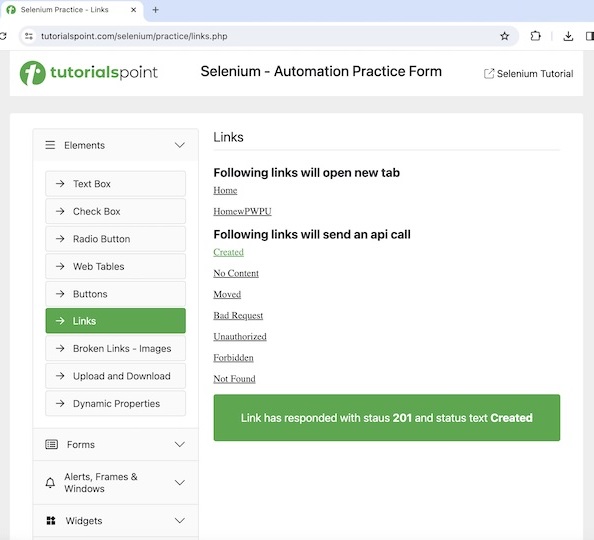
让我们来看上述页面的示例,单击创建链接后,将在页面上看到文本 Link has responded with status 201 and status text Created 。
Let us take an example of the above page, where on clicking the Created link, the text Link has responded with status 201 and status text Created would be visible on the page.
Example
package org.example;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.concurrent.TimeUnit;
public class HandLinks {
public static void main(String[] args) throws InterruptedException {
// Initiate the Webdriver
WebDriver driver = new ChromeDriver();
// adding implicit wait of 15 secs
driver.manage().timeouts().implicitlyWait(15, TimeUnit.SECONDS);
// Opening the webpage where we will identify an element
driver.get
("https://www.tutorialspoint.com/selenium/practice/links.php");
// identify link with link text locator then click
WebElement l = driver.findElement(By.linkText("Created"));
l.click();
// identify text locator
WebElement t = driver.findElement(By.xpath("/html/body/main/div/div/div[2]/div[1]"));
System.out.println("Text appeared is: " + t.getText());
// Closing browser
driver.quit();
}
}Text appeared is: Link has responded with status 201 and status text Created
Process finished with exit code 0在上述示例中,在带有消息的链接 Created 上执行单击后获得的文本为 Link has responded with status 201 and status text Created 。
In the above example, the text obtained after performing the click on the link Created with a message was Link has responded with status 201 and status text Created.
最后,收到了消息 Process finished with exit code 0 ,表示代码成功执行。
Finally, the message Process finished with exit code 0 was received, signifying successful execution of the code.
Handle Links with Partial Link Text Locator
可以在 Selenium 中使用部分链接文本定位符来标识链接。将标识与部分链接文本匹配值匹配的第一个元素。
A link can be identified using the partial link text locator in Selenium. The first element with the matching value of the partial link text is identified.
Syntax
Webdriver driver = new ChromeDriver();
driver.findElement(By.partialLinkText("value of partial link text"));Example
package org.example;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.concurrent.TimeUnit;
public class HandPartialLinks {
public static void main(String[] args) throws InterruptedException {
// Initiate the Webdriver
WebDriver driver = new ChromeDriver();
// adding implicit wait of 15 secs
driver.manage().timeouts().implicitlyWait(15, TimeUnit.SECONDS);
// Opening the webpage where we will identify an element
driver.get("https://www.tutorialspoint.com/selenium/practice/links.php");
// identify link with partial link text locator then click
WebElement l = driver.findElement(By.partialLinkText("Creat"));
l.click();
// identify text locator
WebElement t = driver.findElement(By.xpath("/html/body/main/div/div/div[2]/div[1]"));
System.out.println("Text appeared is: " + t.getText());
// Closing browser
driver.quit();
}
}Text appeared is: Link has responded with status 201 and status text Created在上述示例中,通过 partial link text 单击该链接后获得的文本(带有消息)为 Link Link has responded with status 201 and status text Created 。
In the above example, the text obtained after performing the click on the link Created(with the help of partial link text) with a message was Link Link has responded with status 201 and status text Created.
Handle Links with Tagname Locator
可以使用 Selenium 中的标签名称定位器来识别链接。具有标签名称匹配值的第一个元素会被识别。
A link can be identified using the tagname locator in Selenium. The first element with the matching value of the tagname is identified.
在上面讨论的示例中,我们单击并指向“已创建”超链接,其 HTML 代码是可见的,反映了锚点标签名称(称为“a”并用 <> 括起)。
In the example, discussed above once, we had clicked and pointed the arrow to the Created hyperlink, its HTML code was visible, reflecting the anchor tagname (referred to as 'a' and enclosed in <>).
<a href="javascript:void(0);" id="created" onclick="shide('create')">Created</a>Syntax
Webdriver driver = new ChromeDriver();
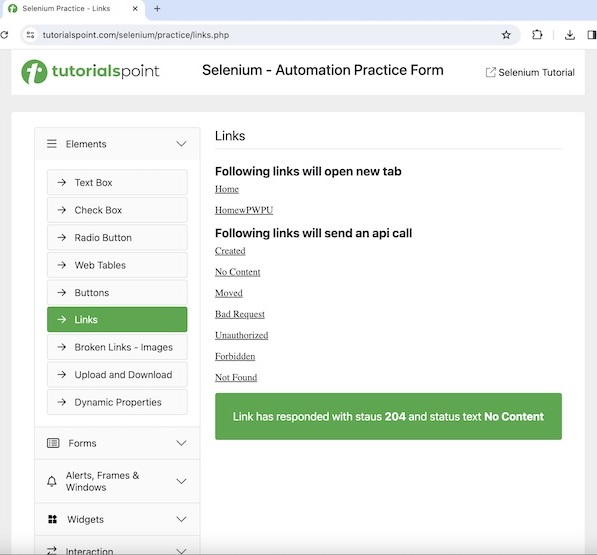
driver.findElement(By.tagName("a”));让我们以同一页面的示例为例,我们首先计算链接的总数,然后我们单击某个特定链接,例如“无内容”。在单击该链接后,我们在页面上获取文本 Link has responded with status 204 and status text 。
Let us take an example of the same page, where we would first count the total number of links, then we would click on a specific link, say the No Content. After clicking on that link, we would get the text as Link has responded with status 204 and status text on the page.
Example
package org.example;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import java.util.concurrent.TimeUnit;
import java.util.List;
public class TotalLinks {
public static void main(String[] args) throws InterruptedException {
// Initiate the Webdriver
WebDriver driver = new ChromeDriver();
// adding implicit wait of 15 secs
driver.manage().timeouts().implicitlyWait(15, TimeUnit.SECONDS);
// Opening the webpage where we will identify an element
driver.get("https://www.tutorialspoint.com/selenium/practice/links.php");
// identify link with link text locator then click
WebElement l = driver.findElement(By.linkText("No Content"));
l.click();
// Retrieve all links using locator By.tagName and storing in List
List<WebElement> totalLnks = driver.findElements(By.tagName("a") );
System.out.println( "Total number of links: " + totalLnks.size() ) ;
// Running loop through list of web elements
for( int j = 0; j < totalLnks.size(); j ++){
if( totalLnks.get(j).getText().equalsIgnoreCase("No Content") ) {
totalLnks.get(j).click();
WebElement t = driver.findElement(By.xpath("/html/body/main/div/div/div[2]/div[2]"));
// get the browser title to confirm navigation after click
System.out.println( "Get text after click: " + t.getText());
break ;
}
}
// Closing browser
driver.quit();
}
}Total number of links: 42
Get text after click: Link has responded with status 204 and status text No Content在上面的示例中,我们在网页上计算了链接的总数,并在控制台中收到了消息 - Total number of links: 42 ,以及在使用消息 Get text after click: Link has responded with status 204 and status text No Content 执行单击后获得的文本。
In the above example, we had counted the total number of links on a web page, and received the messages in the console - Total number of links: 42 and the text obtained after performing the the click with the message Get text after click: Link has responded with status 204 and status text No Content.
Conclusion
这总结了我们对 Selenium Webdriver 处理链接教程的全面了解。我们从描述如何在 HTML 中识别链接开始,并举例说明如何使用 Selenium Webdriver 中的链接文本、部分链接文本和标签名称定位器来处理链接。这使你掌握了 Selenium Webdriver - 处理链接的深入知识。明智的做法是持续实践所学内容,并探索其他与 Selenium 相关的内容,以加深理解并拓展视野。
This concludes our comprehensive take on the tutorial on Selenium Webdriver Handling Links. We’ve started with describing how to identify links in HTML, and examples to illustrate how to handle links using the link text, partial link text, and tagname locators in Selenium Webdriver. This equips you with in-depth knowledge of the Selenium Webdriver - Handling Links. It is wise to keep practicing what you’ve learned and exploring others relevant to Selenium to deepen your understanding and expand your horizons.